

关键亮点
适配以下模型 ✅
LLM: Qwen 2.5 7B、Qwen 3 (0.6B–8B)、Llama 3.1 8B、Llama 3.2 1B
视频模型: HunyuanVideo (544×960)、Wan T2V-1.3B、T2V-14B
部署挑战与解决方案
散热、功耗和体积问题?我们涵盖了电源规格、机箱尺寸、Docker 环境以及经济实惠的云替代方案。
使用 Novita AI 省去硬件成本
在云端启动 L40S 实例。按小时付费。即时扩展。无需自行搭建硬件。

Novita AI

RunPod
Novita AI 上 L40S 的使用成本大约仅为 RunPod 价格的一半。
认为你的模型对于单 GPU 来说太大了?再想想看。 NVIDIA L40S 可能会让你惊讶。凭借 48GB 显存和第 4 代 Tensor Core,它可以处理比预期更多的模型——包括 Qwen 3 8B、Llama 3.1 8B,甚至 T2V 14B。
在本指南中,我们将具体分析 哪些 LLM 和视频模型 可以适配单张 L40S——这样你就不必再猜测,可以立即开始构建。
为什么 L40S 脱颖而出:硬件深度剖析
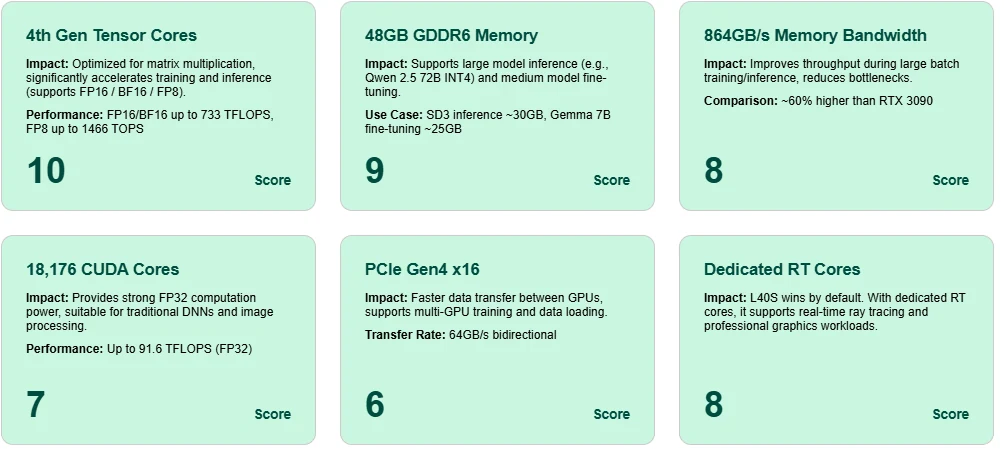
卓越的 Tensor Core
搭载第 4 代 Tensor Core,L40S 在 FP8 下可实现高达 1466 TOPS,在 BF16/FP16 下可达 733 TFLOPS,为现代 AI 模型提供高效的训练与推理能力。
巨大的 48GB GDDR6 显存
支持在单卡上推理大规模模型(如 Qwen 2.5 72B INT4),并对中规模模型(如 Gemma 7B)进行微调。
高内存带宽
864GB/s 带宽确保训练过程中的快速激活和参数移动,减少延迟和大批量场景下的瓶颈。
多用途 CUDA Core
拥有 18,176 个 CUDA Core 和 91.6 FP32 TFLOPS,L40S 为传统深度学习和图像处理提供可靠算力。
PCIe Gen4 x16 吞吐量
支持 GPU 间高速通信,对于多 GPU 训练或推理部署至关重要。
专用 RT Core 用于光线追踪
L40S 不仅适用于 AI——内置的 RT Core 使其在实时图形和渲染任务中同样出色。
哪些 LLM 模型可以在单张 L40S GPU 上运行?
| 模型 | 参数 | FP16 权重(估计) | 单卡结论 |
|---|---|---|---|
| Qwen 2.5 7B | 7 B | ~14 GB | ✅ 适配 |
| Qwen 3 8B / 4B / 1.7B / 0.6B | ≤ 8 B | ≤ 18 GB | ✅ 适配 |
| Llama 3.1 8B | 8 B | ~18 GB | ✅ 适配 |
| Llama 3.2 1B | 1 B | ~2 GB | ✅ 适配 |
| Gemma 3 27B | 27 B | ~54 GB | ❌ 过大 |
| GLM-4-32B | 32 B | ~64 GB | ❌ 过大 |
| QWQ 32B | 32 B | ~65 GB | ❌ 过大 |
| Qwen 3 30B A3B | 30 B 总数 | ~61 GB* | ❌ 过大 |
| Llama 3.3 70B | 70 B | ~140 GB | ❌ 过大 |
| Qwen 2.5-VL 72B | 72 B | ~144 GB | ❌ 过大 |
| Llama 4 Scout / Maverick | 109 B / 400 B | ~218 GB / ~800 GB | ❌ 过大 |
| DeepSeek R1 / V3 | 671 B 总数 | ~1.34 TB* | ❌ 太大 |
| Qwen 3 235B A22B | 235 B 总数 | ~470 GB* | ❌ 过大 |
哪些视频模型可以在 L40S GPU 上运行?
| 模型 / 分辨率 | 单卡 L40 S(48 GB) |
|---|---|
| HunyuanVideo 544 × 960 | ✅ 单卡适配 |
| HunyuanVideo 720 × 1280 | ❌ 需要 ≥ 2 张 NVLink 互联卡 |
| Wan T2V-1.3B | ✅ 余量充足 |
| Wan T2V-14B | ✅ 单卡适配 |
部署 NVIDIA L40S GPU 时会遇到哪些障碍?
障碍:高功耗(350 – 400 W)可能压垮普通桌面电源。
解决方案: 安装 ATX 3.0 / 80 Plus Gold(≥ 1000 W)电源,需带有原生 12VHPWR 或双 8-pin 转接头。
障碍:大量热量迅速使小型机箱饱和。
解决方案: 选择通风良好的宽敞机箱或 4U 机架,增加高转速风扇或 240mm+ AIO/水冷回路。
障碍:三槽长度和高度超出许多中塔机箱的兼容范围。
解决方案: 先测量尺寸;如果空间紧张,改用开放式测试平台、垂直 GPU 支架或工作站机箱。
障碍:软件栈必须针对 CUDA 12+、cuDNN 9 和最新内核进行配置。
解决方案: 使用 Conda 或 Docker 镜像隔离,固定匹配的驱动/CUDA 版本;先在 CI 中测试构建,再在宿主机上安装。
障碍:个人开发者面临高昂的硬件前期成本。
解决方案: 在按小时的云 L40S 节点(例如 Novita AI)上搭建原型,确认工作负载规模后再考虑本地采购。
更具性价比的方式:Novita AI
Novita AI 提供基于云的高性能 GPU 实例平台。凭借强大的 GPU,它可确保复杂任务的高效性能,提升跨硬件部署的便利性,并且相比维护本地硬件进行大规模 AI 部署,更具成本效益。
步骤 1:注册账户
通过我们的网站创建你的 Novita AI 账户。注册后,在左侧边栏导航到“探索”部分,查看我们的 GPU 产品并开启你的 AI 开发之旅。

