

MiniMax M2.5 can run on consumer hardware — but only with aggressive quantization. With Dynamic 3-bit GGUF quantization from Unsloth AI, you can shrink the 457GB full-precision model down to approximately 101GB. This guide breaks down real VRAM requirements across quantization levels, maps them to specific GPU configurations with Novita AI cloud pricing.
MiniMax M2.5 Introduction
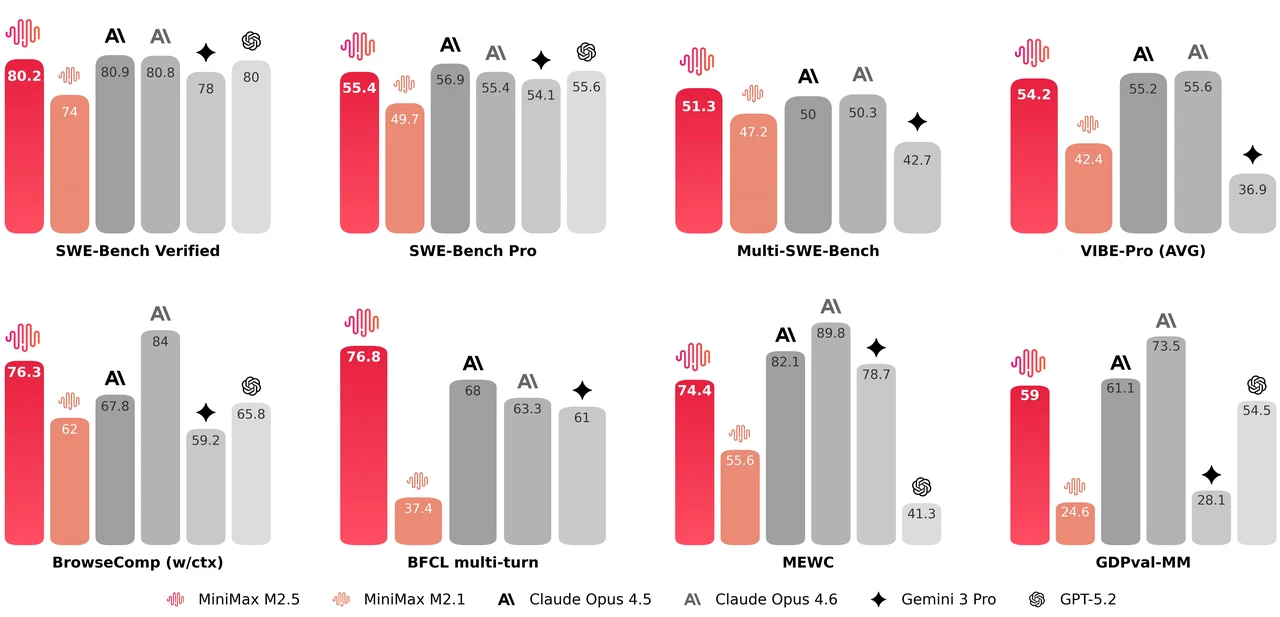
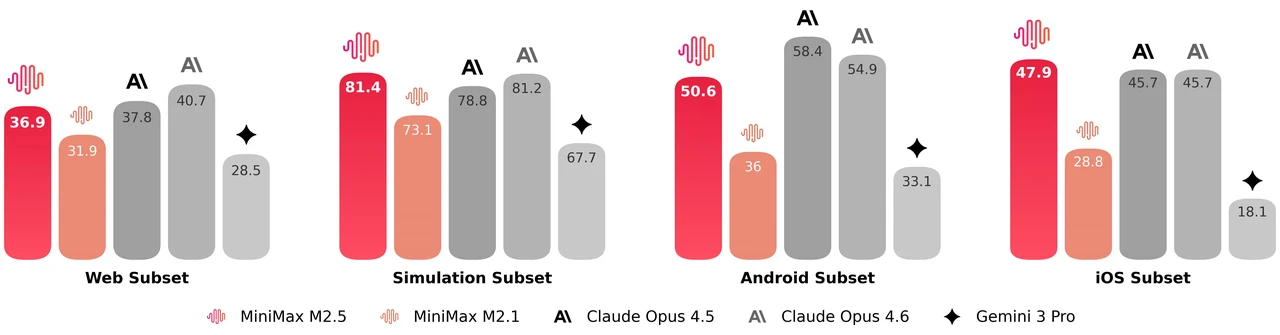
