

Puntos clave
Adecuado para estos modelos ✅
LLMs: Qwen 2.5 7B, Qwen 3 (0.6B–8B), Llama 3.1 8B, Llama 3.2 1B
Modelos de vídeo: HunyuanVideo (544×960), Wan T2V-1.3B, T2V-14B
Desafíos de despliegue y soluciones
¿Problemas de calor, energía y tamaño? Te explicamos las especificaciones de la fuente de alimentación, el tamaño del chasis, los entornos Docker y las alternativas económicas en la nube.
Evita los costos de hardware con Novita AI
Lanza instancias L40S en la nube. Paga por hora. Escala al instante. No necesitas montar tu propio equipo.

Novita AI

Runpod
El costo de usar L40S en Novita AI es aproximadamente la mitad del precio de RunPod.
Lanza tu instancia de GPU L40S ahora
¿Crees que tu modelo es demasiado grande para una sola GPU? Piénsalo de nuevo. La NVIDIA L40S puede sorprenderte. Con 48 GB de VRAM y Tensor Cores de 4.ª generación, es capaz de manejar más de lo que esperas, incluidos modelos como Qwen 3 8B, Llama 3.1 8B e incluso T2V 14B.
En esta guía, desglosamos exactamente qué LLMs y modelos de vídeo caben en una sola L40S, para que dejes de hacer suposiciones y empieces a construir.
Por qué destaca la L40S: un análisis técnico en profundidad
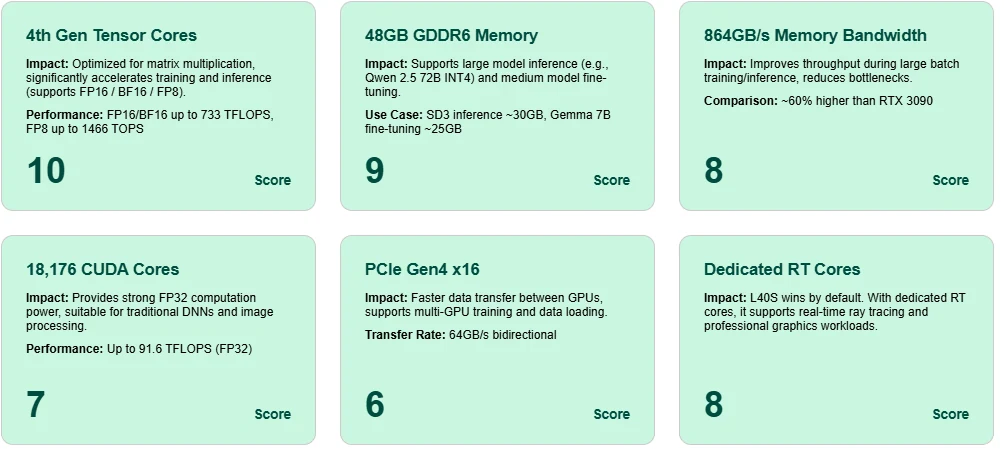
Excelencia en Tensor Cores
Equipada con Tensor Cores de 4.ª generación, la L40S alcanza hasta 1466 TOPS con FP8 y 733 TFLOPS con BF16/FP16, lo que permite un entrenamiento e inferencia altamente eficientes para modelos modernos de IA.
Memoria GDDR6 masiva de 48 GB
Admite la inferencia de modelos a gran escala como Qwen 2.5 72B (INT4) y el ajuste fino de modelos de tamaño medio como Gemma 7B, todo en una sola tarjeta.
Alto ancho de banda de memoria
Los 864 GB/s de ancho de banda garantizan una rápida activación y movimiento de parámetros durante el entrenamiento, reduciendo la latencia y los cuellos de botella en escenarios de lotes grandes.
Versatilidad de los núcleos CUDA
Con 18 176 núcleos CUDA y 91.6 FP32 TFLOPS, la L40S ofrece potencia de cálculo fiable para el aprendizaje profundo convencional y el procesamiento de imágenes.
Rendimiento PCIe Gen4 x16
Permite una comunicación de alta velocidad entre GPUs, esencial para despliegues multi-GPU en entrenamiento o inferencia.
Núcleos RT dedicados para trazado de rayos
La L40S no es solo para IA: también destaca en gráficos en tiempo real y tareas de renderizado, gracias a sus núcleos RT integrados.
¿Qué modelos LLM se pueden ejecutar en una sola GPU L40S?
| Modelo | Parámetros | Peso FP16 (estimado) | Veredicto en una tarjeta |
|---|---|---|---|
| Qwen 2.5 7B | 7 B | ~14 GB | ✅ Cabe |
| Qwen 3 8B / 4B / 1.7B / 0.6B | ≤ 8 B | ≤ 18 GB | ✅ Cabe |
| Llama 3.1 8B | 8 B | ~18 GB | ✅ Cabe |
| Llama 3.2 1B | 1 B | ~2 GB | ✅ Cabe |
| Gemma 3 27B | 27 B | ~54 GB | ❌ Demasiado grande |
| GLM-4-32B | 32 B | ~64 GB | ❌ Demasiado grande |
| QWQ 32B | 32 B | ~65 GB | ❌ Demasiado grande |
| Qwen 3 30B A3B | 30 B total | ~61 GB* | ❌ Demasiado grande |
| Llama 3.3 70B | 70 B | ~140 GB | ❌ Demasiado grande |
| Qwen 2.5-VL 72B | 72 B | ~144 GB | ❌ Demasiado grande |
| Llama 4 Scout / Maverick | 109 B / 400 B | ~218 GB / ~800 GB | ❌ Demasiado grande |
| DeepSeek R1 / V3 | 671 B total | ~1.34 TB* | ❌ Demasiado grande |
| Qwen 3 235B A22B | 235 B total | ~470 GB* | ❌ Demasiado grande |
¿Qué modelos de vídeo se pueden ejecutar en GPU L40S?
| Modelo / Resolución | Una sola tarjeta L40S (48 GB) |
|---|---|
| HunyuanVideo 544 × 960 | ✅ Cabe en una tarjeta |
| HunyuanVideo 720 × 1280 | ❌ Necesita ≥ 2 tarjetas enlazadas con NVLink |
| Wan T2V-1.3B | ✅ Con mucho margen |
| Wan T2V-14B | ✅ Cabe en una tarjeta |
¿Qué obstáculos hay al desplegar una GPU NVIDIA L40S?
Obstáculo: El alto consumo de energía (350 – 400 W) puede sobrecargar las fuentes de alimentación de escritorio típicas.
Solución: Instala una fuente ATX 3.0 / 80 Plus Gold (≥ 1000 W) que incluya un conector nativo 12VHPWR o adaptadores de doble 8 pines.
Obstáculo: La importante producción de calor satura rápidamente las cajas pequeñas.
Solución: Elige un chasis espacioso con buena ventilación o un rack 4U, añade ventiladores de altas RPM o un AIO/refrigeración líquida de 240 mm o más.
Obstáculo: La longitud y altura de tres ranuras superan las holguras de muchas torres medianas.
Solución: Mide primero; si está ajustado, pasa a un banco de pruebas abierto, un soporte vertical para GPU o un chasis de estación de trabajo.
Obstáculo: Las pilas de software deben apuntar a CUDA 12+, cuDNN 9 y kernels recientes.
Solución: Aísla con Conda o imágenes Docker fijadas a versiones de controlador/CUDA compatibles; prueba las compilaciones en CI antes de instalarlas en el anfitrión.
Obstáculo: El costo inicial del hardware es alto para desarrolladores individuales.
Solución: Haz prototipos en nodos L40S en la nube por horas (por ejemplo, Novita AI) y compra localmente solo después de dimensionar la carga de trabajo.
Una forma más rentable: Novita AI
Novita AI ofrece una plataforma en la nube con instancias GPU de alto rendimiento. Con potentes GPUs, garantiza un rendimiento eficiente para tareas complejas, facilita la accesibilidad para el despliegue en diversos hardware y ofrece una solución rentable en comparación con el mantenimiento de hardware local para despliegues de IA a gran escala.
Paso 1: Registra una cuenta
Crea tu cuenta de Novita AI a través de nuestro sitio web. Tras registrarte, navega hasta la sección “Explorar” en la barra lateral izquierda para ver nuestras ofertas de GPU y comenzar tu viaje en el desarrollo de IA.

