

¿Pueden los desarrolladores implementar Qwen3.5-397B-A17B localmente de forma realista? La respuesta breve: No en hardware de consumo con precisión completa. Este enorme modelo MoE multimodal de 403.4 B parámetros requiere 793 GB de VRAM en BF16, lo que lo sitúa firmemente en el territorio de los clústeres empresariales. Para la mayoría de los desarrolladores, la API Novita Severless es la alternativa práctica, sin necesidad de configurar hardware.
Respuesta rápida: BF16 completo necesita 10×GPU H100 ($25.9/hora en Novita AI). Para una implementación práctica, usa cuantización de 4 bits en 2×H100 80GB. Si estás creando una aplicación de producción, comienza con la API de Novita AI a $0.60/$3.60 por 1M de tokens.
¡Prueba ahora una GPU rentable!

Requisitos de VRAM de Qwen3.5-397B-A17B
| Precisión | VRAM/RAM requerida |
|---|---|
| BF16 (completo) | 793 GB |
| Q8_0 | 422 GB |
| Q4_K_S | 228 GB |
| Q3_K_S | 164 GB |
Configuraciones recomendadas de GPU para Qwen3.5-397B-A17B
| Configuración | Precisión | Costo (Novita AI) | Mejor para |
|---|---|---|---|
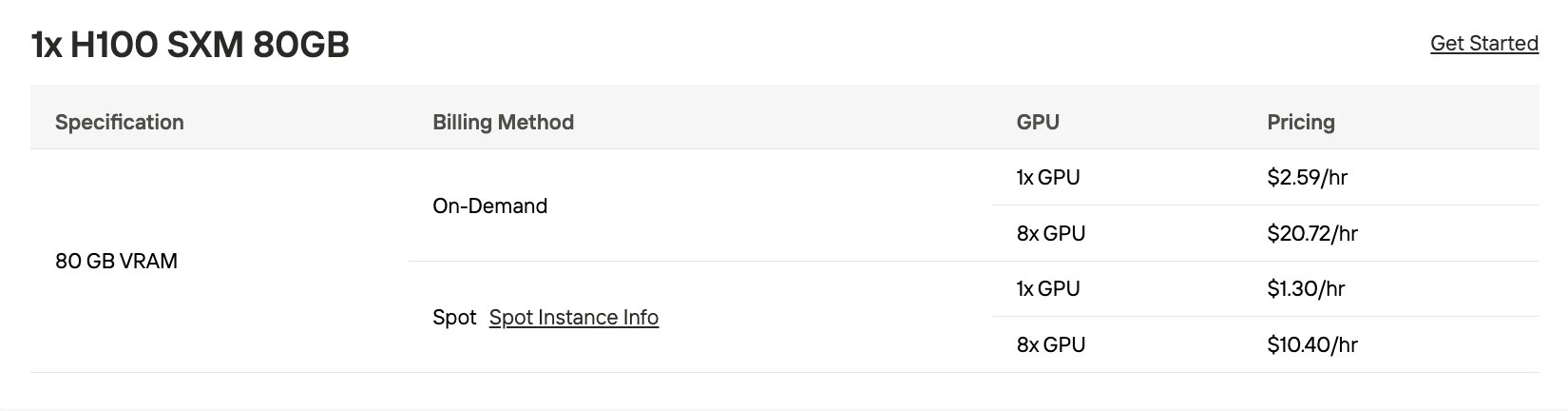
| 10×H100 SXM 80GB | BF16 | $25.9/hora bajo demanda, $13/hora spot | Producción de alto volumen (1M+ tokens/día) |
| 6×H100 SXM 80GB | Q8_0 | $15.54/hora bajo demanda, $7.8/hora spot | Aplicaciones de escala media (100k-500k tokens/día) |
¡Prueba ahora una GPU rentable!
Requisitos de configuración multigpu
El paralelismo tensorial es obligatorio para la implementación multigpu. Esto es lo que necesitas más allá de la VRAM bruta:
- NVLink/NVSwitch: Necesario para una comunicación eficiente entre GPUs en configuraciones H100/A100. Las configuraciones solo con PCIe se estancarán en 15-20 tokens/segundo independientemente de la cantidad de GPUs.
- vLLM o TGI: Usa el paralelismo tensorial de vLLM (
--tp 8) o Hugging Face Text Generation Inference para la fragmentación automática del modelo. - Procesamiento de textos ultralargos: Qwen3.5 admite de forma nativa longitudes de contexto de hasta 262 144 tokens. Para tareas de largo horizonte donde la longitud total (incluyendo entrada y salida) supera este límite, recomendamos usar técnicas de escalado RoPE para manejar textos largos de manera efectiva, por ejemplo, YaRN. YaRN es compatible actualmente con varios frameworks de inferencia, como transformers, vllm y sglang. Puedes habilitarlo modificando los campos
rope_parametersenconfig.json:
{"mrope_interleaved": true, "mrope_section": [11, 11, 10], "rope_type": "yarn", "rope_theta": 10000000, "partial_rotary_factor": 0.25, "factor": 4.0, "original_max_position_embeddings": 262144}
- Mínimo 512 GB de RAM del sistema: Necesaria para la carga del modelo, la caché KV y el preprocesamiento multimodal (tokenización de imágenes/video).