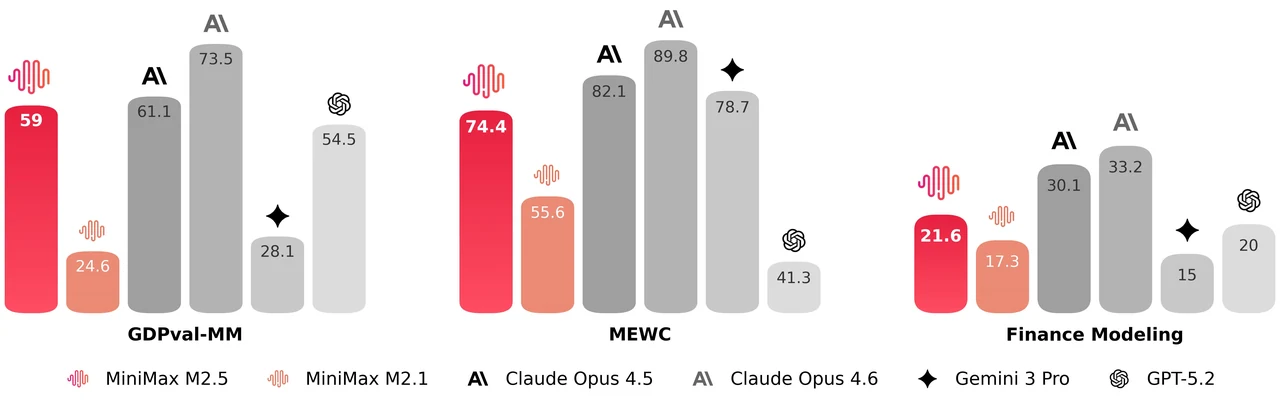
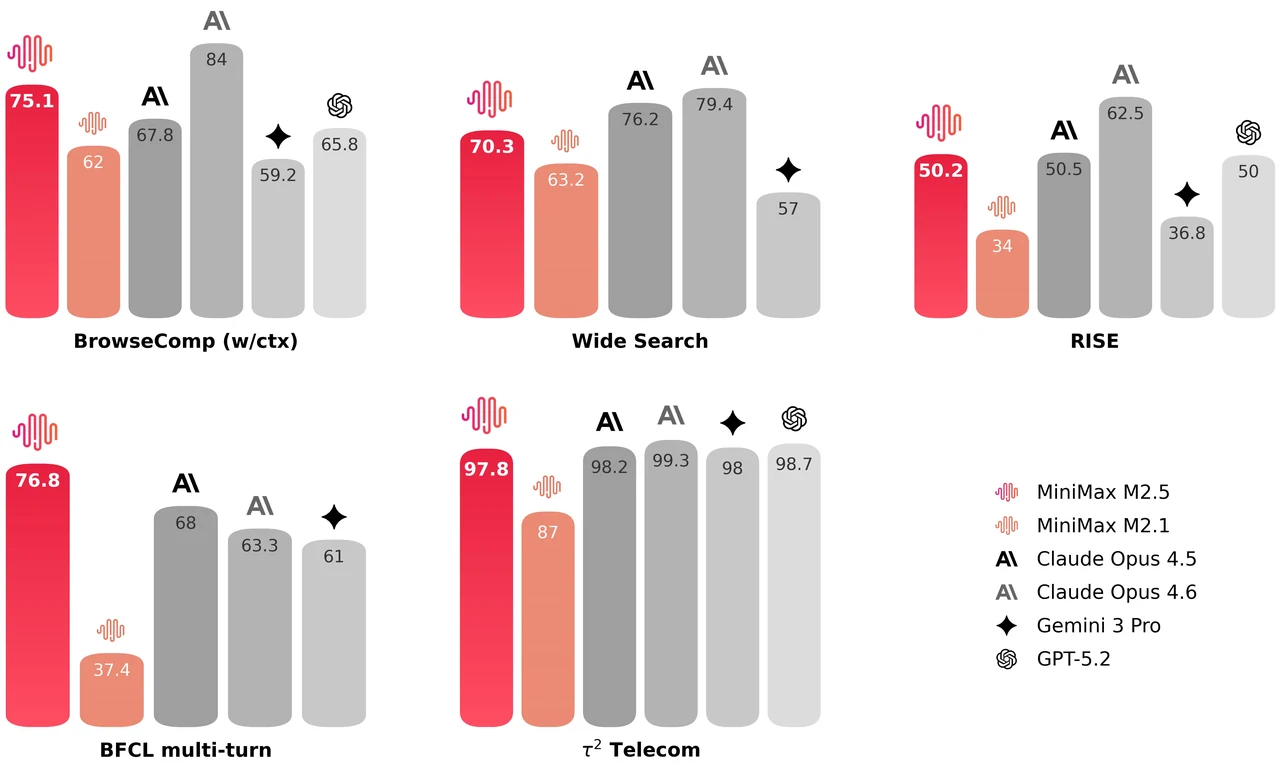
MiniMax M2.5 is a 229B parameter mixture-of-experts model with 256 expert layers, activating 8 experts (approximately 10B parameters) per token. It achieves 80.2% on SWE-Bench Verified, 51.3% on Multi-SWE-Bench, and 76.3% on BrowseComp, making it one of the strongest open models for agentic coding and tool use. The model supports a 205K token context window and is MIT-licensed for unrestricted commercial use.
