

主なポイント
これらのモデルに適合 ✅
LLM: Qwen 2.5 7B、Qwen 3(0.6B~8B)、Llama 3.1 8B、Llama 3.2 1B
動画モデル: HunyuanVideo(544×960)、Wan T2V-1.3B、T2V-14B
導入時の課題と修正方法
熱、電力、サイズの問題? PSU仕様、シャーシサイズ、Docker環境、予算に優しいクラウド代替案をカバーします。
Novita AIでハードウェアコストをスキップ
クラウド上でL40Sインスタンスを起動。時間単位で支払い。即座にスケーリング。自分でリグを構築する必要はありません。

Novita AI

Runpod
Novita AIでのL40S利用コストは、RunPodの約半額です。
「自分のモデルは1枚のGPUには大きすぎる」と思っていませんか? もう一度考えてみてください。NVIDIA L40Sはあなたを驚かせるかもしれません。48GB VRAMと第4世代テンソルコアを搭載し、Qwen 3 8B、Llama 3.1 8B、さらには T2V 14B などのモデルも処理できます。
このガイドでは、1枚のL40Sに適合するLLMと動画モデル を具体的に解説します。推測する必要はもうありません。構築を始めましょう。
L40Sが際立つ理由:ハードウェアの詳細
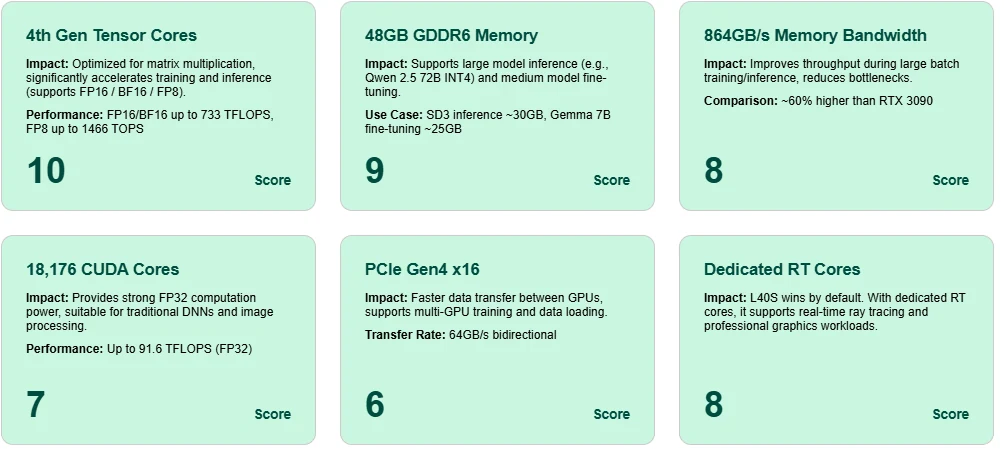
テンソルコアの優秀性
第4世代テンソルコアを搭載したL40Sは、FP8で最大1466 TOPS、BF16/FP16で733 TFLOPSを実現し、最新のAIモデルに対して非常に効率的なトレーニングと推論を可能にします。
大容量48GB GDDR6メモリ
Qwen 2.5 72B(INT4)のような大規模モデルの推論や、Gemma 7Bのような中規模モデルのファインチューニングを1枚のカードでサポートします。
高いメモリ帯域幅
864GB/sの帯域幅により、トレーニング中のアクティベーションやパラメータの移動が高速化され、大バッチシナリオでのレイテンシとボトルネックを低減します。
CUDAコアの汎用性
18,176個のCUDAコアと91.6 FP32 TFLOPSにより、L40Sは従来の深層学習や画像処理に信頼性の高い計算能力を提供します。
PCIe Gen4 x16スループット
GPU間の高速通信を可能にし、トレーニングや推論におけるマルチGPU展開に不可欠です。
レイトレーシング専用RTコア
L40SはAIだけでなく、内蔵RTコアのおかげでリアルタイムグラフィックスやレンダリングタスクにも優れています。
1枚のL40S GPUで実行可能なLLMモデルは?
| モデル | パラメータ数 | FP16重み(推定) | 1枚での判定 |
|---|---|---|---|
| Qwen 2.5 7B | 7 B | 約14 GB | ✅ 適合 |
| Qwen 3 8B / 4B / 1.7B / 0.6B | 8 B以下 | 18 GB以下 | ✅ 適合 |
| Llama 3.1 8B | 8 B | 約18 GB | ✅ 適合 |
| Llama 3.2 1B | 1 B | 約2 GB | ✅ 適合 |
| Gemma 3 27B | 27 B | 約54 GB | ❌ 大きすぎる |
| GLM-4-32B | 32 B | 約64 GB | ❌ 大きすぎる |
| QWQ 32B | 32 B | 約65 GB | ❌ 大きすぎる |
| Qwen 3 30B A3B | 合計30 B | 約61 GB* | ❌ 大きすぎる |
| Llama 3.3 70B | 70 B | 約140 GB | ❌ 大きすぎる |
| Qwen 2.5-VL 72B | 72 B | 約144 GB | ❌ 大きすぎる |
| Llama 4 Scout / Maverick | 109 B / 400 B | 約218 GB / 約800 GB | ❌ 大きすぎる |
| DeepSeek R1 / V3 | 合計671 B | 約1.34 TB* | ❌ 大きすぎる |
| Qwen 3 235B A22B | 合計235 B | 約470 GB* | ❌ 大きすぎる |
L40S GPUで実行可能な動画モデルは?
| モデル/解像度 | シングルカードL40S(48 GB) |
|---|---|
| HunyuanVideo 544 × 960 | ✅ 1枚で適合 |
| HunyuanVideo 720 × 1280 | ❌ NVLink接続の2枚以上が必要 |
| Wan T2V-1.3B | ✅ 十分な余裕あり |
| Wan T2V-14B | ✅ 1枚で適合 |
NVIDIA L40S GPUを導入する際の障害は?
障害:高い消費電力(350~400 W)は、一般的なデスクトップPSUに過負荷をかける可能性があります。
解決策: ネイティブの12VHPWRまたはデュアル8ピンアダプターを備えたATX 3.0 / 80 Plus Gold(1000 W以上)の電源を導入します。
障害:かなりの熱出力が小さなケースをすぐに飽和させます。
解決策: 広々としたエアフローチャシスまたは4Uラックを選び、高回転ファンや240mm以上のAIO/水冷ループを追加します。
障害:3スロットの長さと高さが多くのミッドタワーのクリアランスを超えます。
解決策: まず寸法を測定し、きつい場合はオープンテストベンチ、垂直GPUブラケット、またはワークステーション用シャーシに移行します。
障害:ソフトウェアスタックはCUDA 12+、cuDNN 9、および最新のカーネルをターゲットにする必要があります。
解決策: CondaまたはDockerイメージを使用して、一致するドライバー/CUDAバージョンに固定して隔離します。ホストにインストールする前にCIでビルドをテストします。
障害:個人開発者にとって初期のハードウェアコストが高いです。
解決策: 時間単位のクラウドL40Sノード(例:Novita AI)でプロトタイプを作成し、ワークロードのサイジング後にのみローカルで購入します。
よりコスト効率の良い方法:Novita AI
Novita AIは、高性能GPUインスタンスを備えたクラウドベースのプラットフォームを提供します。強力なGPUにより、複雑なタスクの効率的なパフォーマンスを保証し、さまざまなハードウェアへの展開のしやすさを向上させ、大規模AI展開のためのローカルハードウェアの維持と比較してコスト効率の良いソリューションを提供します。
ステップ1:アカウント登録
ウェブサイトからNovita AIアカウントを作成します。登録後、左側のサイドバーにある「Explore」セクションに移動して、GPUの提供内容を確認し、AI開発の旅を始めましょう。