Paso 2: Explora plantillas y servidores GPU
Elige entre plantillas como PyTorch, TensorFlow o CUDA que se ajusten a las necesidades de tu proyecto. Luego selecciona la configuración de GPU que prefieras: opciones que incluyen la potente L40S, RTX 4090 o A100 SXM4, cada una con diferentes especificaciones de VRAM, RAM y almacenamiento.

Paso 3: Personaliza tu despliegue
Personaliza tu entorno seleccionando tu sistema operativo preferido y las opciones de configuración para garantizar un rendimiento óptimo para tus cargas de trabajo específicas de IA y necesidades de desarrollo.

Paso 4: Lanza una instancia
Selecciona “Lanzar instancia” para iniciar tu despliegue. Tu entorno GPU de alto rendimiento estará listo en cuestión de minutos, permitiéndote comenzar de inmediato tus proyectos de aprendizaje automático, renderizado o computacionales.
La NVIDIA L40S destaca como una GPU equilibrada, que ofrece un potente rendimiento tensor, una gran capacidad de memoria y una amplia compatibilidad con modelos, todo en una sola tarjeta. Aunque no puede ejecutar modelos masivos como Qwen 2.5 72B o DeepSeek V3, es una excelente opción para LLMs de gama media y tareas de vídeo en tiempo real. Con el acceso basado en la nube de Novita AI a L40S, los desarrolladores pueden aprovechar este rendimiento sin los costos iniciales de hardware, haciendo que el desarrollo de IA sea más rápido, escalable y asequible.
Preguntas frecuentes
¿Qué modelos LLM se pueden ejecutar en una sola L40S?
Qwen 2.5 7B
Qwen 3 8B / 4B / 1.7B / 0.6B
Llama 3.1 8B
Llama 3.2 1B
¿Qué modelos de vídeo son compatibles?
HunyuanVideo (544×960)
Wan T2V-1.3B
Wan T2V-14B
¿Qué desafíos existen al desplegar L40S localmente?
Costo → Usa proveedores en la nube como Novita AI para hacer prototipos de forma asequible.
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de desplegar modelos de IA mediante nuestra API simple, al mismo tiempo que proporciona la nube GPU asequible y fiable para construir y escalar.
Lecturas recomendadas



