

Os desenvolvedores podem realmente implantar o Qwen3.5-397B-A17B localmente? A resposta curta: Não em hardware de consumo em precisão total. Este enorme modelo multimodal MoE de 403,4B parâmetros requer 793GB de VRAM em BF16, colocando-o firmemente no território de clusters empresariais. Para a maioria dos desenvolvedores, a API Novita Severless é a alternativa prática — sem necessidade de configuração de hardware.
Resposta Rápida: BF16 completo precisa de 10×H100 GPUs ($25,9/h na Novita AI). Para implantação prática, use quantização de 4 bits em 2×H100 80GB. Se você está construindo um aplicativo de produção, comece com a API da Novita AI a $0,60/$3,60 por 1M de tokens.
Experimente GPU com Custo Eficiente Agora!

Requisitos de VRAM do Qwen3.5-397B-A17B
| Precisão | VRAM/RAM Necessário |
|---|---|
| BF16 (Completo) | 793GB |
| Q8_0 | 422 GB |
| Q4_K_S | 228 GB |
| Q3_K_S | 164 GB |
Configurações de GPU Recomendadas para Qwen3.5-397B-A17B
| Configuração | Precisão | Custo (Novita AI) | Melhor Para |
|---|---|---|---|
| 10×H100 SXM 80GB | BF16 | $25,9/h on-demand, $13/h spot | Produção de alto volume (1M+ tokens/dia) |
| 6×H100 SXM 80GB | Q8_0 | $15,54/h on-demand, $7,8/h spot | Aplicativos de médio porte (100k-500k tokens/dia) |
Experimente GPU com Custo Eficiente Agora!
Requisitos de Configuração Multi-GPU
O paralelismo de tensor é obrigatório para implantação multi-GPU. Aqui está o que você precisa além da VRAM bruta:
- NVLink/NVSwitch: Obrigatório para comunicação eficiente entre GPUs em configurações H100/A100. Configurações apenas PCIe criarão gargalos de 15-20 tokens/s independentemente da quantidade de GPUs.
- vLLM ou TGI: Use o paralelismo de tensor do vLLM (
--tp 8) ou o Text Generation Inference da Hugging Face para sharding automático do modelo. - Processando Textos Ultra Longos: O Qwen3.5 suporta nativamente comprimentos de contexto de até 262.144 tokens. Para tarefas de longo horizonte onde o comprimento total (incluindo entrada e saída) excede esse limite, recomendamos usar técnicas de RoPE scaling para lidar eficazmente com textos longos, e.g., YaRN. O YaRN é atualmente suportado por vários frameworks de inferência, e.g., transformers, vllm e sglang. Você pode ativá-lo modificando os campos
rope_parametersnoconfig.json:
{"mrope_interleaved": true, "mrope_section": [11, 11, 10], "rope_type": "yarn", "rope_theta": 10000000, "partial_rotary_factor": 0.25, "factor": 4.0, "original_max_position_embeddings": 262144}
- Mínimo 512GB de RAM do sistema: Necessário para carregamento do modelo, cache KV e pré-processamento multimodal (tokenização de imagem/vídeo).
Guia de Implantação do Qwen3.5-397B-A17B
Passo 1: Crie uma conta
Crie sua conta Novita AI através do nosso site. Após o registro, navegue até a seção “Explorar” na barra lateral esquerda para ver nossas ofertas de GPU e começar sua jornada de desenvolvimento de IA.