From Huggingface
From Huggingface
From Huggingface
VRAM Requirements of MiniMax M2.5
VRAM needs scale with precision level. The table below shows file sizes from Unsloth’s GGUF quantizations and hybrid AWQ formats — add 4-10GB overhead for KV cache depending on context length and batch size.
| Configuration | VRAM Required |
|---|---|
| BF16 (full precision) | 457 GB |
| Q8_0 GGUF | 243 GB |
| Q6_K GGUF | 188 GB |
| Q4_K_M GGUF | 138 GB |
| IQ4_XS GGUF | 122 GB |
| Q3_K_M GGUF (Dynamic 3-bit) | 109 GB |
| Q2_K GGUF | 83 GB |
| UD-IQ2_XXS GGUF (Ultra-Dynamic 2-bit) | 74 GB |
With a hybrid quantization scheme (INT4 AWQ weights, FP8 attention, and calibrated FP8 KV cache), MiniMax M2.5 can reach 370K context on 192GB VRAM and enable significantly higher batching throughput compared to standard AWQ, which is typically KV-cache limited.
GPU Recommendations of MiniMax M2.5
All pricing below reflects Novita AI on-demand rates. Multi-GPU costs are calculated as single-GPU price × count.
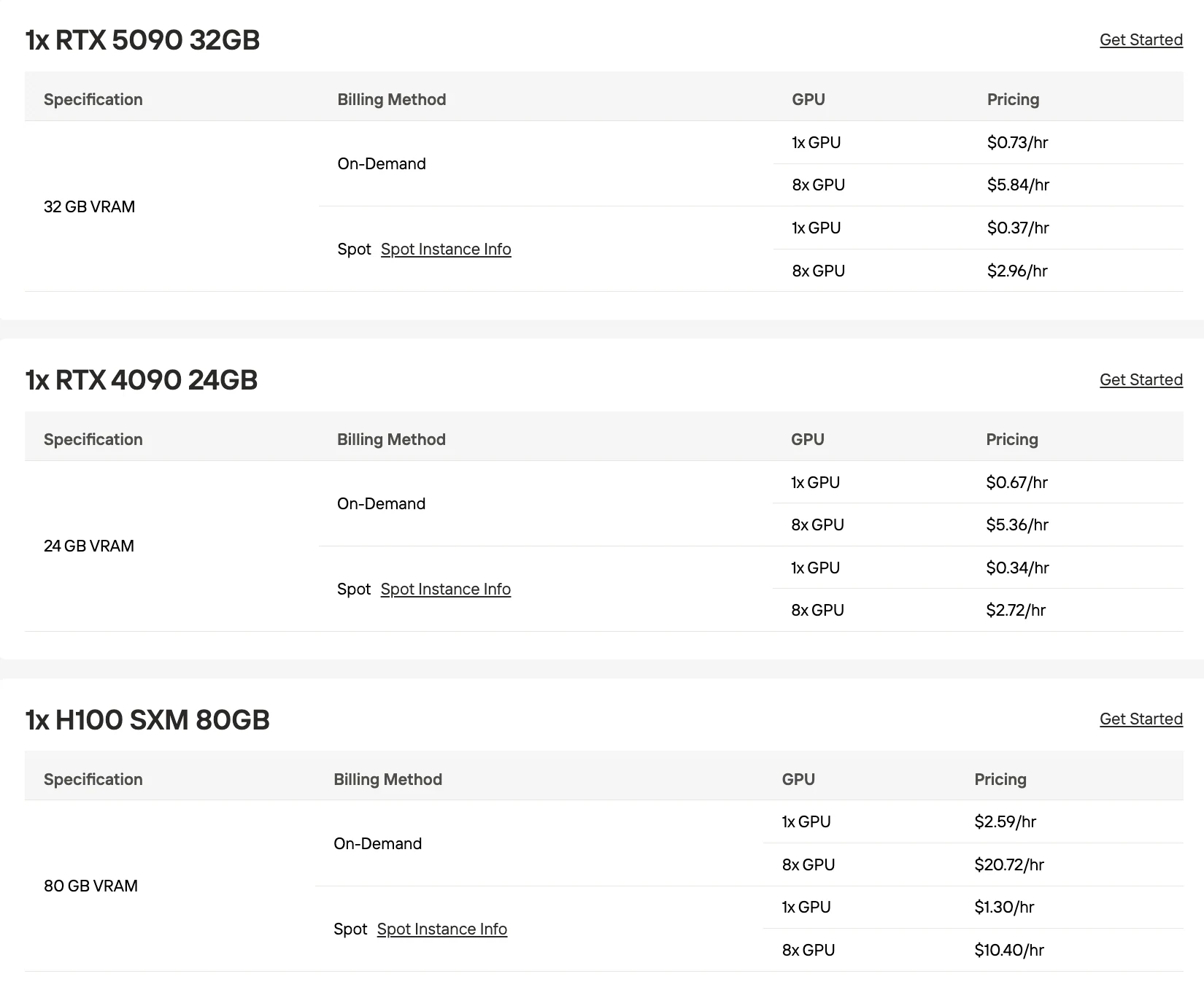
RTX 5090 (32GB)
