

Can developers realistically deploy Qwen3.5-397B-A17B locally? The short answer: Not on consumer hardware in full precision. This massive 403.4B parameter multimodal MoE model requires 793GB VRAM in BF16, putting it firmly in enterprise cluster territory. For most developers, the Novita Severless API is the practical alternative — no hardware setup required.
Quick Answer: Full BF16 needs 10×H100 GPUs ($25.9/hr on Novita AI). For practical deployment, use 4-bit quantization on 2×H100 80GB. If you’re building a production app, start with Novita AI’s API at $0.60/$3.60 per 1M tokens.

VRAM Requirements of Qwen3.5-397B-A17B
| Precision | VRAM/RAM Required |
|---|---|
| BF16 (Full) | 793GB |
| Q8_0 | 422 GB |
| Q4_K_S | 228 GB |
| Q3_K_S | 164 GB |
Recommended GPU Configurations of Qwen3.5-397B-A17B
| Configuration | Precision | Cost (Novita AI) | Best For |
|---|---|---|---|
| 10×H100 SXM 80GB | BF16 | $25.9/hr on-demand, $13/hr spot | High-volume production (1M+ tokens/day) |
| 6×H100 SXM 80GB | Q8_0 | $15.54/hr on-demand, $7.8/hr spot | Medium-scale apps (100k-500k tokens/day) |
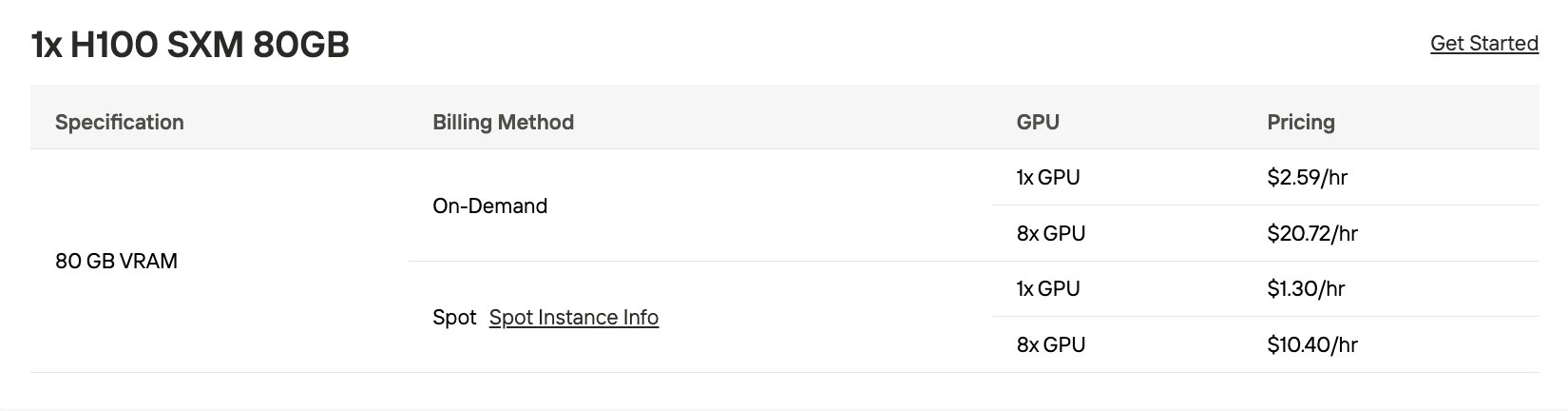
Multi-GPU Setup Requirements
Tensor parallelism is mandatory for multi-GPU deployment. Here’s what you need beyond raw VRAM:
- NVLink/NVSwitch: Required for efficient cross-GPU communication on H100/A100 setups. PCIe-only configurations will bottleneck at 15-20 tokens/sec regardless of GPU count.
- vLLM or TGI: Use vLLM’s tensor parallelism (
--tp 8) or Hugging Face Text Generation Inference for automatic model sharding. - Processing Ultra-Long Texts: Qwen3.5 natively supports context lengths of up to 262,144 tokens. For long-horizon tasks where the total length (including both input and output) exceeds this limit, we recommend using RoPE scaling techniques to handle long texts effectively, e.g., YaRN. YaRN is currently supported by several inference frameworks, e.g., transformers, vllm and sglang. You can enable it by modifying the
rope_parametersfields inconfig.json:
{"mrope_interleaved": true, "mrope_section": [11, 11, 10], "rope_type": "yarn", "rope_theta": 10000000, "partial_rotary_factor": 0.25, "factor": 4.0, "original_max_position_embeddings": 262144}
- Minimum 512GB system RAM: Needed for model loading, KV cache, and multimodal preprocessing (image/video tokenization).
