

Principais Destaques
Atende a estes Modelos ✅
LLMs: Qwen 2.5 7B, Qwen 3 (0.6B–8B), Llama 3.1 8B, Llama 3.2 1B
Modelos de Vídeo: HunyuanVideo (544×960), Wan T2V-1.3B, T2V-14B
Desafios de Implantação e Soluções
Problemas de calor, energia e tamanho? Abordamos especificações da fonte, dimensionamento do chassi, ambientes Docker e alternativas de nuvem econômicas.
Evite Custos de Hardware com a Novita AI
Lance instâncias L40S na nuvem. Pague por hora. Escale instantaneamente. Sem necessidade de montar sua própria máquina.

Novita AI

Runpod
O custo de usar L40S na Novita AI é aproximadamente metade do preço do RunPod.
Lance sua instância GPU L40S agora
Acha que seu modelo é grande demais para uma única GPU? Pense de novo. A NVIDIA L40S pode surpreender você. Com 48 GB de VRAM e Tensor Cores de 4ª Geração, ela aguenta mais do que você imagina — incluindo modelos como Qwen 3 8B, Llama 3.1 8B e até mesmo T2V 14B.
Neste guia, detalhamos exatamente quais LLMs e modelos de vídeo cabem em uma única L40S — para que você possa parar de adivinhar e começar a construir.
Por que a L40S se Destaca: Um Mergulho Técnico no Hardware
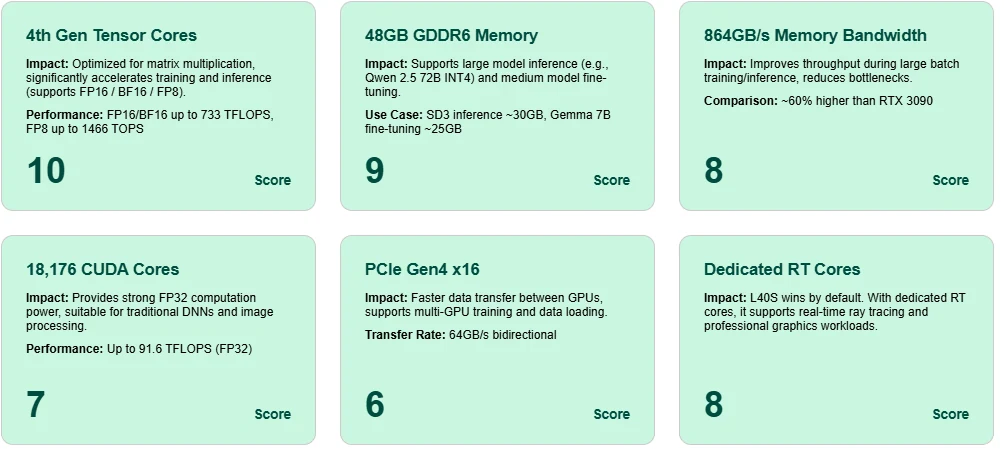
Excelência dos Tensor Cores
Equipada com Tensor Cores de 4ª Geração, a L40S atinge até 1466 TOPS com FP8 e 733 TFLOPS com BF16/FP16, possibilitando treinamento e inferência altamente eficientes para modelos modernos de IA.
Memória GDDR6 Massiva de 48 GB
Suporta inferência de modelos de grande escala como Qwen 2.5 72B (INT4) e ajuste fino de modelos de médio porte como Gemma 7B — tudo em uma única placa.
Alta Largura de Banda de Memória
864 GB/s de largura de banda garantem movimentação rápida de ativações e parâmetros durante o treinamento, reduzindo latência e gargalos em cenários de grandes lotes.
Versatilidade dos CUDA Cores
Com 18.176 núcleos CUDA e 91,6 TFLOPS FP32, a L40S oferece poder computacional confiável para aprendizado profundo convencional e processamento de imagens.
Throughput PCIe Gen4 x16
Permite comunicação em alta velocidade entre GPUs, essencial para implantações com múltiplas GPUs em treinamento ou inferência.
RT Cores Dedicados para Ray Tracing
A L40S não é apenas para IA — ela também se destaca em gráficos em tempo real e tarefas de renderização, graças aos seus núcleos RT integrados.
Quais Modelos LLM Podem Ser Executados em Uma Única GPU L40S?
| Modelo | Parâmetros | Pesos FP16 (est.) | Verdicto para uma placa |
|---|---|---|---|
| Qwen 2.5 7B | 7 B | ~14 GB | ✅ Cabe |
| Qwen 3 8B / 4B / 1.7B / 0.6B | ≤ 8 B | ≤ 18 GB | ✅ Cabe |
| Llama 3.1 8B | 8 B | ~18 GB | ✅ Cabe |
| Llama 3.2 1B | 1 B | ~2 GB | ✅ Cabe |
| Gemma 3 27B | 27 B | ~54 GB | ❌ Muito grande |
| GLM-4-32B | 32 B | ~64 GB | ❌ Muito grande |
| QWQ 32B | 32 B | ~65 GB | ❌ Muito grande |
| Qwen 3 30B A3B | 30 B total | ~61 GB* | ❌ Muito grande |
| Llama 3.3 70B | 70 B | ~140 GB | ❌ Muito grande |
| Qwen 2.5-VL 72B | 72 B | ~144 GB | ❌ Muito grande |
| Llama 4 Scout / Maverick | 109 B / 400 B | ~218 GB / ~800 GB | ❌ Muito grande |
| DeepSeek R1 / V3 | 671 B total | ~1,34 TB* | ❌ Muito grande |
| Qwen 3 235B A22B | 235 B total | ~470 GB* | ❌ Muito grande |
Quais Modelos de Vídeo Podem Ser Executados na GPU L40S?
| Modelo / Resolução | L40 S de placa única (48 GB) |
|---|---|
| HunyuanVideo 544 × 960 | ✅ Cabe em uma placa |
| HunyuanVideo 720 × 1280 | ❌ Precisa de ≥ 2 placas com NVLink |
| Wan T2V-1.3B | ✅ Bastante folga |
| Wan T2V-14B | ✅ Cabe em uma placa |
Quais Obstáculos ao Implantar uma GPU NVIDIA L40S?
Obstáculo: Alto consumo de energia (350–400 W) pode sobrecarregar fontes de mesa típicas.
Solução: Instale uma fonte ATX 3.0 / 80 Plus Gold (≥ 1000 W) com conector nativo 12VHPWR ou adaptadores duplo de 8 pinos.
Obstáculo: Produção substancial de calor satura rapidamente gabinetes pequenos.
Solução: Escolha um gabinete espaçoso com boa ventilação ou rack 4U, adicione ventoinhas de alta RPM ou um sistema AIO/water cooler de 240 mm+.
Obstáculo: Comprimento e altura de três slots excedem a folga de muitos gabinetes mid-tower.
Solução: Meça primeiro; se estiver apertado, opte por uma bancada de testes aberta, suporte vertical para GPU ou gabinete workstation.
Obstáculo: Pilhas de software devem ter como alvo CUDA 12+, cuDNN 9 e kernels recentes.
Solução: Isole com ambientes Conda ou imagens Docker fixadas nas versões de driver/CUDA correspondentes; teste as builds em CI antes da instalação no host.
Obstáculo: O custo inicial de hardware é alto para desenvolvedores individuais.
Solução: Faça protótipos em nós L40S na nuvem por hora (ex.: Novita AI) e compre localmente somente após dimensionar a carga de trabalho.
Uma Maneira Mais Econômica: Novita AI
A Novita AI oferece uma plataforma baseada em nuvem com instâncias GPU de alto desempenho. Com GPUs potentes, garante desempenho eficiente para tarefas complexas, aumenta a acessibilidade para implantação em diversos hardwares e oferece uma solução econômica em comparação com a manutenção de hardware local para implantações de IA em grande escala.
Passo 1: Crie uma conta
Crie sua conta Novita AI através do nosso site. Após o registro, navegue até a seção “Explorar” na barra lateral esquerda para ver nossas ofertas de GPU e começar sua jornada de desenvolvimento de IA.

