

Können Entwickler Qwen3.5-397B-A17B realistisch lokal bereitstellen? Die kurze Antwort: Nicht auf Consumer-Hardware in voller Präzision. Dieses massive multimodale MoE-Modell mit 403,4 Milliarden Parametern benötigt 793 GB VRAM in BF16 – das liegt fest im Bereich von Unternehmensclustern. Für die meisten Entwickler ist die Novita Severless API die praktische Alternative – keine Hardwareeinrichtung erforderlich.
Kurze Antwort: Volles BF16 benötigt 10×H100-GPUs (25,90 $/Std. auf Novita AI). Für den praktischen Einsatz verwenden Sie 4-Bit-Quantisierung auf 2×H100 80GB. Wenn Sie eine Produktions-App erstellen, beginnen Sie mit der Novita AI API für 0,60 $/3,60 $ pro 1 M Token.
Jetzt kostengünstige GPU ausprobieren!

VRAM-Anforderungen von Qwen3.5-397B-A17B
| Präzision | Erforderlicher VRAM/RAM |
|---|---|
| BF16 (voll) | 793 GB |
| Q8_0 | 422 GB |
| Q4_K_S | 228 GB |
| Q3_K_S | 164 GB |
Empfohlene GPU-Konfigurationen von Qwen3.5-397B-A17B
| Konfiguration | Präzision | Kosten (Novita AI) | Am besten geeignet für |
|---|---|---|---|
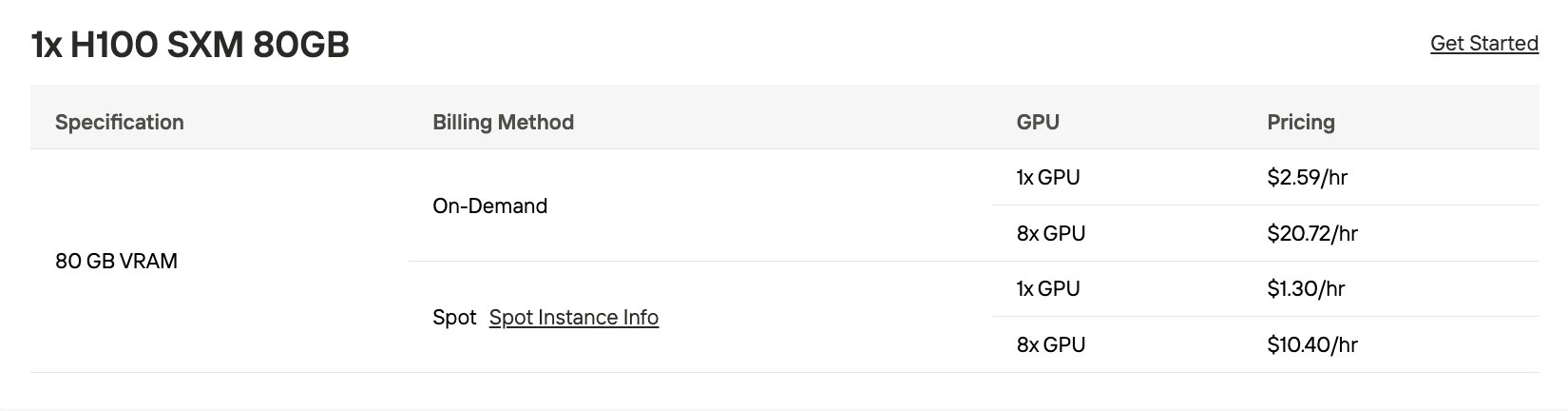
| 10×H100 SXM 80GB | BF16 | 25,90 $/Std. on-demand, 13 $/Std. spot | Großvolumige Produktion (1 M+ Token/Tag) |
| 6×H100 SXM 80GB | Q8_0 | 15,54 $/Std. on-demand, 7,80 $/Std. spot | Mittelgroße Anwendungen (100k–500k Token/Tag) |
Jetzt kostengünstige GPU ausprobieren!