Guía de implementación de Qwen3.5-397B-A17B
Paso 1: Registra una cuenta
Crea tu cuenta en Novita AI a través de nuestro sitio web. Después del registro, navega a la sección «Explorar» en la barra lateral izquierda para ver nuestras ofertas de GPU y comienza tu viaje de desarrollo de IA.

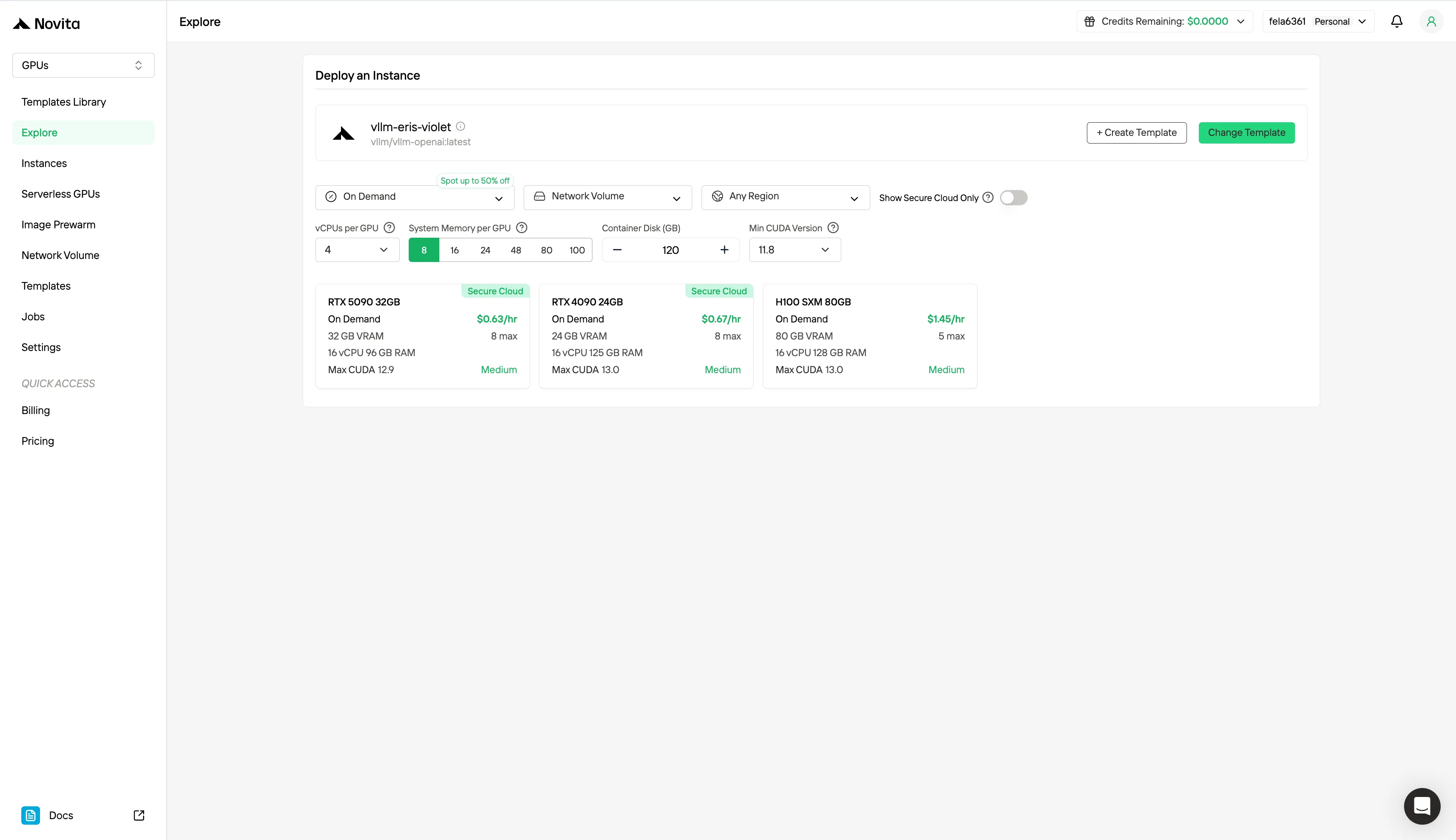
Paso 2: Explorar plantillas y servidores GPU
Elige entre plantillas como PyTorch, TensorFlow o CUDA que se ajusten a las necesidades de tu proyecto. Luego selecciona la configuración de GPU que prefieras: las opciones incluyen potentes GPU, cada una con diferentes especificaciones de VRAM, RAM y almacenamiento.
