

النقاط الرئيسية
تناسب هذه النماذج ✅
نماذج اللغات الكبيرة (LLMs): Qwen 2.5 7B، Qwen 3 (0.6B–8B)، Llama 3.1 8B، Llama 3.2 1B
نماذج الفيديو: HunyuanVideo (544×960)، Wan T2V-1.3B، T2V-14B
تحديات النشر والحلول
مشاكل الحرارة والطاقة والحجم؟ نغطي مواصفات PSU، حجم الهيكل، بيئات Docker، والبدائل السحابية الاقتصادية.
تجاوز تكاليف الأجهزة مع Novita AI
تشغيل مثيلات L40S في السحابة. الدفع بالساعة. التوسع الفوري. لا حاجة لبناء نظامك الخاص.

Novita AI

Runpod
تكلفة استخدام L40S على Novita AI تقارب نصف سعر RunPod.
أطلق مثيل L40s GPU الخاص بك الآن
هل تعتقد أن نموذجك كبير جدًا لـ GPU واحد؟ فكر مجددًا. قد يفاجئك NVIDIA L40S. بذاكرة VRAM سعة 48GB وTensor Cores من الجيل الرابع، يمكنه التعامل مع أكثر مما تتوقع—بما في ذلك نماذج مثل Qwen 3 8B و Llama 3.1 8B وحتى T2V 14B.
في هذا الدليل، نوضح بالتفصيل أي نماذج اللغات الكبيرة والفيديو تناسب L40S واحد—لتتوقف عن التخمين وتبدأ البناء.
لماذا يتميز L40S: نظرة معمقة على الأجهزة
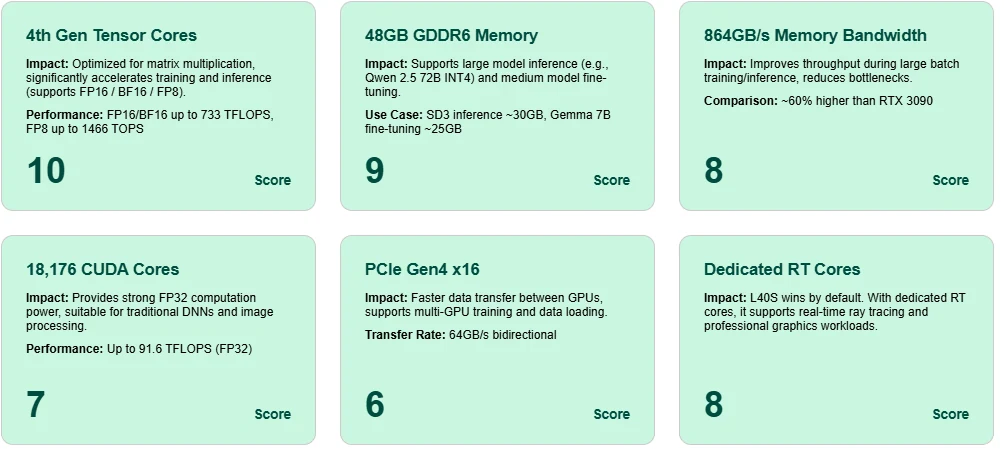
تميز Tensor Core
مزود بـ Tensor Cores من الجيل الرابع، يحقق L40S أداءً يصل إلى 1466 TOPS مع FP8 و733 TFLOPS مع BF16/FP16، مما يتيح تدريبًا واستدلالًا عالي الكفاءة لنماذج AI الحديثة.
ذاكرة GDDR6 ضخمة بسعة 48GB
يدعم استدلال النماذج واسعة النطاق مثل Qwen 2.5 72B (INT4) والضبط الدقيق للنماذج المتوسطة مثل Gemma 7B—كل ذلك على بطاقة واحدة.
عرض نطاق ذاكرة عالي
يمنحك عرض نطاق 864GB/s حركة سريعة للتفعيل والبارامترات أثناء التدريب، مما يقلل من زمن الوصول والاختناقات في سيناريوهات الدفعات الكبيرة.
تنوع أنوية CUDA
مع 18,176 نواة CUDA و91.6 FP32 TFLOPS، يوفر L40S قوة حوسبة موثوقة للتعلم العميق التقليدي ومعالجة الصور.
إنتاجية PCIe Gen4 x16
يمكّن من الاتصال عالي السرعة بين GPUs، وهو ضروري لنشر متعدد GPUs في التدريب أو الاستدلال.
أنوية RT مخصصة لتتبع الأشعة
L40S ليس فقط للـ AI—بل يتفوق أيضًا في الرسوميات في الوقت الفعلي ومهام التصيير، بفضل أنوية RT المدمجة.
أي نماذج اللغات الكبيرة يمكن تشغيلها على GPU L40S واحد؟
| النموذج | المعلمات | أوزان FP16 (تقديري) | حكم البطاقة الواحدة |
|---|---|---|---|
| Qwen 2.5 7B | 7 B | ~14 GB | ✅ مناسب |
| Qwen 3 8B / 4B / 1.7B / 0.6B | ≤ 8 B | ≤ 18 GB | ✅ مناسب |
| Llama 3.1 8B | 8 B | ~18 GB | ✅ مناسب |
| Llama 3.2 1B | 1 B | ~2 GB | ✅ مناسب |