ステップ2:テンプレートとGPUサーバーの探索
プロジェクトのニーズに合ったPyTorch、TensorFlow、CUDAなどのテンプレートを選択します。次に、希望するGPU構成を選択します。オプションには、強力なL40S、RTX 4090、A100 SXM4などがあり、それぞれVRAM、RAM、ストレージの仕様が異なります。

ステップ3:デプロイメントのカスタマイズ
好みのオペレーティングシステムと構成オプションを選択して環境をカスタマイズし、特定のAIワークロードと開発ニーズに最適なパフォーマンスを確保します。

ステップ4:インスタンスの起動
「Launch Instance」を選択してデプロイを開始します。高性能GPU環境は数分以内に準備完了し、すぐに機械学習、レンダリング、または計算プロジェクトを開始できます。
NVIDIA L40Sは、強力なテンソルパフォーマンス、大容量メモリ、幅広いモデル互換性を1枚のカードで提供する、バランスの取れたGPUとして際立っています。Qwen 2.5 72BやDeepSeek V3のような巨大モデルは実行できませんが、中規模のLLMやリアルタイム動画タスクには最適な選択肢です。Novita AIのクラウドベースのL40Sアクセスにより、開発者は初期ハードウェアコストなしでこのパフォーマンスを活用でき、AI開発をより高速でスケーラブルかつ手頃なものにできます。
よくある質問
1枚のL40Sで実行可能なLLMモデルは?
Qwen 2.5 7B
Qwen 3 8B / 4B / 1.7B / 0.6B
Llama 3.1 8B
Llama 3.2 1B
サポートされている動画モデルは?
HunyuanVideo(544×960)
Wan T2V-1.3B
Wan T2V-14B
L40Sをローカルで導入する際の課題は?
**コスト ** → Novita AIのようなクラウドプロバイダーを使用して手頃にプロトタイプを作成
Novita AIは、シンプルなAPIを使用してAIモデルを簡単にデプロイできる機能を開発者に提供するとともに、AIモデルの構築とスケーリングのための手頃で信頼性の高いGPUクラウドを提供するAIクラウドプラットフォームです。
おすすめの記事