Paso 3: Personaliza tu implementación
Personaliza tu entorno seleccionando tu sistema operativo preferido y las opciones de configuración para garantizar un rendimiento óptimo para tus cargas de trabajo de IA específicas y necesidades de desarrollo.
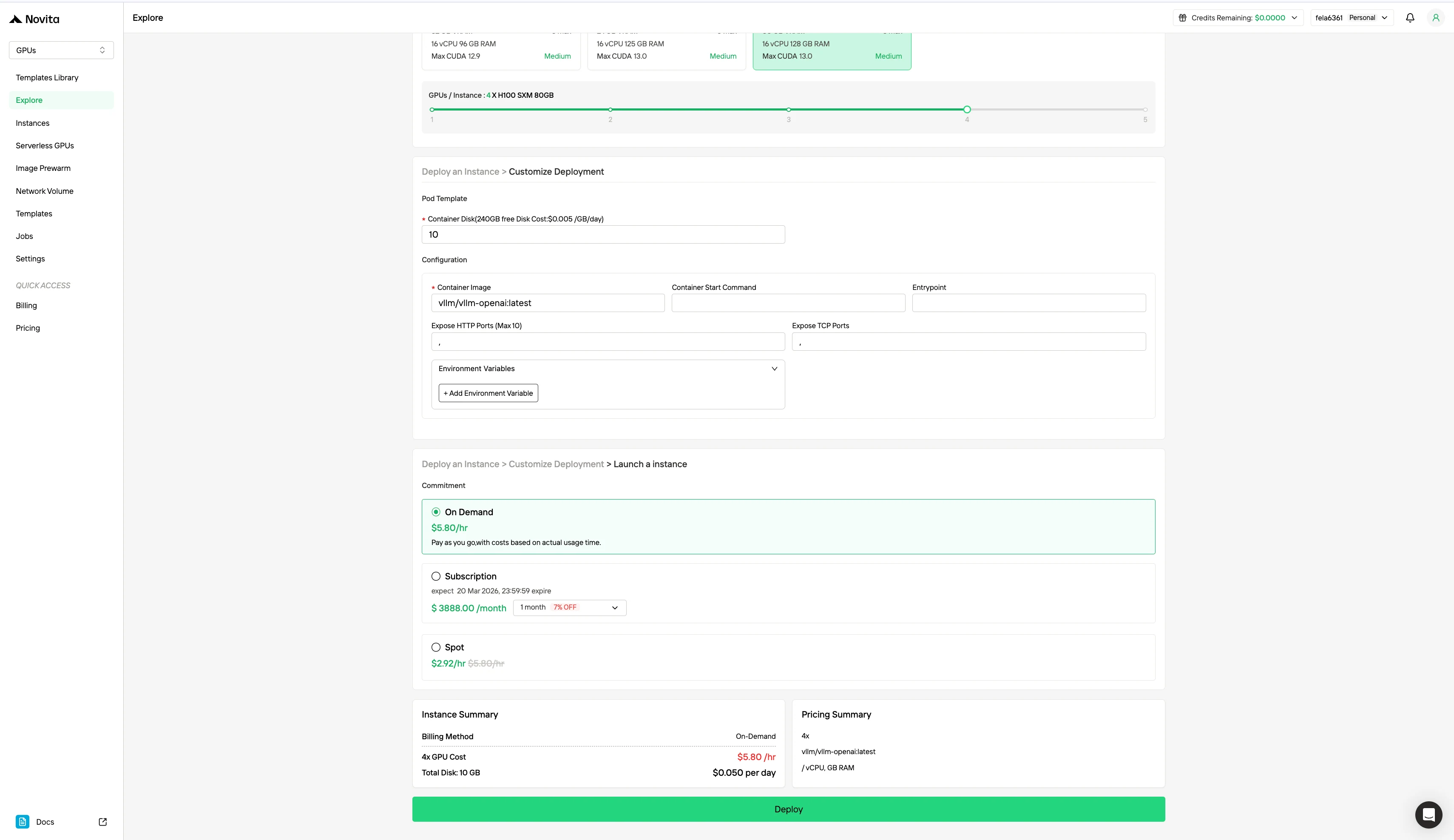
Además del modelo de precios estándar bajo demanda, Novita AI también ofrece modo Spot, una opción de GPU significativamente más económica diseñada para cargas de trabajo sensibles al costo. A diferencia de las instancias bajo demanda, que reservan hardware dedicado para un uso estable y continuo, las instancias Spot son interrumpibles: tu trabajo puede pausarse o finalizar si la GPU es reclamada por el sistema. Debido a que el modo Spot reasigna recursos GPU que de otro modo no se utilizarían, suele ser entre un 40 y un 60 % más barato que el precio bajo demanda.