| Configuration | Total VRAM | Quantization | Notes |
|---|---|---|---|
| 3× RTX 5090 | 96GB | Q2_K | Works but pushes memory limits |
| 4× RTX 5090 | 128GB | Q3_K_M Dynamic 3-bit | Stable with moderate batching |
H100 (80GB)
| Configuration | Total VRAM | Quantization | Notes |
|---|---|---|---|
| 2× H100 | 160GB | Q4_K_M | Stable deployment with higher model quality |
Not Recommended: Single RTX 4090 or RTX 5090 cannot fit MiniMax M2.5 even at the most aggressive quantizations. Strix Halo APU with Q3_K_M yields “almost not usable” speeds, handling 80K context but at impractical inference speeds.
https://www.reddit.com/r/LocalLLaMA/comments/1r8rgcp/minimax\_25\_on\_strix\_halo\_thread/
Practical Deployment Strategies
Strategy 1: API-First with Spot GPU Failover
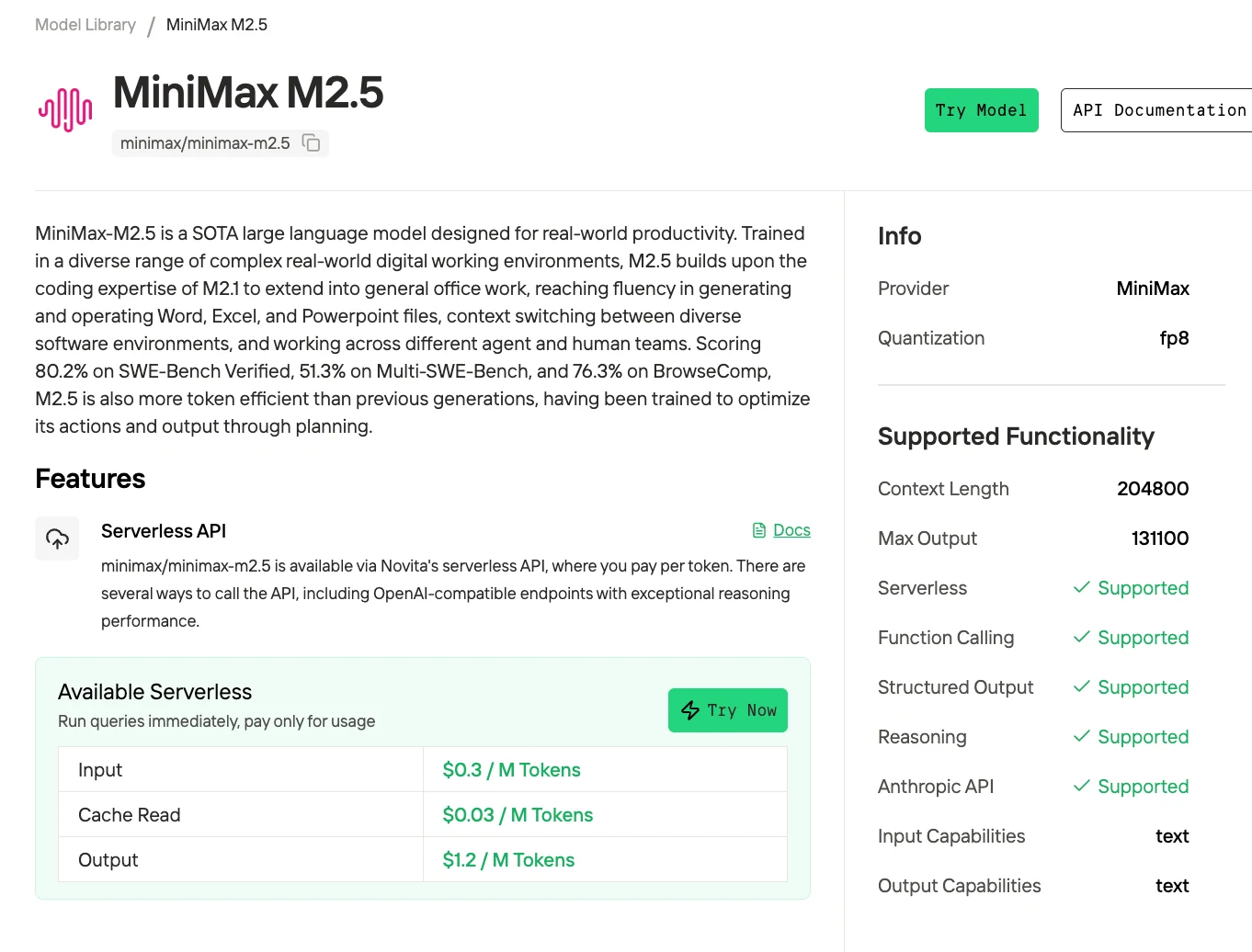
Start with Novita AI API at $0.30/$1.20 per 1M tokens for development and light production. When traffic scales beyond ~100M tokens/month ($150/month API cost), spin up spot instances of 2×H100 at $5.18/hr for batch processing jobs, keeping API for real-time user-facing inference. This hybrid approach caps costs while maintaining low latency for interactive use.
To further reduce cost at scale, Novita offers low-cost API pricing alongside discounted prompt cache reads. When prompts are reused (e.g., system instructions, templates, or repeated context), cached tokens are served at a lower rate instead of being recomputed—cutting both latency and cost. This makes the API-first + batching architecture even more efficient, especially for agentic workflows and high-frequency queries.
Strategy 2: Self-Hosted with Quantization
For teams with privacy requirements or high-volume sustained workloads, deploy Q3_K_M Dynamic 3-bit or Q4_K_M quantization on 2×H100. Use llama.cpp for GGUF formats or vLLM with AWQ for production-grade throughput optimization.
How to Access MiniMax M2.5 in Cloud GPU?
Step 1: Register an account
Create your Novita AI account through our website. After registration, navigate to the “Explore” section in the left sidebar to view our GPU offerings and begin your AI development journey.