| Gemma 3 27B | 27 B | ~54 GB | ❌ كبير جدًا |
| GLM-4-32B | 32 B | ~64 GB | ❌ كبير جدًا |
| QWQ 32B | 32 B | ~65 GB | ❌ كبير جدًا |
| Qwen 3 30B A3B | 30 B إجمالي | ~61 GB* | ❌ كبير جدًا |
| Llama 3.3 70B | 70 B | ~140 GB | ❌ كبير جدًا |
| Qwen 2.5-VL 72B | 72 B | ~144 GB | ❌ كبير جدًا |
| Llama 4 Scout / Maverick | 109 B / 400 B | ~218 GB / ~800 GB | ❌ كبير جدًا |
| DeepSeek R1 / V3** | 671 B إجمالي | ~1.34 TB* | ❌ كبير جدًا جدًا |
| Qwen 3 235B A22B | 235 B إجمالي | ~470 GB* | ❌ كبير جدًا |
أي نماذج الفيديو يمكن تشغيلها على GPU L40S؟
| النموذج / الدقة | بطاقة L40S واحدة (48 GB) |
|---|---|
| HunyuanVideo 544 × 960 | ✅ يناسب بطاقة واحدة |
| HunyuanVideo 720 × 1280 | ❌ يحتاج ≥ 2 بطاقة مرتبطة بـ NVLink |
| Wan T2V-1.3B | ✅ مساحة كبيرة متبقية |
| Wan T2V-14B | ✅ يناسب بطاقة واحدة |
ما العقبات عند نشر NVIDIA L40S GPU؟
العقبة: استهلاك طاقة عالي (350 – 400 واط) قد يثقل مزودات الطاقة المكتبية النموذجية.
الحل: تركيب مزود ATX 3.0 / 80 Plus Gold (≥ 1000 واط) يتضمن محول 12VHPWR أصلي أو محولات ثنائية 8-pin.
العقبة: خرج حراري كبير يشبع بسرعة الحالات الصغيرة.
الحل: اختر هيكلًا واسعًا لتدفق الهواء أو رف 4U، أضف مراوح عالية السرعة أو نظام تبريد مائي 240 مم+.
العقبة: طول وارتفاع ثلاث فتحات يتجاوز خلوص العديد من الأبراج المتوسطة.
الحل: قس المساحة أولاً؛ إذا كان ضيقًا، انتقل إلى طاولة اختبار مفتوحة، أو حامل GPU عمودي، أو هيكل محطة عمل.
العقبة: مجموعات البرامج يجب أن تستهدف CUDA 12+ و cuDNN 9 ونواة حديثة.
الحل: اعزل باستخدام Conda أو حاويات Docker مثبتة على إصدارات متطابقة من برنامج التشغيل/CUDA؛ اختبر البناءات في CI قبل التثبيت على المضيف.
العقبة: التكلفة المبدئية للأجهزة مرتفعة للمطورين الأفراد.
الحل: نمذجة أولية على عقد L40S سحابية بالساعة (مثل Novita AI) واشترِ محليًا فقط بعد تقدير حجم العمل.
طريقة أكثر فعالية من حيث التكلفة: Novita AI
توفر Novita AI منصة سحابية بمثيلات GPU عالية الأداء. مع GPUs القوية، تضمن أداءً فعالًا للمهام المعقدة، وتعزز إمكانية الوصول للنشر على أجهزة متنوعة، وتقدم حلاً فعالاً من حيث التكلفة مقارنة بصيانة الأجهزة المحلية لنشر AI على نطاق واسع.
الخطوة 1: إنشاء حساب
أنشئ حساب Novita AI الخاص بك عبر موقعنا. بعد التسجيل، انتقل إلى قسم “Explore” في الشريط الجانبي الأيسر لعرض عروض GPU وبدء رحلة تطوير AI الخاصة بك.

