

重點摘要
適合這些模型 ✅
LLM: Qwen 2.5 7B、Qwen 3(0.6B–8B)、Llama 3.1 8B、Llama 3.2 1B
影片模型: HunyuanVideo(544×960)、Wan T2V-1.3B、T2V-14B
部署挑戰與解決方案
散熱、電源與尺寸問題?我們涵蓋電源供應器規格、機箱大小、Docker 環境以及預算友善的雲端替代方案。
透過 Novita AI 省下硬體成本
在雲端啟動 L40S 實例。按小時計費。即時擴展。無需自建主機。

Novita AI

Runpod
在 Novita AI 上使用 L40S 的成本約為 RunPod 的一半。
覺得您的模型太大,單一 GPU 跑不動?再想想。 NVIDIA L40S 可能會讓您大吃一驚。憑藉 48GB VRAM 與第 4 代 Tensor Core,它能處理比您預期更多的模型——包括 Qwen 3 8B、Llama 3.1 8B,甚至 T2V 14B。
在本指南中,我們將精確剖析 哪些 LLM 與影片模型 能裝進單張 L40S——讓您無需再猜測,直接開始建構。
為什麼 L40S 與眾不同:硬體深度解析
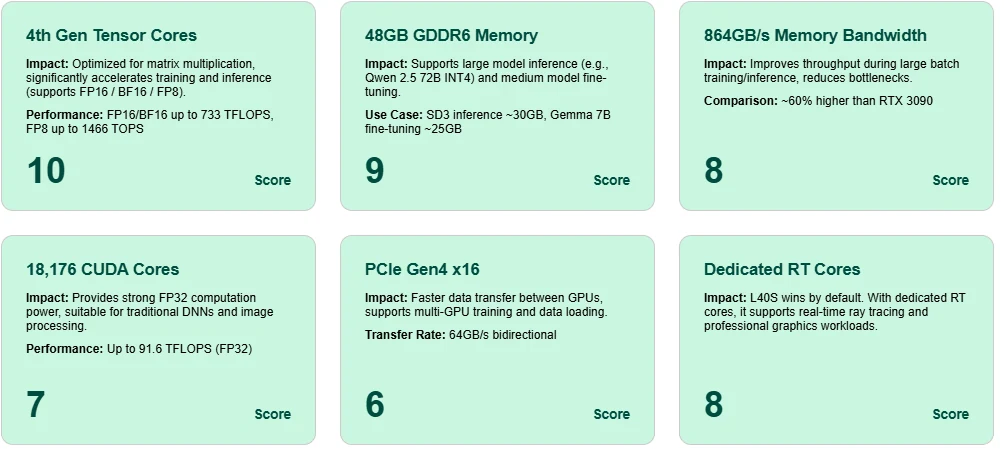
Tensor Core 卓越性能
配備第 4 代 Tensor Core,L40S 在 FP8 下可達 1466 TOPS,在 BF16/FP16 下可達 733 TFLOPS,為現代 AI 模型提供高效率的訓練與推理。
巨量 48GB GDDR6 記憶體
支援在單卡上對 Qwen 2.5 72B(INT4)等大型模型進行推理,並可微調 Gemma 7B 等中型模型。
高記憶體頻寬
864GB/s 頻寬確保訓練期間的快速激活與參數移動,減少大批量場景下的延遲與瓶頸。
CUDA Core 多樣性
擁有 18,176 個 CUDA Core 與 91.6 FP32 TFLOPS,L40S 為傳統深度學習與影像處理提供可靠的運算能力。
PCIe Gen4 x16 吞吐量
支援 GPU 間高速通訊,對於多 GPU 訓練或推理部署至關重要。
專用 RT Core 光線追蹤
L40S 不僅適用於 AI——得益於內建 RT Core,它在即時圖形與渲染任務中也表現出色。
哪些 LLM 模型可在單張 L40S GPU 上執行?
| 模型 | 參數 | FP16 權重(估算) | 單卡結論 |
|---|---|---|---|
| Qwen 2.5 7B | 7 B | ~14 GB | ✅ 符合 |
| Qwen 3 8B / 4B / 1.7B / 0.6B | ≤ 8 B | ≤ 18 GB | ✅ 符合 |
| Llama 3.1 8B | 8 B | ~18 GB | ✅ 符合 |
| Llama 3.2 1B | 1 B | ~2 GB | ✅ 符合 |
| Gemma 3 27B | 27 B | ~54 GB | ❌ 太大 |
| GLM-4-32B | 32 B | ~64 GB | ❌ 太大 |
| QWQ 32B | 32 B | ~65 GB | ❌ 太大 |
| Qwen 3 30B A3B | 30 B 總計 | ~61 GB* | ❌ 太大 |
| Llama 3.3 70B | 70 B | ~140 GB | ❌ 太大 |
| Qwen 2.5-VL 72B | 72 B | ~144 GB | ❌ 太大 |
| Llama 4 Scout / Maverick | 109 B / 400 B | ~218 GB / ~800 GB | ❌ 太大 |
| DeepSeek R1 / V3 | 671 B 總計 | ~1.34 TB* | ❌ 太大 |
| Qwen 3 235B A22B | 235 B 總計 | ~470 GB* | ❌ 太大 |
哪些影片模型可在 L40S GPU 上執行?
| 模型 / 解析度 | 單卡 L40S(48 GB) |
|---|---|
| HunyuanVideo 544 × 960 | ✅ 單卡符合 |
| HunyuanVideo 720 × 1280 | ❌ 需要 ≥ 2 張具 NVLink 連結的卡 |
| Wan T2V-1.3B | ✅ 空間充足 |
| Wan T2V-14B | ✅ 單卡符合 |
部署 NVIDIA L40S GPU 時會遇到哪些障礙?
障礙:高功耗(350 – 400 W)可能使一般桌上型電源供應器過載。
解決方案: 安裝 ATX 3.0 / 80 Plus Gold(≥ 1000 W)電源供應器,並配備原生 12VHPWR 或雙 8-pin 轉接頭。
障礙:大量廢熱會迅速使小型機箱飽和。
解決方案: 選擇通風良好的機箱或 4U 機架,並加裝高轉速風扇或 240 mm 以上的水冷系統。
障礙:三槽長度與高度超過許多中塔機箱的空間限制。
解決方案: 先測量;若空間不足,可改用開放式測試平台、垂直 GPU 支架或工作站機箱。
障礙:軟體堆疊必須針對 CUDA 12+、cuDNN 9 及較新的核心進行設定。
解決方案: 使用 Conda 或 Docker 映像隔離環境,並鎖定相符的驅動程式 / CUDA 版本;在 CI 中測試建置後再安裝至主機。
障礙:對個人開發者而言,初始硬體成本較高。
解決方案: 先在按小時計費的雲端 L40S 節點上進行原型開發(例如 Novita AI),待確認工作負載後再購買本地硬體。
更具成本效益的方式:Novita AI
Novita AI 提供基於雲端的高效能 GPU 實例平台。憑藉強大的 GPU,它能確保複雜任務的高效執行,提升跨不同硬體部署的可用性,並相較於維護本地大型 AI 部署的硬體,提供更具成本效益的解決方案。
步驟 1:註冊帳戶
透過我們的網站建立您的 Novita AI 帳戶。註冊後,點擊左側邊欄的「探索」區塊,即可查看我們的 GPU 方案,開始您的 AI 開發之旅。