Deployment Guide of Qwen3.5-397B-A17B
Step 1: Register an account
Create your Novita AI account through our website. After registration, navigate to the “Explore” section in the left sidebar to view our GPU offerings and begin your AI development journey.

Step 2: Exploring Templates and GPU Servers
Choose from templates like PyTorch, TensorFlow, or CUDA that match your project needs. Then select your preferred GPU configuration—options include the powerful GPU, each with different VRAM, RAM, and storage specifications.
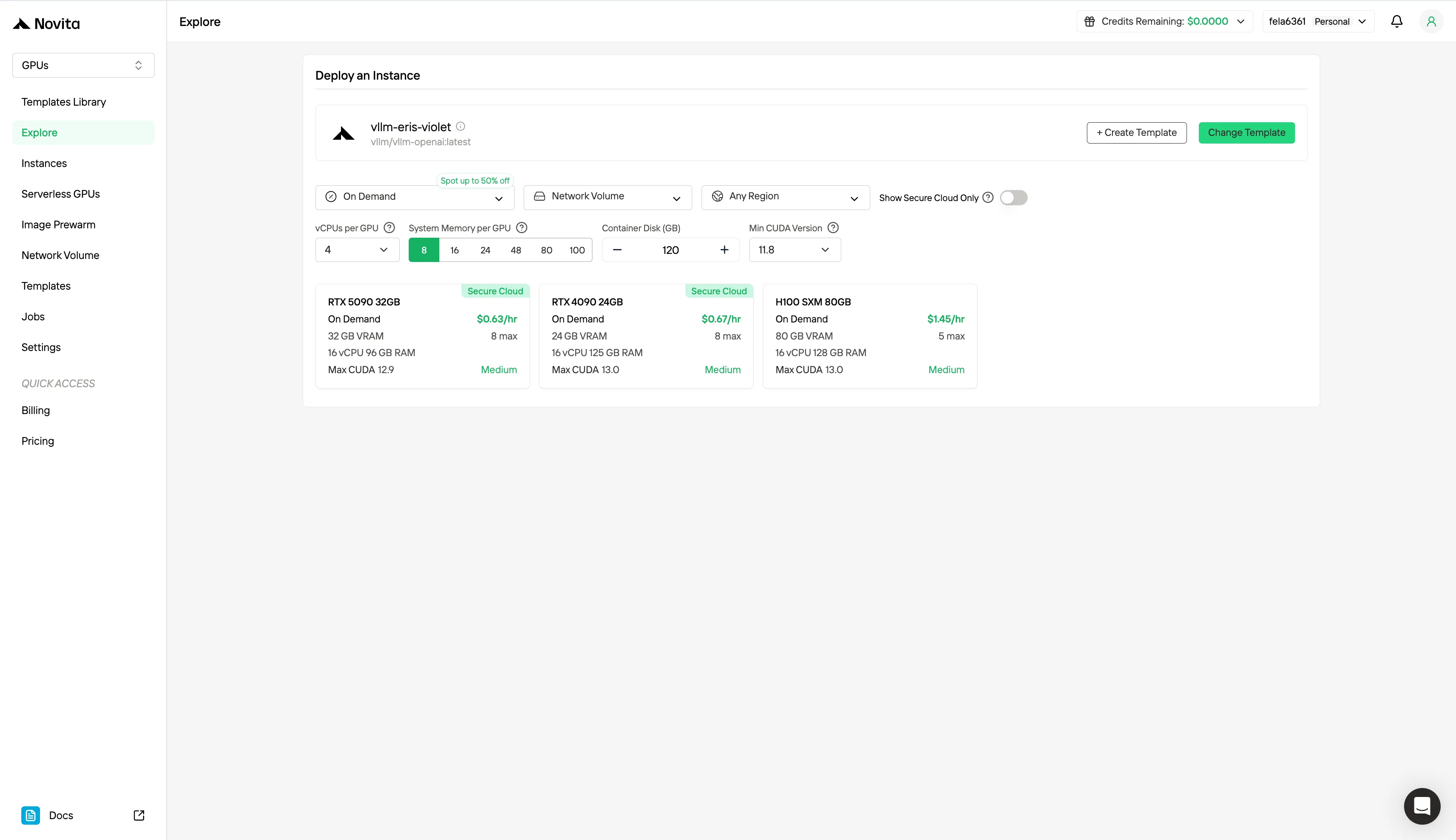
Step 3: Tailor Your Deployment
Customize your environment by selecting your preferred operating system and configuration options to ensure optimal performance for your specific AI workloads and development needs.
