

- Warum L40S heraussticht: Ein tiefer Einblick in die Hardware
- Welche LLM-Modelle können auf einer einzelnen L40S GPU ausgeführt werden?
- Welche Videomodelle können auf der L40S GPU ausgeführt werden?
- Welche Hindernisse gibt es bei der Bereitstellung einer NVIDIA L40S GPU?
- Ein kostengünstigerer Weg: Novita AI
Wichtige Highlights
Diese Modelle passen ✅
LLMs: Qwen 2.5 7B, Qwen 3 (0.6B–8B), Llama 3.1 8B, Llama 3.2 1B
Videomodelle: HunyuanVideo (544×960), Wan T2V-1.3B, T2V-14B
Herausforderungen bei der Bereitstellung & Lösungen
Probleme mit Hitze, Strom und Größe? Wir behandeln Netzteilspezifikationen, Gehäusegrößen, Docker-Umgebungen und budgetfreundliche Cloud-Alternativen.
Hardware-Kosten mit Novita AI umgehen
Starten Sie L40S-Instanzen in der Cloud. Bezahlen Sie stundenweise. Skalieren Sie sofort. Kein eigener Aufbau nötig.

Novita AI

Runpod
Die Kosten für die Nutzung von L40S auf Novita AI betragen etwa die Hälfte des Preises von RunPod.
Jetzt Ihre L40s GPU-Instanz starten
Denken Sie, Ihr Modell ist zu groß für eine einzelne GPU? Denken Sie nochmal. Die NVIDIA L40S könnte Sie überraschen. Mit 48 GB VRAM und Tensor Cores der 4. Generation kann sie mehr bewältigen, als Sie erwarten – einschließlich Modellen wie Qwen 3 8B, Llama 3.1 8B und sogar T2V 14B.
In diesem Leitfaden zeigen wir genau, welche LLMs und Videomodelle auf eine einzelne L40S passen – damit Sie aufhören zu raten und mit dem Bauen beginnen können.
Warum L40S heraussticht: Ein tiefer Einblick in die Hardware
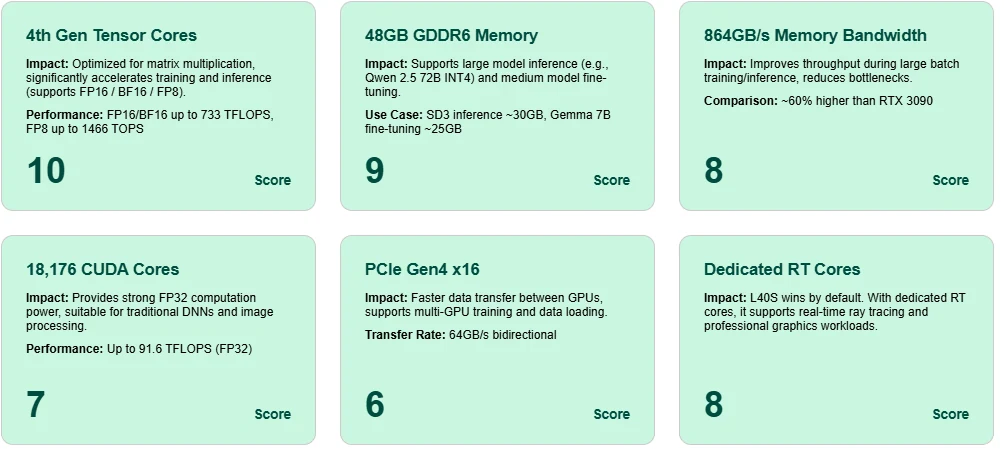
Tensor Core Exzellenz
Ausgestattet mit Tensor Cores der 4. Generation erreicht die L40S bis zu 1466 TOPS mit FP8 und 733 TFLOPS mit BF16/FP16, was ein hoch effizientes Training und Inferenz für moderne KI-Modelle ermöglicht.
Massive 48 GB GDDR6-Speicher
Unterstützt Inferenz von großen Modellen wie Qwen 2.5 72B (INT4) und Feintuning von mittelgroßen Modellen wie Gemma 7B – alles auf einer einzigen Karte.
Hohe Speicherbandbreite
864 GB/s Bandbreite gewährleistet schnelle Aktivierungen und Parameterbewegungen während des Trainings, reduziert Latenz und Engpässe in Szenarien mit großen Batches.
Vielseitigkeit der CUDA Cores
Mit 18.176 CUDA Cores und 91,6 FP32 TFLOPS liefert die L40S zuverlässige Rechenleistung für konventionelles Deep Learning und Bildverarbeitung.
PCIe Gen4 x16 Durchsatz
Ermöglicht eine schnelle Kommunikation zwischen GPUs, die für Multi-GPU-Bereitstellungen im Training oder Inferenz unerlässlich ist.
Dedizierte RT Cores für Raytracing
Die L40S ist nicht nur für KI geeignet – sie zeichnet sich auch in Echtzeitgrafik- und Rendering-Aufgaben aus, dank ihrer integrierten RT Cores.
Welche LLM-Modelle können auf einer einzelnen L40S GPU ausgeführt werden?
| Modell | Parameter | FP16-Gewichte (geschätzt) | Ein-Karten-Urteil |
|---|---|---|---|
| Qwen 2.5 7B | 7 B | ~14 GB | ✅ Passt |
