

Ключевые моменты
Подходит для этих моделей ✅ LLM: Qwen 2.5 7B, Qwen 3 (0.6B–8B), Llama 3.1 8B, Llama 3.2 1B Видеомодели: HunyuanVideo (544×960), Wan T2V-1.3B, T2V-14B
Проблемы развертывания и их решения Проблемы с нагревом, питанием и размером? Мы расскажем о характеристиках БП, выборе корпуса, среде Docker и бюджетных облачных альтернативах.
Откажитесь от затрат на оборудование с Novita AI Запускайте инстансы L40S в облаке. Платите почасово. Масштабируйтесь мгновенно. Не нужно собирать собственный сервер.

Novita AI

Runpod
Стоимость использования L40S на Novita AI примерно вдвое ниже, чем на RunPod.
Запустите свой инстанс L40s GPU сейчас
Думаете, ваша модель слишком велика для одного GPU? Подумайте еще раз. NVIDIA L40S может вас удивить. С 48 ГБ видеопамяти и тензорными ядрами 4-го поколения она справляется с большим, чем вы ожидаете – включая такие модели, как Qwen 3 8B, Llama 3.1 8B и даже T2V 14B.
В этом руководстве мы подробно разберем, какие LLM и видеомодели помещаются на один L40S – чтобы вы перестали гадать и начали создавать.
Почему L40S выделяется: глубокое погружение в аппаратное обеспечение
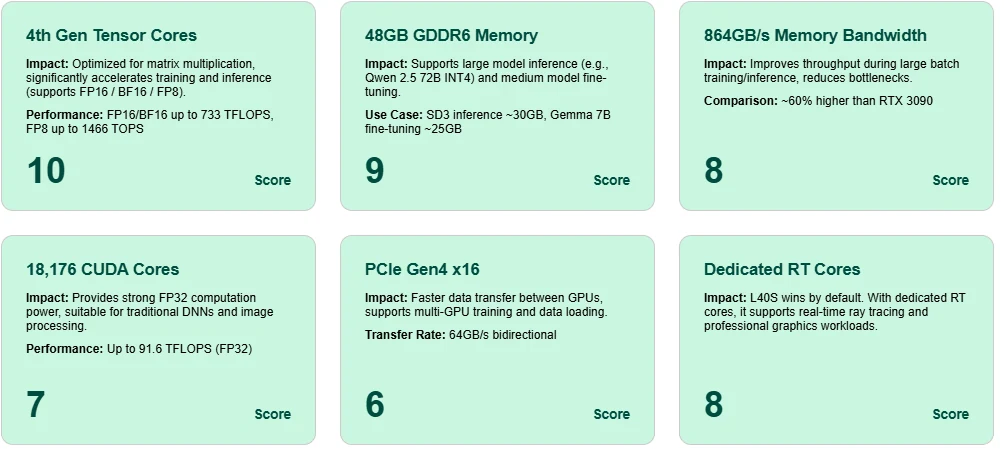
Превосходство тензорных ядер Оснащенный тензорными ядрами 4-го поколения, L40S достигает до 1466 TOPS с FP8 и 733 TFLOPS с BF16/FP16, обеспечивая высокоэффективное обучение и инференс для современных моделей ИИ.
Огромный объем памяти 48 ГБ GDDR6 Поддерживает инференс крупномасштабных моделей, таких как Qwen 2.5 72B (INT4), и тонкую настройку моделей среднего размера, например Gemma 7B – на одной карте.
Высокая пропускная способность памяти 864 ГБ/с обеспечивают быструю активацию и перемещение параметров во время обучения, снижая задержки и узкие места в сценариях с большими пакетами.
Универсальность ядер CUDA С 18 176 ядрами CUDA и 91,6 TFLOPS FP32 L40S обеспечивает надежную вычислительную мощность для традиционного глубокого обучения и обработки изображений.
Пропускная способность PCIe Gen4 x16 Обеспечивает высокоскоростную связь между GPU, что необходимо для многокарточных конфигураций при обучении или инференсе.
Выделенные RT-ядра для трассировки лучей L40S подходит не только для ИИ – благодаря встроенным RT-ядрам она также отлично справляется с графикой реального времени и задачами рендеринга.
Какие модели LLM можно запускать на одном GPU L40S?
| Модель | Параметры | Вес FP16 (оцен.) | Вердикт на одной карте |
|---|---|---|---|
| Qwen 2.5 7B | 7 B | ~14 ГБ | ✅ Подходит |
| Qwen 3 8B / 4B / 1.7B / 0.6B | ≤ 8 B | ≤ 18 ГБ | ✅ Подходит |
| Llama 3.1 8B | 8 B | ~18 ГБ | ✅ Подходит |
| Llama 3.2 1B | 1 B | ~2 ГБ | ✅ Подходит |
| Gemma 3 27B | 27 B | ~54 ГБ | ❌ Слишком большая |
| GLM-4-32B | 32 B | ~64 ГБ | ❌ Слишком большая |
| QWQ 32B | 32 B | ~65 ГБ | ❌ Слишком большая |
| Qwen 3 30B A3B | 30 B всего | ~61 ГБ* | ❌ Слишком большая |
| Llama 3.3 70B | 70 B | ~140 ГБ | ❌ Слишком большая |
| Qwen 2.5-VL 72B | 72 B | ~144 ГБ | ❌ Слишком большая |
| Llama 4 Scout / Maverick | 109 B / 400 B | ~218 ГБ / ~800 ГБ | ❌ Слишком большая |
| DeepSeek R1 / V3 | 671 B всего | ~1,34 ТБ* | ❌ Слишком большая |
| Qwen 3 235B A22B | 235 B всего | ~470 ГБ* | ❌ Слишком большая |
Какие видеомодели можно запускать на GPU L40S?
| Модель / Разрешение | Одна карта L40S (48 ГБ) |
|---|---|
| HunyuanVideo 544 × 960 | ✅ Подходит на одну карту |
| HunyuanVideo 720 × 1280 | ❌ Требуется ≥ 2 карт с NVLink |
| Wan T2V-1.3B | ✅ С большим запасом |
| Wan T2V-14B | ✅ Подходит на одну карту |
Какие препятствия возникают при развертывании NVIDIA L40S?
Препятствие: высокое энергопотребление (350–400 Вт) может перегрузить типичные блоки питания для ПК. Решение: установите блок питания ATX 3.0 / 80 Plus Gold (≥ 1000 Вт) с родным 12VHPWR или адаптерами на два 8-контактных разъема.
Препятствие: значительное тепловыделение быстро насыщает небольшие корпуса. Решение: выбирайте просторный корпус с хорошей вентиляцией или 4U-стойку, добавьте высокооборотистые вентиляторы или систему жидкостного охлаждения 240 мм и более.
Препятствие: длина и высота трехслотовой карты превышают допуски многих mid-tower корпусов. Решение: сначала измерьте; если тесно, перейдите на открытый тестовый стенд, используйте вертикальный кронштейн для GPU или корпус для рабочих станций.
Препятствие: программный стек должен быть совместим с CUDA 12+, cuDNN 9 и последними версиями ядер. Решение: изолируйте с помощью Conda или Docker-образов, зафиксированных на соответствующих версиях драйверов/CUDA; тестируйте сборки в CI перед установкой на хосте.
Препятствие: высокая начальная стоимость оборудования для индивидуальных разработчиков. Решение: прототипируйте на почасовых облачных узлах L40S (например, Novita AI) и покупайте локальное оборудование только после оценки рабочей нагрузки.
Более экономичный способ: Novita AI
Novita AI предоставляет облачную платформу с высокопроизводительными инстансами GPU. Благодаря мощным GPU платформа обеспечивает эффективную производительность для сложных задач, упрощает доступ к развертыванию на различном оборудовании и предлагает экономичное решение по сравнению с поддержкой локального оборудования для масштабных развертываний ИИ.
Шаг 1: Зарегистрируйте аккаунт
Создайте свой аккаунт Novita AI на нашем веб-сайте. После регистрации перейдите в раздел “Explore” на левой боковой панели, чтобы просмотреть предложения GPU и начать свой путь в разработке ИИ.