步骤 2:探索模板和 GPU 服务器
选择符合项目需求的模板,如 PyTorch、TensorFlow 或 CUDA。然后选择你偏好的 GPU 配置——可选选项包括强大的 L40S、RTX 4090 或 A100 SXM4,每种配置具有不同的显存、内存和存储规格。

步骤 3:定制你的部署
通过选择首选的系统环境和配置选项来定制你的部署环境,以确保为特定 AI 工作负载和开发需求提供最佳性能。

步骤 4:启动实例
选择“启动实例”开始部署。几分钟内,你的高性能 GPU 环境即可就绪,让你能立即开始机器学习、渲染或计算项目。
NVIDIA L40S 是一款均衡的 GPU,在单卡上提供了强大的张量性能、大容量显存和广泛的模型兼容性。虽然它可能无法运行诸如 Qwen 2.5 72B 或 DeepSeek V3 这样的大规模模型,但对于中端 LLM 和实时视频任务来说,它是一个出色的选择。借助 Novita AI 的云 L40S 访问,开发者无需前期硬件成本即可享受这一性能,使 AI 开发更快、更具可扩展性且更经济实惠。
常见问题解答
哪些 LLM 模型可以在单张 L40S 上运行?
Qwen 2.5 7B
Qwen 3 8B / 4B / 1.7B / 0.6B
Llama 3.1 8B
Llama 3.2 1B
支持哪些视频模型?
HunyuanVideo (544×960)
Wan T2V-1.3B
Wan T2V-14B
本地部署 L40S 存在哪些挑战?
**成本 ** → 使用云服务商如 Novita AI 进行低成本原型测试
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,同时提供经济实惠且可靠的 GPU 云用于构建和扩展。
推荐阅读