| Qwen 3 8B / 4B / 1.7B / 0.6B | ≤ 8 B | ≤ 18 GB | ✅ Passt |
| Llama 3.1 8B | 8 B | ~18 GB | ✅ Passt |
| Llama 3.2 1B | 1 B | ~2 GB | ✅ Passt |
| Gemma 3 27B | 27 B | ~54 GB | ❌ Zu groß |
| GLM-4-32B | 32 B | ~64 GB | ❌ Zu groß |
| QWQ 32B | 32 B | ~65 GB | ❌ Zu groß |
| Qwen 3 30B A3B | 30 B insgesamt | ~61 GB* | ❌ Zu groß |
| Llama 3.3 70B | 70 B | ~140 GB | ❌ Zu groß |
| Qwen 2.5-VL 72B | 72 B | ~144 GB | ❌ Zu groß |
| Llama 4 Scout / Maverick | 109 B / 400 B | ~218 GB / ~800 GB | ❌ Zu groß |
| DeepSeek R1 / V3 | 671 B insgesamt | ~1,34 TB* | ❌ Viel zu groß |
| Qwen 3 235B A22B | 235 B insgesamt | ~470 GB* | ❌ Zu groß |
Welche Videomodelle können auf der L40S GPU ausgeführt werden?
| Modell / Auflösung | Ein-Karten-L40 S (48 GB) |
|---|---|
| HunyuanVideo 544 × 960 | ✅ Passt auf eine Karte |
| HunyuanVideo 720 × 1280 | ❌ Erfordert ≥ 2 NVLink-verbundene Karten |
| Wan T2V-1.3B | ✅ Ausreichend Spielraum |
| Wan T2V-14B | ✅ Passt auf eine Karte |
Welche Hindernisse gibt es bei der Bereitstellung einer NVIDIA L40S GPU?
Hindernis: Hohe Leistungsaufnahme (350–400 W) kann typische Desktop-Netzteile überlasten.
Lösung: Installieren Sie ein ATX 3.0 / 80 Plus Gold (≥ 1000 W) Netzteil mit nativen 12VHPWR- oder Dual 8-Pin-Adaptern.
Hindernis: Erhebliche Wärmeabgabe sättigt schnell kleine Gehäuse.
Lösung: Wählen Sie ein geräumiges Gehäuse mit gutem Luftstrom oder ein 4U-Rack, fügen Sie hochtourige Lüfter oder eine 240 mm+ AIO/Wasserkühlung hinzu.
Hindernis: Dreifach-Slot-Länge und -Höhe überschreiten die Abmessungen vieler Mid-Tower-Gehäuse.
Lösung: Messen Sie zuerst; wenn es knapp wird, wechseln Sie zu einem offenen Teststand, vertikalen GPU-Halter oder Workstation-Gehäuse.
Hindernis: Software-Stacks müssen auf CUDA 12+, cuDNN 9 und aktuelle Kernel abzielen.
Lösung: Isolieren Sie mit Conda- oder Docker-Images, die auf passende Treiber-/CUDA-Versionen festgelegt sind; testen Sie Builds in CI vor der Host-Installation.
Hindernis: Die anfänglichen Hardwarekosten sind für einzelne Entwickler hoch.
Lösung: Prototyp auf stündlichen Cloud-L40S-Knoten (z. B. Novita AI) und nur lokal kaufen, nachdem die Arbeitslast dimensioniert wurde.
Ein kostengünstigerer Weg: Novita AI
Novita AI bietet eine Cloud-basierte Plattform mit leistungsstarken GPU-Instanzen. Mit leistungsstarken GPUs gewährleistet sie eine effiziente Leistung für komplexe Aufgaben, verbessert die Zugänglichkeit für die Bereitstellung auf verschiedenen Hardwareplattformen und bietet eine kostengünstige Lösung im Vergleich zur lokalen Hardwarewartung für groß angelegte KI-Bereitstellungen.
Schritt 1: Registrieren Sie ein Konto
Erstellen Sie Ihr Novita AI-Konto über unsere Website. Navigieren Sie nach der Registrierung im linken Seitenmenü zum Bereich „Explore“, um unsere GPU-Angebote zu sehen und Ihre KI-Entwicklungsreise zu beginnen.