Anforderungen für Multi-GPU-Setups
Tensor-Parallelität ist für den Multi-GPU-Einsatz zwingend erforderlich. Hier ist, was Sie über den reinen VRAM hinaus benötigen:
- NVLink/NVSwitch: Erforderlich für effiziente GPU-übergreifende Kommunikation bei H100/A100-Setups. Reine PCIe-Konfigurationen werden unabhängig von der GPU-Anzahl bei 15–20 Token/Sek. zum Engpass.
- vLLM oder TGI: Verwenden Sie die Tensor-Parallelität von vLLM (
--tp 8) oder Hugging Face Text Generation Inference für automatisches Modell-Sharding. - Verarbeitung extrem langer Texte: Qwen3.5 unterstützt nativ Kontextlängen von bis zu 262.144 Token. Für langfristige Aufgaben, bei denen die Gesamtlänge (einschließlich Eingabe und Ausgabe) diese Grenze überschreitet, empfehlen wir den Einsatz von RoPE-Skalierungstechniken zur effektiven Verarbeitung langer Texte, z. B. YaRN. YaRN wird derzeit von mehreren Inferenz-Frameworks unterstützt, z. B.
transformers,vllmundsglang. Sie können es aktivieren, indem Sie die Felderrope_parametersinconfig.jsonändern:
{"mrope_interleaved": true, "mrope_section": [11, 11, 10], "rope_type": "yarn", "rope_theta": 10000000, "partial_rotary_factor": 0.25, "factor": 4.0, "original_max_position_embeddings": 262144}
- Mindestens 512 GB Systemspeicher (RAM): Erforderlich zum Laden des Modells, für den KV-Cache und die multimodale Vorverarbeitung (Bild-/Video-Tokenisierung).
Bereitstellungsanleitung von Qwen3.5-397B-A17B
Schritt 1: Ein Konto registrieren
Erstellen Sie Ihr Novita AI-Konto über unsere Website. Navigieren Sie nach der Registrierung zum Bereich „Explore“ in der linken Seitenleiste, um unsere GPU-Angebote einzusehen und Ihre KI-Entwicklungsreise zu beginnen.

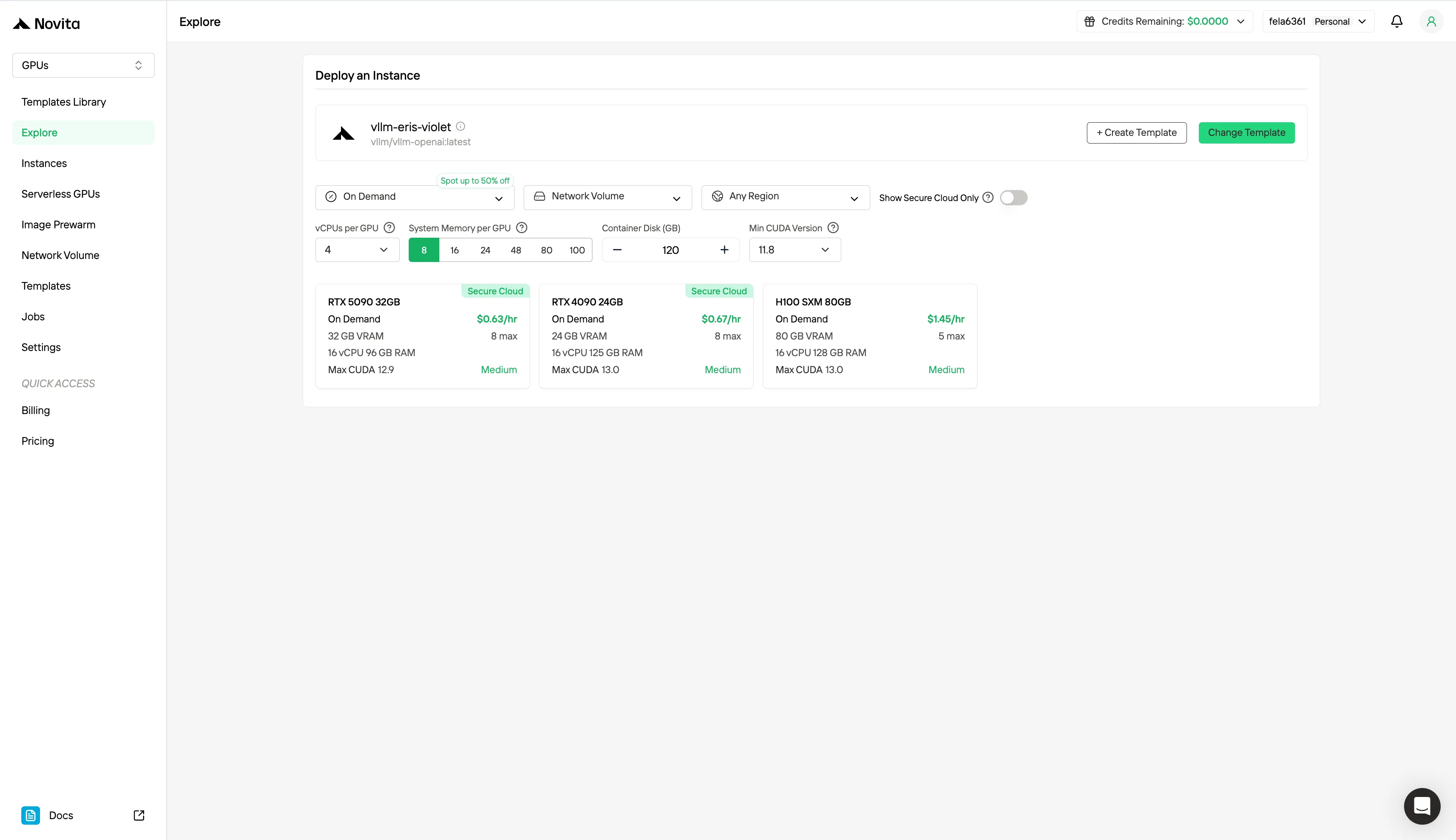
Schritt 2: Vorlagen und GPU-Server erkunden
Wählen Sie aus Vorlagen wie PyTorch, TensorFlow oder CUDA, die zu Ihren Projektanforderungen passen. Wählen Sie dann Ihre bevorzugte GPU-Konfiguration – Optionen umfassen die leistungsstarke GPU, jeweils mit unterschiedlichen VRAM-, RAM- und Speicherspezifikationen.
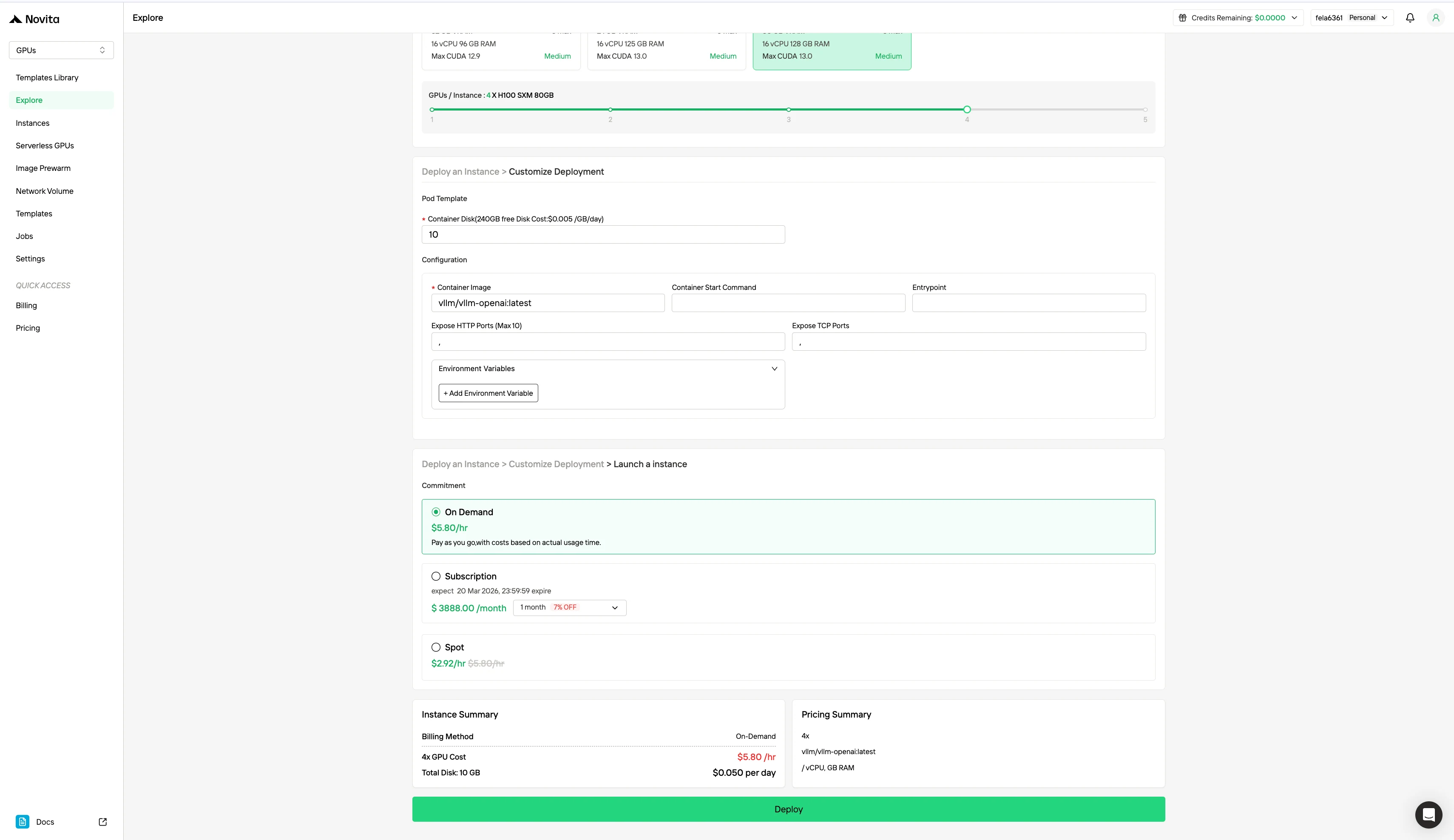
