

주요 하이라이트
이 모델들에 적합 ✅
LLM: Qwen 2.5 7B, Qwen 3 (0.6B–8B), Llama 3.1 8B, Llama 3.2 1B
비디오 모델: HunyuanVideo (544×960), Wan T2V-1.3B, T2V-14B
배포 시의 문제점 및 해결 방법
발열, 전력, 크기 문제? PSU 사양, 섀시 크기, Docker 환경, 예산 친화적인 클라우드 대안을 다룹니다.
Novita AI로 하드웨어 비용 절감
클라우드에서 L40S 인스턴스를 실행하세요. 시간당 요금제로 즉시 확장 가능합니다. 자체 구축 필요 없음.

Novita AI

Runpod
Novita AI에서 L40S를 사용하는 비용은 RunPod 가격의 약 절반입니다.
모델이 단일 GPU에 너무 크다고 생각하세요? 다시 생각해보세요. NVIDIA L40S는 여러분을 놀라게 할 수 있습니다. 48GB VRAM과 4세대 Tensor 코어를 갖추고 있어 Qwen 3 8B, Llama 3.1 8B, 심지어 T2V 14B 와 같은 모델을 예상보다 더 많이 처리할 수 있습니다.
이 가이드에서는 단일 L40S에 어떤 LLM 및 비디오 모델이 적합한지 정확히 분석하여 추측을 멈추고 구축을 시작할 수 있도록 도와드립니다.
L40S가 돋보이는 이유: 하드웨어 심층 분석
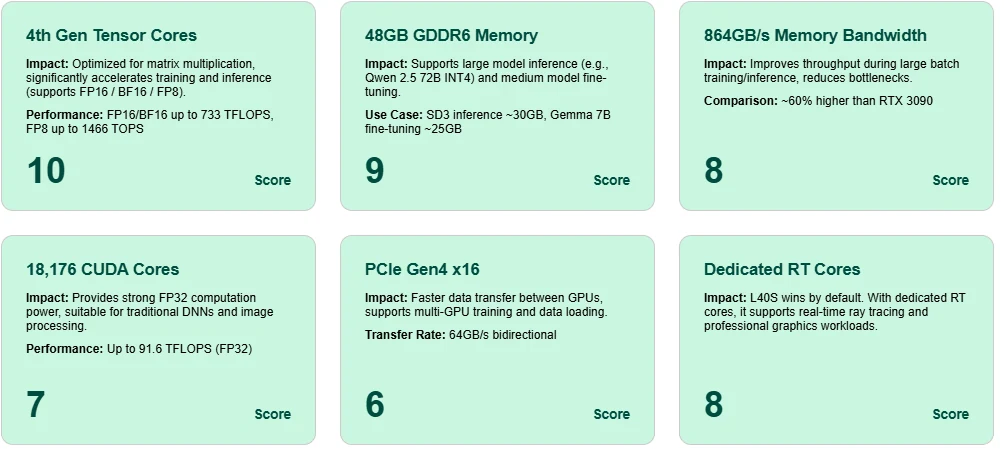
탁월한 Tensor 코어
4세대 Tensor 코어를 탑재한 L40S는 FP8에서 최대 1466 TOPS, BF16/FP16에서 733 TFLOPS를 달성하여 최신 AI 모델의 효율적인 학습과 추론을 가능하게 합니다.
대용량 48GB GDDR6 메모리
Qwen 2.5 72B(INT4)와 같은 대규모 모델의 추론과 Gemma 7B와 같은 중간 규모 모델의 파인튜닝을 단일 카드에서 지원합니다.
높은 메모리 대역폭
864GB/s 대역폭으로 학습 중 활성화 및 파라미터 이동이 빠르게 이루어져 지연 시간을 줄이고 대규모 배치 시나리오에서 병목 현상을 완화합니다.
CUDA 코어 다재다능함
18,176개의 CUDA 코어와 91.6 FP32 TFLOPS로 L40S는 기존 딥러닝 및 이미지 처리에 안정적인 컴퓨팅 성능을 제공합니다.
PCIe Gen4 x16 처리량
GPU 간 고속 통신을 가능하게 하여 다중 GPU 배포(학습 또는 추론)에 필수적입니다.
레이트레이싱 전용 RT 코어
L40S는 AI 전용이 아닙니다. 내장된 RT 코어 덕분에 실시간 그래픽 및 렌더링 작업에도 탁월합니다.
단일 L40S GPU에서 실행할 수 있는 LLM 모델
| 모델 | 매개변수 | FP16 가중치(추정) | 단일 카드 평가 |
|---|---|---|---|
| Qwen 2.5 7B | 7B | ~14GB | ✅ 적합 |
| Qwen 3 8B / 4B / 1.7B / 0.6B | ≤ 8B | ≤ 18GB | ✅ 적합 |
| Llama 3.1 8B | 8B | ~18GB | ✅ 적합 |
| Llama 3.2 1B | 1B | ~2GB | ✅ 적합 |
| Gemma 3 27B | 27B | ~54GB | ❌ 너무 큼 |
| GLM-4-32B | 32B | ~64GB | ❌ 너무 큼 |
| QWQ 32B | 32B | ~65GB | ❌ 너무 큼 |
| Qwen 3 30B A3B | 총 30B | ~61GB* | ❌ 너무 큼 |
| Llama 3.3 70B | 70B | ~140GB | ❌ 너무 큼 |
| Qwen 2.5-VL 72B | 72B | ~144GB | ❌ 너무 큼 |
| Llama 4 Scout / Maverick | 109B / 400B | ~218GB / ~800GB | ❌ 너무 큼 |
| DeepSeek R1 / V3 | 총 671B | ~1.34TB* | ❌ 훨씬 너무 큼 |
| Qwen 3 235B A22B | 총 235B | ~470GB* | ❌ 너무 큼 |
L40S GPU에서 실행할 수 있는 비디오 모델
| 모델/해상도 | 단일 카드 L40S(48GB) |
|---|---|
| HunyuanVideo 544 × 960 | ✅ 한 장의 카드에 적합 |
| HunyuanVideo 720 × 1280 | ❌ NVLink 연결 카드 2개 이상 필요 |
| Wan T2V-1.3B | ✅ 여유 공간 충분 |
| Wan T2V-14B | ✅ 한 장의 카드에 적합 |
NVIDIA L40S 배포 시 어떤 장애물이 있나요?
장애물: 높은 전력 소모(350~400W)로 일반 데스크탑 PSU에 과부하가 걸릴 수 있습니다.
해결 방법: 네이티브 12VHPWR 또는 듀얼 8핀 어댑터가 포함된 ATX 3.0/80 Plus Gold(≥1000W) 전원 공급 장치를 설치합니다.
장애물: 상당한 발열로 인해 작은 케이스가 빠르게 포화됩니다.
해결 방법: 넉넉한 공기 흐름 케이스 또는 4U 랙을 선택하고, 고RPM 팬 또는 240mm 이상의 AIO/수랭 루프를 추가합니다.
장애물: 3슬롯 길이와 높이가 많은 미드타워 간격을 초과합니다.
해결 방법: 먼저 측정하세요. 공간이 협소하면 오픈 테스트 벤치, 수직 GPU 브래킷 또는 워크스테이션 섀시로 이동합니다.
장애물: 소프트웨어 스택이 CUDA 12+, cuDNN 9 및 최신 커널을 대상으로 해야 합니다.
해결 방법: Conda 또는 Docker 이미지로 격리하고 일치하는 드라이버/CUDA 버전에 고정시킵니다. 호스트에 설치하기 전에 CI에서 빌드를 테스트합니다.
장애물: 개별 개발자에게 초기 하드웨어 비용이 높습니다.
해결 방법: 시간당 클라우드 L40S 노드(예: Novita AI)에서 프로토타입을 만든 후 워크로드 규모를 확인한 후에만 로컬로 구매합니다.
더 비용 효율적인 방법: Novita AI
Novita AI는 고성능 GPU 인스턴스를 갖춘 클라우드 기반 플랫폼을 제공합니다. 강력한 GPU를 통해 복잡한 작업에 효율적인 성능을 보장하고, 다양한 하드웨어에 배포 접근성을 높이며, 대규모 AI 배포를 위한 로컬 하드웨어 유지 관리에 비해 비용 효율적인 솔루션을 제공합니다.
Step1: 계정 등록
웹사이트를 통해 Novita AI 계정을 만드세요. 등록 후 왼쪽 사이드바의 “Explore” 섹션으로 이동하여 GPU 제공 사항을 확인하고 AI 개발 여정을 시작하세요.