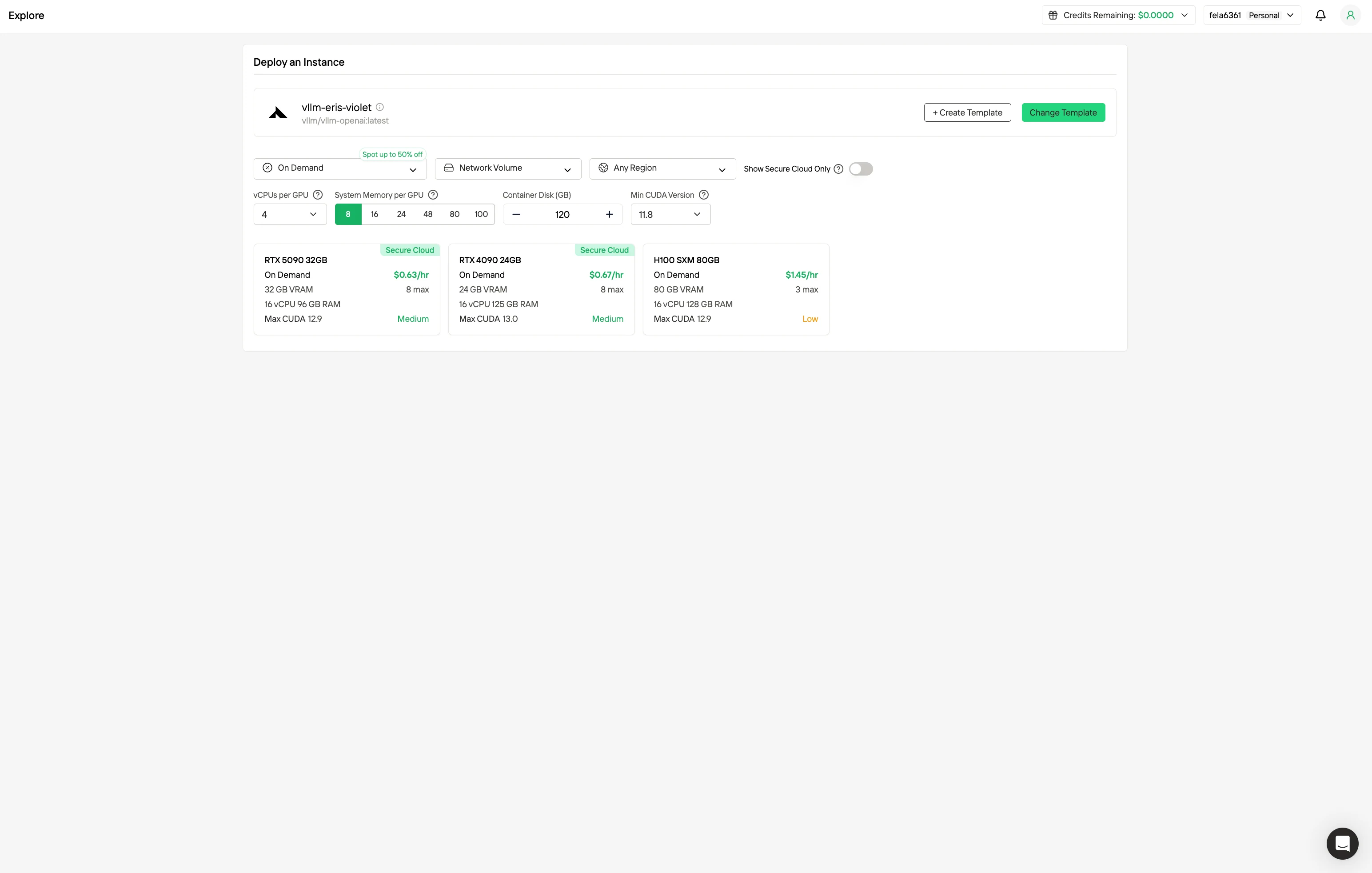
Step 2: Exploring Templates and GPU Servers
Choose from templates like PyTorch, TensorFlow, or CUDA that match your project needs. Then select your preferred GPU configuration—options include the powerful GPU, each with different VRAM, RAM, and storage specifications.