Шаг 2: Изучение шаблонов и GPU-серверов
Выберите из шаблонов, таких как PyTorch, TensorFlow или CUDA, которые соответствуют потребностям вашего проекта. Затем выберите предпочтительную конфигурацию GPU — доступны варианты, включая мощный L40S, RTX 4090 или A100 SXM4, каждый с разными характеристиками видеопамяти, ОЗУ и хранилища.

Шаг 3: Настройка развертывания
Настройте свою среду, выбрав предпочтительную операционную систему и параметры конфигурации, чтобы обеспечить оптимальную производительность для ваших конкретных задач ИИ и потребностей разработки.

Шаг 4: Запуск инстанса
Выберите “Launch Instance”, чтобы начать развертывание. Ваша высокопроизводительная среда GPU будет готова в течение нескольких минут, что позволит вам немедленно приступить к проектам машинного обучения, рендеринга или вычислительным задачам.
NVIDIA L40S выделяется как сбалансированный GPU, обеспечивающий мощную тензорную производительность, большой объем памяти и широкую совместимость моделей — все на одной карте. Хотя она не может запускать массивные модели, такие как Qwen 2.5 72B или DeepSeek V3, это отличный выбор для LLM среднего размера и задач с видео в реальном времени. Благодаря облачному доступу Novita AI к L40S разработчики могут использовать эту производительность без первоначальных затрат на оборудование, что делает разработку ИИ более быстрой, масштабируемой и доступной.
Часто задаваемые вопросы
Какие модели LLM можно запускать на одном L40S?
Qwen 2.5 7B Qwen 3 8B / 4B / 1.7B / 0.6B Llama 3.1 8B Llama 3.2 1B
Какие видеомодели поддерживаются?
HunyuanVideo (544×960) Wan T2V-1.3B Wan T2V-14B
Какие проблемы возникают при локальном развертывании L40S?
Стоимость → Используйте облачных провайдеров, таких как Novita AI, для недорогого прототипирования
Novita AI — это облачная платформа ИИ, которая предоставляет разработчикам простой способ развертывания моделей ИИ с помощью нашего простого API, а также предлагает доступное и надежное облако GPU для создания и масштабирования.
Рекомендуемое чтение