Schritt 3: Passen Sie Ihre Bereitstellung an
Passen Sie Ihre Umgebung an, indem Sie Ihr bevorzugtes Betriebssystem und Konfigurationsoptionen auswählen, um eine optimale Leistung für Ihre spezifischen KI-Workloads und Entwicklungsanforderungen sicherzustellen.
Jetzt kostengünstige GPU ausprobieren!
Neben dem standardmäßigen On-Demand-Preismodell bietet Novita AI auch den Spot-Modus an, eine deutlich günstigere GPU-Option für kostenbewusste Workloads. Im Gegensatz zu On-Demand-Instanzen, die dedizierte Hardware für stabile, kontinuierliche Nutzung reservieren, sind Spot-Instanzen unterbrechbar – Ihr Job kann angehalten oder beendet werden, wenn die GPU vom System zurückgefordert wird. Da der Spot-Modus ansonsten ungenutzte GPU-Ressourcen neu zuweist, ist er in der Regel 40–60 % günstiger als On-Demand-Preise.
Häufige Fallstricke bei der Bereitstellung
1. Kontextlängenüberlauf
Problem: Der native Kontext von 262k ist oft für langsame Dokumenten-RAG oder Videoanalyse unzureichend. Ein Überschreiten führt zu Qualitätseinbußen.