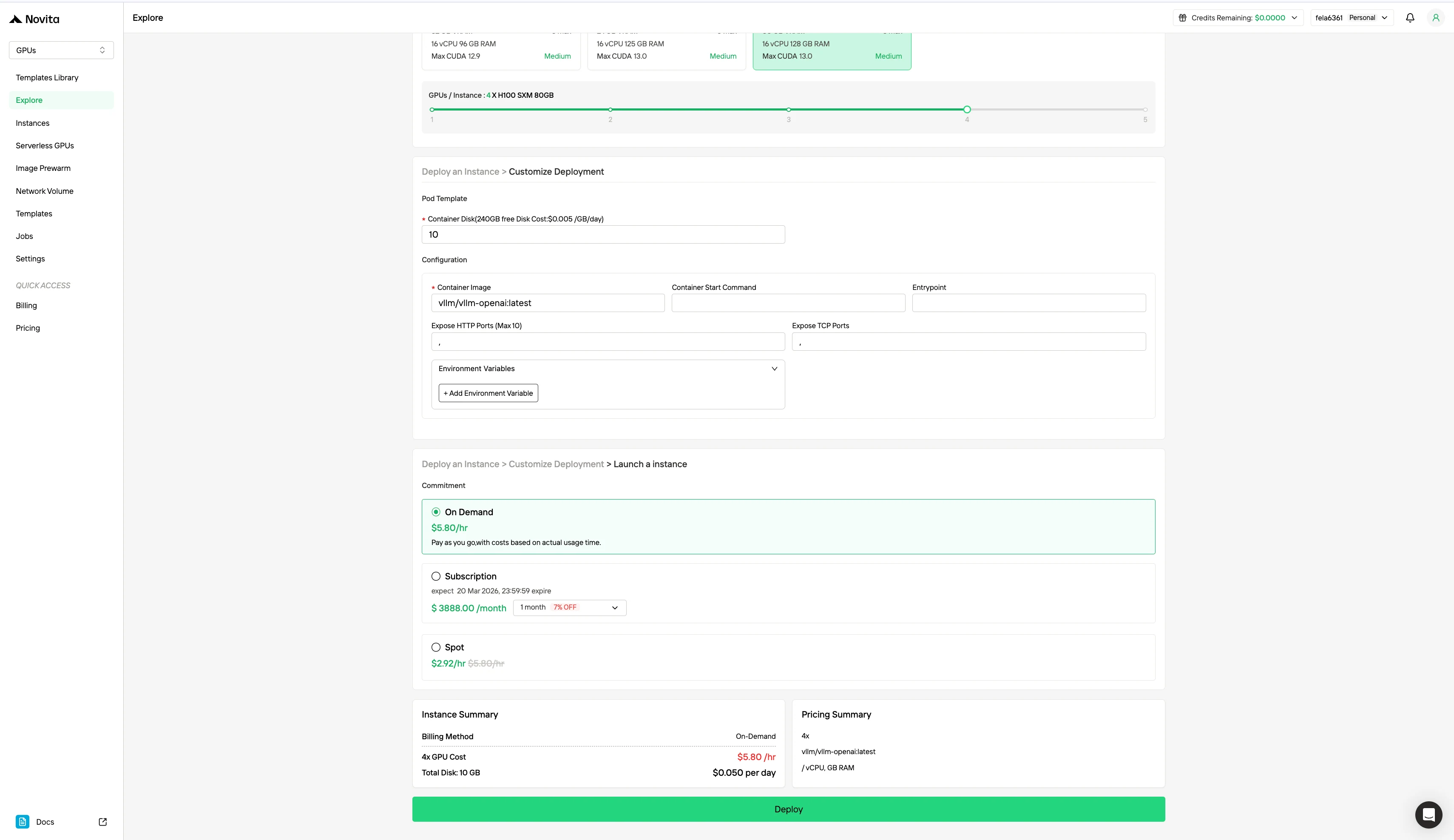
Besides the standard On-Demand pricing model, Novita AI also offers Spot mode, a significantly cheaper GPU option designed for cost-sensitive workloads. Unlike on-demand instances, which reserve dedicated hardware for stable, continuous usage, Spot instances are interruptible—your job may be paused or terminated if the GPU is reclaimed by the system. Because Spot mode reallocates otherwise unused GPU resources, it is typically 40–60% cheaper than on-demand pricing.
