

Key Highlights
Fits These Models ✅
LLMs: Qwen 2.5 7B, Qwen 3 (0.6B–8B), Llama 3.1 8B, Llama 3.2 1B
Video Models: HunyuanVideo (544×960), Wan T2V-1.3B, T2V-14B
Deployment Challenges & Fixes
Heat, power, and size issues? We cover PSU specs, chassis sizing, Docker environments, and budget-friendly cloud alternatives.
Skip Hardware Costs with Novita AI
Launch L40S instances in the cloud. Pay hourly. Scale instantly. No need to build your own rig.

Novita AI

Runpod
The cost of using L40S on Novita AI is approximately half the price of RunPod.
Launch your L40s GPU instance now
Think your model is too big for a single GPU? Think again. The NVIDIA L40S may surprise you. With 48GB VRAM and 4th Gen Tensor Cores, it can handle more than you’d expect—including models like Qwen 3 8B, Llama 3.1 8B, and even T2V 14B.
In this guide, we break down exactly which LLMs and video models fit on a single L40S—so you can stop guessing, and start building.
Why L40S Stands Out: A Hardware Deep-Dive
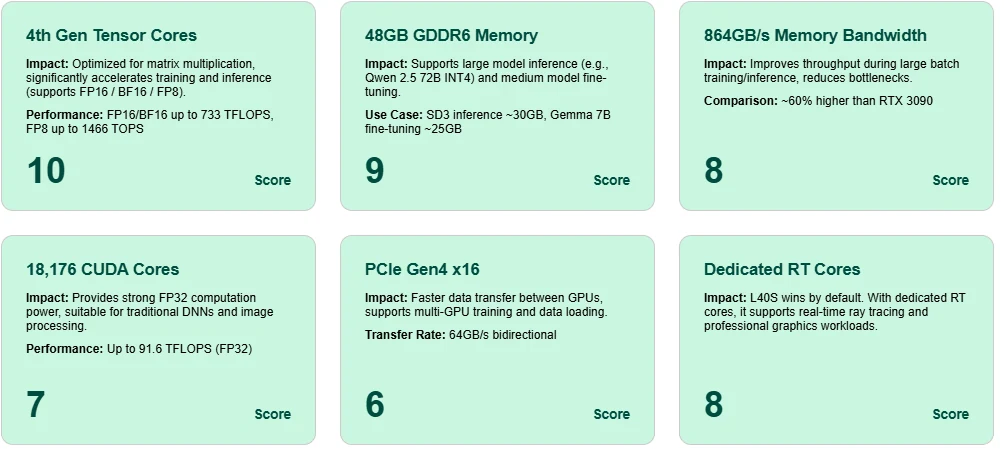
Tensor Core Excellence
Equipped with 4th Gen Tensor Cores, L40S achieves up to 1466 TOPS with FP8 and 733 TFLOPS with BF16/FP16, enabling highly efficient training and inference for modern AI models.
Massive 48GB GDDR6 Memory
Supports inference of large-scale models like Qwen 2.5 72B (INT4) and fine-tuning of mid-sized models such as Gemma 7B—all on a single card.
High Memory Bandwidth
864GB/s bandwidth ensures fast activation and parameter movement during training, reducing latency and bottlenecks in large-batch scenarios.
CUDA Core Versatility
With 18,176 CUDA cores and 91.6 FP32 TFLOPS, L40S delivers reliable compute power for conventional deep learning and image processing.
PCIe Gen4 x16 Throughput
Enables high-speed communication between GPUs, essential for multi-GPU deployments in training or inference.
Dedicated RT Cores for Ray Tracing
L40S isn’t just for AI—it also excels in real-time graphics and rendering tasks, thanks to its built-in RT cores.
Which LLM Models Can Be Run on Single L40S GPU?
| Model | Parameters | FP16 Weights (est.) | One-Card Verdict |
|---|---|---|---|
| Qwen 2.5 7B | 7 B | ~14 GB | ✅ Fits |
| Qwen 3 8B / 4B / 1.7B / 0.6B | ≤ 8 B | ≤ 18 GB | ✅ Fits |
| Llama 3.1 8B | 8 B | ~18 GB | ✅ Fits |
| Llama 3.2 1B | 1 B | ~2 GB | ✅ Fits |
| Gemma 3 27B | 27 B | ~54 GB | ❌ Too large |
| GLM-4-32B | 32 B | ~64 GB | ❌ Too large |
| QWQ 32B | 32 B | ~65 GB | ❌ Too large |
| Qwen 3 30B A3B | 30 B total | ~61 GB* | ❌ Too large |
| Llama 3.3 70B | 70 B | ~140 GB | ❌ Too large |
| Qwen 2.5-VL 72B | 72 B | ~144 GB | ❌ Too large |
| Llama 4 Scout / Maverick | 109 B / 400 B | ~218 GB / ~800 GB | ❌ Too large |
| DeepSeek R1 / V3 | 671 B total | ~1.34 TB* | ❌ Way too large |
| Qwen 3 235B A22B | 235 B total | ~470 GB* | ❌ Too large |
Which Video Models Can Be Run on L40S GPU?
| Model / Resolution | Single-Card L40 S (48 GB) |
|---|---|
| HunyuanVideo 544 × 960 | ✅ Fits on one card |
| HunyuanVideo 720 × 1280 | ❌ Needs ≥ 2 NVLink-linked cards |
| Wan T2V-1.3B | ✅ Plenty of headroom |
| Wan T2V-14B | ✅ Fits on one card |
What obstacles when deploying an NVIDIA L40S GPU?
Obstacle: High power draw (350 – 400 W) can overload typical desktop PSUs.
Solution: Install an ATX 3.0 / 80 Plus Gold (≥ 1000 W) supply that includes native 12VHPWR or dual 8-pin adapters.
Obstacle: Substantial heat output quickly saturates small cases.
Solution: Choose a spacious airflow chassis or 4U rack, add high-RPM fans or a 240 mm+ AIO/water loop.
Obstacle: Three-slot length & height exceed many mid-tower clearances.
Solution: Measure first; if tight, move to an open test bench, vertical GPU bracket, or workstation chassis.
Obstacle: Software stacks must target CUDA 12+, cuDNN 9, and recent kernels.
Solution: Isolate with Conda or Docker images pinned to matching driver/CUDA versions; test builds in CI before host install.
Obstacle: Up-front hardware cost is high for individual developers.
Solution: Prototype on hourly cloud L40S nodes (e.g., Novita AI and purchase locally only after workload sizing.
A More Cost-effective Way: Novita AI
Novita AI provides a cloud-based platform with high-performance GPU instances. With powerful GPUs, it ensures efficient performance for complex tasks, enhances accessibility for deployment across various hardware, and offers a cost-effective solution compared to maintaining local hardware for large-scale AI deployments.
Step1:Register an account
Create your Novita AI account through our website. After registration, navigate to the “Explore” section in the left sidebar to view our GPU offerings and begin your AI development journey.