Lösung: Aktivieren Sie die YaRN-RoPE-Skalierung, um auf 1 M+ Token zu erweitern:
YaRN wird derzeit von mehreren Inferenz-Frameworks unterstützt, z. B. transformers, vllm, ktransformers und sglang. Allgemein gibt es zwei Ansätze, um YaRN für unterstützte Frameworks zu aktivieren:
- Ändern der Modellkonfigurationsdatei: Ändern Sie in der Datei
config.jsondie Felderrope_parametersintext_configauf:
{
"mrope_interleaved": true,
"mrope_section": [
11,
11,
10
],
"rope_type": "yarn",
"rope_theta": 10000000,
"partial_rotary_factor": 0.25,
"factor": 4.0,
"original_max_position_embeddings": 262144,
}
- Übergeben von Befehlszeilenargumenten:
Für vllm können Sie verwenden:
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve ... --hf-overrides '{"text_config": {"rope_parameters": {"mrope_interleaved": true, "mrope_section": [11, 11, 10], "rope_type": "yarn", "rope_theta": 10000000, "partial_rotary_factor": 0.25, "factor": 4.0, "original_max_position_embeddings": 262144}}}' --max-model-len 1010000
Für sglang und ktransformers können Sie verwenden:
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server ... --json-model-override-args '{"text_config": {"rope_parameters": {"mrope_interleaved": true, "mrope_section": [11, 11, 10], "rope_type": "yarn", "rope_theta": 10000000, "partial_rotary_factor": 0.25, "factor": 4.0, "original_max_position_embeddings": 262144}}}' --context-length 1010000
2. Quantisierungsfallen
Problem: 3-Bit-GGUF kann die multimodale Treue verlieren – Aufgaben mit Sprach und Bild verschlechtern sich merklich.
Lösung: Verwenden Sie INT4 GPTQ/AWQ für eine bessere Balance. Führen Sie vor der Bereitstellung immer Vision-Benchmarks nach der Quantisierung durch.
3. NVLink-Engpässe
Problem: Multi-GPU-Setups ohne NVLink erreichen die PCIe-Bandbreitengrenzen (Obergrenze von 15–20 Token/Sek.).
Lösung: Verwenden Sie H100/A100 mit NVSwitch für 45+ Token/Sek. Durchsatz. Vermeiden Sie Consumer-GPUs für produktive Multi-GPU-Setups.
Wenn Sie Qwen3.5-397B-A17B lokal ausführen möchten: 10×H100 80GB mit NVLink (25,90 $/Std. on-demand)
Wenn das zu teuer ist: Verwenden Sie die Novita AI API für 0,60 $/3,60 $ pro 1 M Token ohne Betriebsaufwand.
Fazit
Qwen3.5-397B-A17B lokal auszuführen ist technisch möglich, aber die Hardware-Hürde ist extrem hoch – 793 GB VRAM in BF16 liegt klar im Bereich von Unternehmensclustern. Für die meisten Entwickler und Teams liefert die Novita AI API die gleiche Spitzenleistung zu einem Bruchteil der Kosten und ohne Infrastrukturaufwand. Egal, ob Sie agentische Pipelines bauen, groß angelegte Inferenz durchführen oder einfach nur die Fähigkeiten des Modells erkunden – der API-Pfad bringt Sie schneller ans Ziel.
Jetzt kostengünstige GPU ausprobieren!
Häufig gestellte Fragen
Kann ich Qwen3.5-397B-A17B auf einer einzelnen RTX 4090 ausführen?
Nein. Selbst mit 3-Bit-Quantisierung benötigt das Modell 165 GB+ VRAM – die 24 GB der RTX 4090 sind um eine Größenordnung unzureichend.
Was ist die minimale GPU-Konfiguration für den Produktionseinsatz?
10×H100 80GB in BF16 für volle Wiedergabetreue oder 6×H100 in INT8 für kostenoptimierte Produktion. Alles Kleinere riskiert Durchsatzengpässe oder Qualitätseinbußen bei multimodalen Aufgaben.
Wie viel kostet es, Qwen3.5-397B-A17B für 1 Million Token auszuführen?
Novita AI API: 4,20 $ pro 1 M Token (gemischt Eingabe+Ausgabe).
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Erstellen und Skalieren bereitstellt.
Empfohlene Lektüre