步驟 2:探索範本與 GPU 伺服器
從 PyTorch、TensorFlow 或 CUDA 等符合您專案需求的範本中選擇。接著選取您偏好的 GPU 配置——選項包括強大的 L40S、RTX 4090 或 A100 SXM4,各配備不同的 VRAM、RAM 與儲存規格。

步驟 3:自訂部署
透過選擇偏好的作業系統與配置選項,自訂您的環境,確保特定 AI 工作負載與開發需求的最佳效能。

步驟 4:啟動實例
點選「啟動實例」開始部署。高效能 GPU 環境將在數分鐘內準備就緒,讓您能立即開始機器學習、渲染或運算專案。
NVIDIA L40S 是一款均衡的 GPU,能在單卡上提供強大的 Tensor 效能、大容量記憶體與廣泛的模型相容性。雖然它無法執行 Qwen 2.5 72B 或 DeepSeek V3 等大型模型,但對於中階 LLM 與即時影片任務而言,是絕佳選擇。透過 Novita AI 的雲端 L40S 服務,開發者無需前期硬體成本即可獲得此效能,使 AI 開發更快速、可擴展且更經濟實惠。
常見問題
哪些 LLM 模型可以在單張 L40S 上執行?
Qwen 2.5 7B
Qwen 3 8B / 4B / 1.7B / 0.6B
Llama 3.1 8B
Llama 3.2 1B
支援哪些影片模型?
HunyuanVideo(544×960)
Wan T2V-1.3B
Wan T2V-14B
在本地部署 L40S 時會遇到哪些挑戰?
**成本 ** → 使用 Novita AI 等雲端供應商以經濟方式進行原型開發
Novita AI 是一個 AI 雲端平台,為開發者提供透過簡單 API 部署 AI 模型的簡易方式,同時提供價格合理且可靠的 GPU 雲端服務,用於建置與擴展。
推薦閱讀