Schritt 2: Vorlagen und GPU-Server erkunden
Wählen Sie aus Vorlagen wie PyTorch, TensorFlow oder CUDA, die Ihren Projektanforderungen entsprechen. Wählen Sie dann Ihre bevorzugte GPU-Konfiguration – Optionen umfassen die leistungsstarke L40S, RTX 4090 oder A100 SXM4, jeweils mit unterschiedlichen VRAM-, RAM- und Spezifikationen.

Schritt 3: Passen Sie Ihre Bereitstellung an
Passen Sie Ihre Umgebung an, indem Sie Ihr bevorzugtes Betriebssystem und Konfigurationsoptionen auswählen, um eine optimale Leistung für Ihre spezifischen KI-Workloads und Entwicklungsanforderungen sicherzustellen.

Schritt 4: Starten Sie eine Instanz
Wählen Sie „Instanz starten“, um Ihre Bereitstellung zu beginnen. Ihre leistungsstarke GPU-Umgebung wird innerhalb von Minuten bereit sein, sodass Sie sofort mit Ihren Machine Learning-, Rendering- oder Rechenprojekten beginnen können.
Die NVIDIA L40S zeichnet sich als ausgewogene GPU aus, die leistungsstarke Tensor-Leistung, große Speicherkapazität und breite Modellkompatibilität – alles auf einer einzigen Karte – bietet. Während sie möglicherweise keine massiven Modelle wie Qwen 2.5 72B oder DeepSeek V3 ausführen kann, ist sie eine ausgezeichnete Wahl für mittlere LLMs und Echtzeit-Videoaufgaben. Mit dem Cloud-basierten Zugang zu L40S über Novita AI können Entwickler diese Leistung ohne anfängliche Hardwarekosten nutzen, was die KI-Entwicklung schneller, skalierbarer und erschwinglicher macht.
Häufig gestellte Fragen
Welche LLM-Modelle laufen auf einer einzelnen L40S?
Qwen 2.5 7B
Qwen 3 8B / 4B / 1.7B / 0.6B
Llama 3.1 8B
Llama 3.2 1B
Welche Videomodelle werden unterstützt?
HunyuanVideo (544×960)
Wan T2V-1.3B
Wan T2V-14B
Welche Herausforderungen gibt es bei der lokalen Bereitstellung von L40S?
Kosten → Nutzen Sie Cloud-Anbieter wie Novita AI für erschwingliches Prototyping
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Bauen und Skalieren bietet.
Empfohlene Lektüre