الخطوة 2: استكشاف القوالب وخوادم GPU
اختر من بين قوالب مثل PyTorch أو TensorFlow أو CUDA التي تناسب احتياجات مشروعك. ثم حدد تكوين GPU المفضل لديك—تشمل الخيارات L40S القوي، RTX 4090 أو A100 SXM4، كل منها بمواصفات مختلفة من VRAM وRAM والتخزين.

الخطوة 3: تخصيص النشر
خصص بيئتك باختيار نظام التشغيل المفضل وخيارات التكوين لضمان الأداء الأمثل لأعباء عمل AI الخاصة واحتياجات التطوير.

الخطوة 4: إطلاق مثيل
اختر “Launch Instance” لبدء النشر. ستكون بيئة GPU عالية الأداء جاهزة خلال دقائق، مما يتيح لك البدء فورًا في مشاريع التعلم الآلي أو التصيير أو الحوسبة.

يبرز NVIDIA L40S كـ GPU متوازن، يقدم أداء tensor قويًا، وسعة ذاكرة كبيرة، وتوافقًا واسعًا مع النماذج—كل ذلك على بطاقة واحدة. بينما قد لا يشغل نماذج ضخمة مثل Qwen 2.5 72B أو DeepSeek V3، فهو خيار ممتاز لنماذج اللغات المتوسطة ومهام الفيديو في الوقت الفعلي. مع وصول Novita AI السحابي إلى L40S، يمكن للمطورين الاستفادة من هذا الأداء دون تكاليف الأجهزة المبدئية، مما يجعل تطوير AI أسرع وقابلًا للتوسع وأكثر اقتصادية.
الأسئلة الشائعة
أي نماذج اللغات الكبيرة يمكن تشغيلها على L40S واحد؟
Qwen 2.5 7B
Qwen 3 8B / 4B / 1.7B / 0.6B
Llama 3.1 8B
Llama 3.2 1B
ما نماذج الفيديو المدعومة؟
HunyuanVideo (544×960)
Wan T2V-1.3B
Wan T2V-14B
ما التحديات عند نشر L40S محليًا؟
التكلفة → استخدم مزودي السحابة مثل Novita AI للنمذجة الأولية بتكلفة معقولة
Novita AI هي منصة سحابية للـ AI تقدم للمطورين طريقة سهلة لنشر نماذج AI باستخدام API بسيط، مع توفير سحابة GPU ميسورة التكلفة وموثوقة للبناء والتوسع.
قراءات مقترحة