Step2:Exploring Templates and GPU Servers
Choose from templates like PyTorch, TensorFlow, or CUDA that match your project needs. Then select your preferred GPU configuration—options include the powerful L40S, RTX 4090 or A100 SXM4, each with different VRAM, RAM, and storage specifications.

Step3:Tailor Your Deployment
Customize your environment by selecting your preferred operating system and configuration options to ensure optimal performance for your specific AI workloads and development needs.

Step4:Launch an instance
Select “Launch Instance” to start your deployment. Your high-performance GPU environment will be ready within minutes, allowing you to immediately begin your machine learning, rendering, or computational projects.
The NVIDIA L40S stands out as a well-balanced GPU, delivering powerful tensor performance, large memory capacity, and broad model compatibility—all on a single card. While it may not run massive models like Qwen 2.5 72B or DeepSeek V3, it’s an excellent choice for mid-range LLMs and real-time video tasks. With Novita AI’s cloud-based access to L40S, developers can tap into this performance without the upfront hardware costs, making AI development faster, scalable, and more affordable.
Frequently Asked Questions
Which LLM models can run on a single L40S?
Qwen 2.5 7B
Qwen 3 8B / 4B / 1.7B / 0.6B
Llama 3.1 8B
Llama 3.2 1B
What video models are supported?
HunyuanVideo (544×960)
Wan T2V-1.3B
Wan T2V-14B
What challenges exist when deploying L40S locally?
Cost → Use cloud providers like Novita AI to prototype affordably
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.
Recommended Reading