Errores comunes en la implementación
1. Desbordamiento de la longitud de contexto
Problema: El contexto nativo de 262 k a menudo es insuficiente para RAG de documentos largos o análisis de video. Superarlo causa degradación de la calidad.
Solución: Habilita el escalado YaRN RoPE para extenderlo a 1 M+ tokens:
YaRN es compatible actualmente con varios frameworks de inferencia, como transformers, vllm, ktransformers y sglang. En general, hay dos enfoques para habilitar YaRN en frameworks compatibles:
- Modificar el archivo de configuración del modelo: En el archivo
config.json, cambia los camposrope_parametersentext_configa:
{
"mrope_interleaved": true,
"mrope_section": [
11,
11,
10
],
"rope_type": "yarn",
"rope_theta": 10000000,
"partial_rotary_factor": 0.25,
"factor": 4.0,
"original_max_position_embeddings": 262144,
}
- Pasar argumentos de línea de comandos:
Para vllm, puedes usar
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve ... --hf-overrides '{"text_config": {"rope_parameters": {"mrope_interleaved": true, "mrope_section": [11, 11, 10], "rope_type": "yarn", "rope_theta": 10000000, "partial_rotary_factor": 0.25, "factor": 4.0, "original_max_position_embeddings": 262144}}}' --max-model-len 1010000
Para sglang y ktransformers, puedes usar
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server ... --json-model-override-args '{"text_config": {"rope_parameters": {"mrope_interleaved": true, "mrope_section": [11, 11, 10], "rope_type": "yarn", "rope_theta": 10000000, "partial_rotary_factor": 0.25, "factor": 4.0, "original_max_position_embeddings": 262144}}}' --context-length 1010000
2. Problemas de cuantización
Problema: GGUF de 3 bits puede perder fidelidad multimodal: las tareas de lenguaje visual se degradan notablemente.
Solución: Usa INT4 GPTQ/AWQ para un mejor equilibrio. Siempre ejecuta benchmarks de visión después de la cuantización antes de implementar.
3. Cuellos de botella por NVLink
Problema: Las configuraciones multigpu sin NVLink alcanzan los límites de ancho de banda de PCIe (techo de 15-20 tokens/segundo).
Solución: Usa H100/A100 con NVSwitch para un rendimiento de 45+ tokens/segundo. Evita GPUs de consumo para configuraciones multigpu de producción.
Si deseas ejecutar Qwen3.5-397B-A17B localmente: 10×H100 80GB con NVLink ($25.9/hora bajo demanda)
Si es demasiado caro: Usa la API de Novita AI a $0.60/$3.60 por 1M de tokens sin gastos generales de operaciones.
Conclusión
Ejecutar Qwen3.5-397B-A17B localmente es técnicamente posible, pero la barrera de hardware es extremadamente alta: 793 GB de VRAM en BF16 lo sitúa directamente en el territorio de los clústeres empresariales. Para la mayoría de los desarrolladores y equipos, la API de Novita AI ofrece el mismo rendimiento de vanguardia a una fracción del costo, sin gastos generales de infraestructura. Ya sea que estés construyendo pipelines de agentes, ejecutando inferencia a gran escala o simplemente explorando las capacidades del modelo, el camino de la API te lleva allí más rápido.
¡Prueba ahora una GPU rentable!
Preguntas frecuentes
¿Puedo ejecutar Qwen3.5-397B-A17B en una sola RTX 4090?
No. Incluso con cuantización de 3 bits, el modelo requiere más de 165 GB de VRAM, los 24 GB de la RTX 4090 son insuficientes por un orden de magnitud.
¿Cuál es la configuración mínima de GPU para una implementación de producción?
10×H100 80GB en BF16 para fidelidad completa, o 6×H100 en INT8 para producción optimizada en costos. Cualquier configuración más pequeña corre el riesgo de cuellos de botella en el rendimiento o degradación de la calidad en tareas multimodales.
¿Cuánto cuesta ejecutar Qwen3.5-397B-A17B para 1 millón de tokens?
API de Novita AI: $4.20 por 1M de tokens (entrada+salida combinada).
Novita AI es una plataforma de nube de IA que ofrece a los desarrolladores una manera sencilla de implementar modelos de IA usando nuestra API simple, al mismo tiempo que proporciona un cloud de GPU asequible y confiable para construir y escalar.
Lecturas recomendadas