Step2: 템플릿 및 GPU 서버 탐색
프로젝트 요구 사항에 맞는 PyTorch, TensorFlow 또는 CUDA와 같은 템플릿을 선택하세요. 그런 다음 원하는 GPU 구성을 선택합니다. 옵션에는 강력한 L40S, RTX 4090 또는 A100 SXM4가 있으며 각각 VRAM, RAM 및 스토리지 사양이 다릅니다.

Step3: 배포 맞춤 설정
원하는 운영 체제와 구성 옵션을 선택하여 환경을 사용자 정의하여 특정 AI 워크로드 및 개발 요구에 최적의 성능을 보장합니다.

Step4: 인스턴스 시작
"Launch Instance"를 선택하여 배포를 시작합니다. 고성능 GPU 환경이 몇 분 내에 준비되어 머신러닝, 렌더링 또는 컴퓨팅 프로젝트를 즉시 시작할 수 있습니다.
NVIDIA L40S는 강력한 텐서 성능, 대용량 메모리, 폭넓은 모델 호환성을 단일 카드로 제공하는 균형 잡힌 GPU로 두드러집니다. Qwen 2.5 72B나 DeepSeek V3와 같은 대규모 모델을 실행하지는 못할 수 있지만, 중간 범위 LLM 및 실시간 비디오 작업에 탁월한 선택입니다. Novita AI의 클라우드 기반 L40S 접근을 통해 개발자는 초기 하드웨어 비용 없이 이 성능을 활용하여 AI 개발을 더 빠르고, 확장 가능하며, 더 저렴하게 만들 수 있습니다.
자주 묻는 질문
단일 L40S에서 실행할 수 있는 LLM 모델은?
Qwen 2.5 7B
Qwen 3 8B / 4B / 1.7B / 0.6B
Llama 3.1 8B
Llama 3.2 1B
지원되는 비디오 모델은?
HunyuanVideo (544×960)
Wan T2V-1.3B
Wan T2V-14B
L40S를 로컬에 배포할 때 어떤 문제가 있나요?
**비용 ** → Novita AI와 같은 클라우드 제공업체를 사용하여 저렴하게 프로토타입 제작
Novita AI는 간단한 API를 사용하여 AI 모델을 배포할 수 있는 쉬운 방법을 개발자에게 제공하는 AI 클라우드 플랫폼이며, 구축 및 확장을 위한 저렴하고 안정적인 GPU 클라우드도 제공합니다.
추천 읽을거리