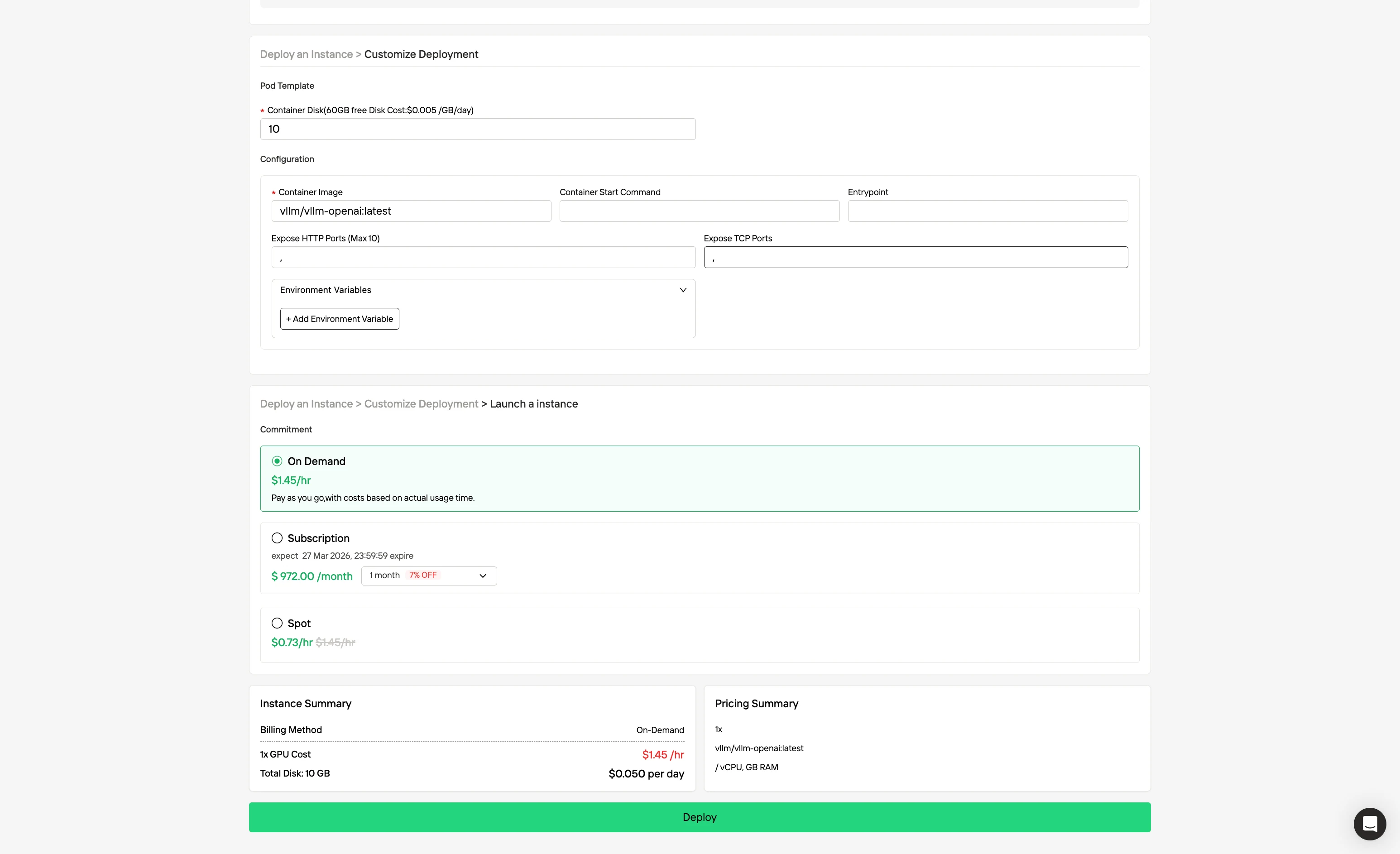
Step 3: Tailor Your Deployment
Customize your environment by selecting your preferred operating system and configuration options to ensure optimal performance for your specific AI workloads and development needs.
MiniMax M2.5’s 229B MoE architecture enables frontier coding performance, but demands minimum 96GB VRAM for 2-bit quantization or 128-160GB for production-quality 3-4 bit deployments. For most developers, API deployment at $0.30/$1.20 per 1M tokens offers the best cost-performance-simplicity balance up to 50M tokens/month.
Frequently Asked Questions
Can I run MiniMax M2.5 on a single RTX 4090?
No, MiniMax M2.5 requires minimum 74GB VRAM even at the most aggressive UD-IQ2_XXS 2-bit quantization. A single RTX 4090 has only 24GB VRAM. You need at least 3-4 consumer GPUs or 2×H100.
What quantization level maintains production-quality output for MiniMax M2.5?
Q4_K_M (138GB) or Dynamic 3-bit Q3_K_M (109GB) strike the best balance. Avoid Q2_K (83GB) for production — Reddit users report noticeable coding quality degradation despite higher context capacity.
How does MiniMax M2.5 API pricing work?
At Novita’s $0.30 / $1.20 per 1M tokens, processing 1M tokens per day costs about $45/month via API.
Novita AI is an AI & agent cloud platform helping developers and startups build, deploy, and scale models and agentic applications with high performance, reliability, and cost efficiency.
Recommended Reading