Common Deployment Gotchas
1. Context Length Overflow
Problem: Native 262k context is often insufficient for long-document RAG or video analysis. Exceeding it causes quality degradation.
Solution: Enable YaRN RoPE scaling to extend to 1M+ tokens:
YaRN is currently supported by several inference frameworks, e.g., transformers, vllm, ktransformers and sglang. In general, there are two approaches to enabling YaRN for supported frameworks:
- Modifying the model configuration file: In the
config.jsonfile, change therope_parametersfields intext_configto:
{
"mrope_interleaved": true,
"mrope_section": [
11,
11,
10
],
"rope_type": "yarn",
"rope_theta": 10000000,
"partial_rotary_factor": 0.25,
"factor": 4.0,
"original_max_position_embeddings": 262144,
}- Passing command line arguments:
For vllm, you can use
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve ... --hf-overrides '{"text_config": {"rope_parameters": {"mrope_interleaved": true, "mrope_section": [11, 11, 10], "rope_type": "yarn", "rope_theta": 10000000, "partial_rotary_factor": 0.25, "factor": 4.0, "original_max_position_embeddings": 262144}}}' --max-model-len 1010000For sglang and ktransformers, you can use
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server ... --json-model-override-args '{"text_config": {"rope_parameters": {"mrope_interleaved": true, "mrope_section": [11, 11, 10], "rope_type": "yarn", "rope_theta": 10000000, "partial_rotary_factor": 0.25, "factor": 4.0, "original_max_position_embeddings": 262144}}}' --context-length 10100002. Quantization Pitfalls
Problem: 3-bit GGUF may lose multimodal fidelity—vision-language tasks degrade noticeably.
Solution: Use INT4 GPTQ/AWQ for better balance. Always run vision benchmarks post-quantization before deploying.
3. NVLink Bottlenecks
Problem: Multi-GPU setups without NVLink hit PCIe bandwidth limits (15-20 tokens/sec ceiling).
Solution: Use H100/A100 with NVSwitch for 45+ tokens/sec throughput. Avoid consumer GPUs for production multi-GPU setups.
If you want to run Qwen3.5-397B-A17B locally: 10×H100 80GB with NVLink ($25.9/hr on-demand)
If that’s too expensive: Use Novita AI’s API at $0.60/$3.60 per 1M tokens with zero ops overhead.
Conclusion
Running Qwen3.5-397B-A17B locally is technically possible, but the hardware bar is extremely high — 793GB VRAM in BF16 puts it squarely in enterprise cluster territory. For most developers and teams, the Novita AI API delivers the same frontier-level performance at a fraction of the cost, with no infrastructure overhead. Whether you’re building agentic pipelines, running large-scale inference, or just exploring the model’s capabilities, the API path gets you there faster.
Frequently Asked Questions
Can I run Qwen3.5-397B-A17B on a single RTX 4090?
No. Even with 3-bit quantization, the model requires 165GB+ VRAM—the RTX 4090’s 24GB is insufficient by an order of magnitude.
What’s the minimum GPU configuration for production deployment?
10×H100 80GB in BF16 for full fidelity, or 6×H100 in INT8 for cost-optimized production. Anything smaller risks throughput bottlenecks or quality degradation on multimodal tasks.
How much does it cost to run Qwen3.5-397B-A17B for 1 million tokens?
Novita AI API: $4.20 per 1M tokens (blended input+output).
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing an affordable and reliable GPU cloud for building and scaling.
Recommended Reading