Passo 2: Explore Modelos e Servidores GPU
Escolha entre modelos como PyTorch, TensorFlow ou CUDA que correspondam às necessidades do seu projeto. Em seguida, selecione sua configuração de GPU preferida — as opções incluem a potente L40S, RTX 4090 ou A100 SXM4, cada uma com diferentes especificações de VRAM, RAM e armazenamento.

Passo 3: Personalize sua Implantação
Customize seu ambiente selecionando seu sistema operacional preferido e opções de configuração para garantir o desempenho ideal para suas cargas de trabalho e necessidades de desenvolvimento de IA.

Passo 4: Lance uma instância
Selecione “Lançar Instância” para iniciar sua implantação. Seu ambiente GPU de alto desempenho estará pronto em minutos, permitindo que você comece imediatamente seus projetos de aprendizado de máquina, renderização ou computação.
A NVIDIA L40S se destaca como uma GPU equilibrada, oferecendo desempenho tensor poderoso, grande capacidade de memória e ampla compatibilidade com modelos — tudo em uma única placa. Embora não execute modelos massivos como Qwen 2.5 72B ou DeepSeek V3, é uma excelente escolha para LLMs de médio porte e tarefas de vídeo em tempo real. Com o acesso baseado em nuvem da Novita AI à L40S, os desenvolvedores podem aproveitar esse desempenho sem os custos iniciais de hardware, tornando o desenvolvimento de IA mais rápido, escalável e acessível.
Perguntas Frequentes
Quais modelos LLM podem ser executados em uma única L40S?
Qwen 2.5 7B
Qwen 3 8B / 4B / 1.7B / 0.6B
Llama 3.1 8B
Llama 3.2 1B
Quais modelos de vídeo são suportados?
HunyuanVideo (544×960)
Wan T2V-1.3B
Wan T2V-14B
Quais desafios existem ao implantar a L40S localmente?
Custo → Use provedores de nuvem como a Novita AI para prototipar de forma acessível
A Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer a nuvem GPU acessível e confiável para construir e escalar.
Leitura Recomendada