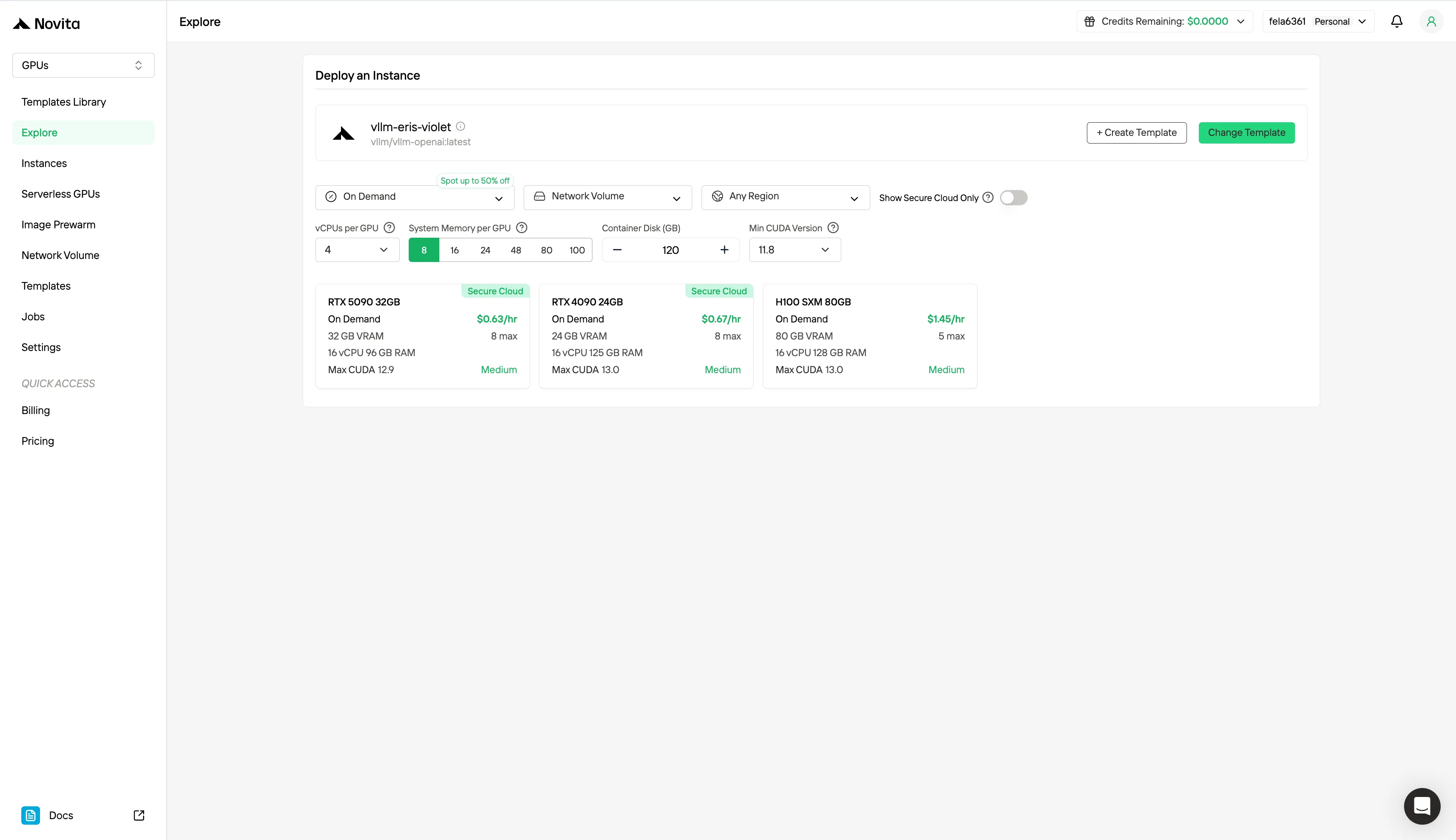
Passo 2: Explorando Templates e Servidores GPU
Escolha entre templates como PyTorch, TensorFlow ou CUDA que correspondam às necessidades do seu projeto. Em seguida, selecione sua configuração de GPU preferida—as opções incluem GPU potente, cada uma com diferentes especificações de VRAM, RAM e armazenamento.
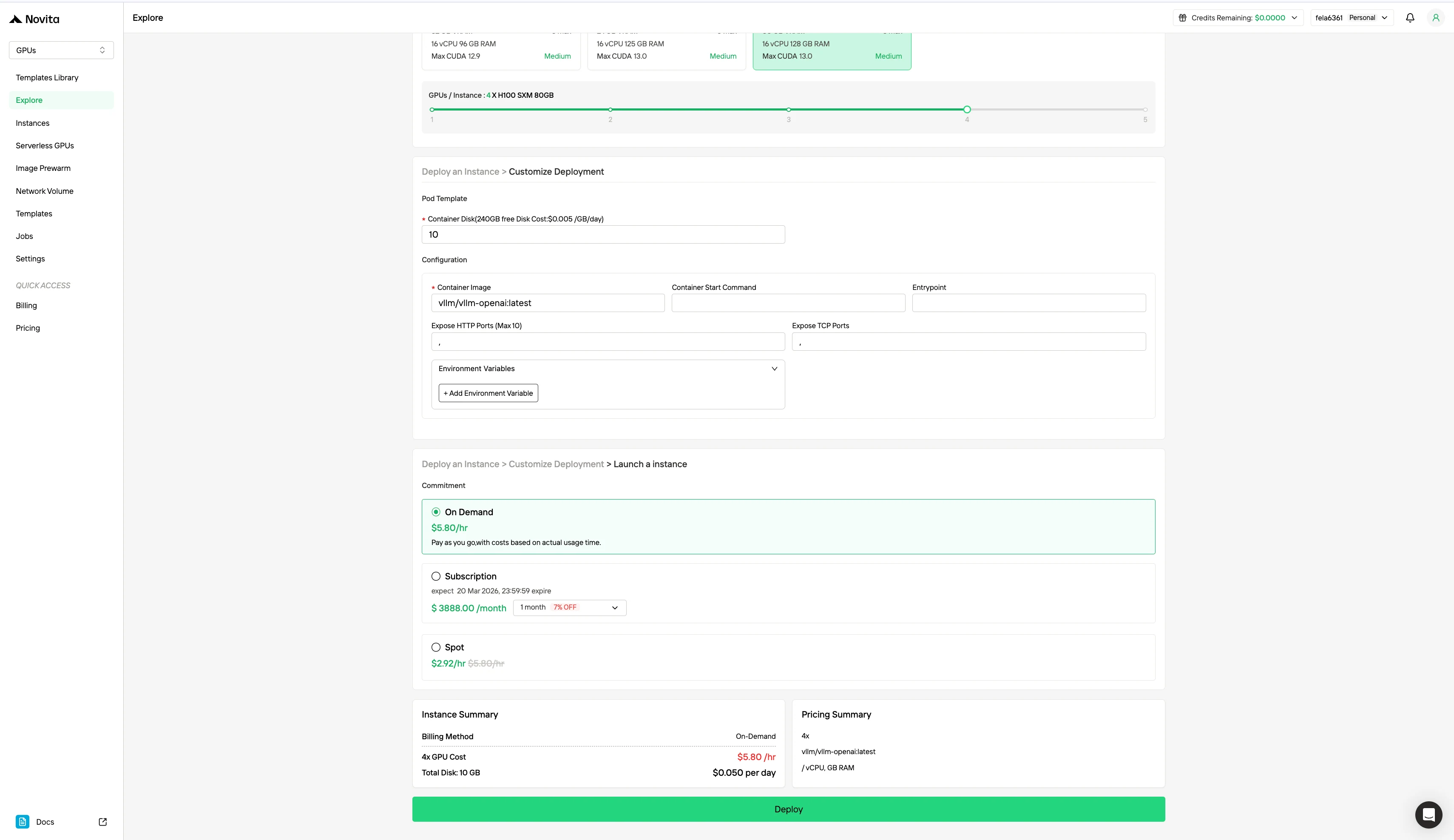
Passo 3: Personalize sua Implantação
Personalize seu ambiente selecionando seu sistema operacional preferido e opções de configuração para garantir o desempenho ideal para suas cargas de trabalho específicas de IA e necessidades de desenvolvimento.
Experimente GPU com Custo Eficiente Agora!
Além do modelo de precificação padrão On-Demand, a Novita AI também oferece o modo Spot, uma opção de GPU significativamente mais barata projetada para cargas de trabalho sensíveis a custo. Diferente das instâncias on-demand, que reservam hardware dedicado para uso estável e contínuo, as instâncias Spot são interrompíveis — seu trabalho pode ser pausado ou encerrado se a GPU for recuperada pelo sistema. Como o modo Spot realoca recursos de GPU que de outra forma não seriam utilizados, ele é tipicamente 40–60% mais barato que a precificação on-demand.
Armadilhas Comuns de Implantação
1. Estouro de Comprimento de Contexto
Problema: O contexto nativo de 262k é frequentemente insuficiente para RAG de documentos longos ou análise de vídeo. Excedê-lo causa degradação na qualidade.
Solução: Ative o YaRN RoPE scaling para estender para 1M+ tokens:
O YaRN é atualmente suportado por vários frameworks de inferência, e.g., transformers, vllm, ktransformers e sglang. Em geral, existem duas abordagens para ativar o YaRN em frameworks compatíveis:
- Modificando o arquivo de configuração do modelo: No arquivo
config.json, altere os camposrope_parametersemtext_configpara:
{
"mrope_interleaved": true,
"mrope_section": [
11,
11,
10
],
"rope_type": "yarn",
"rope_theta": 10000000,
"partial_rotary_factor": 0.25,
"factor": 4.0,
"original_max_position_embeddings": 262144,
}
- Passando argumentos de linha de comando:
Para vllm, você pode usar
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve ... --hf-overrides '{"text_config": {"rope_parameters": {"mrope_interleaved": true, "mrope_section": [11, 11, 10], "rope_type": "yarn", "rope_theta": 10000000, "partial_rotary_factor": 0.25, "factor": 4.0, "original_max_position_embeddings": 262144}}}' --max-model-len 1010000
Para sglang e ktransformers, você pode usar
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server ... --json-model-override-args '{"text_config": {"rope_parameters": {"mrope_interleaved": true, "mrope_section": [11, 11, 10], "rope_type": "yarn", "rope_theta": 10000000, "partial_rotary_factor": 0.25, "factor": 4.0, "original_max_position_embeddings": 262144}}}' --context-length 1010000
2. Armadilhas de Quantização
Problema: GGUF de 3 bits pode perder fidelidade multimodal — tarefas de visão-linguagem degradam-se visivelmente.
Solução: Use INT4 GPTQ/AWQ para um melhor equilíbrio. Sempre execute benchmarks de visão pós-quantização antes de implantar.
3. Gargalos de NVLink
Problema: Configurações multi-GPU sem NVLink encontram limites de largura de banda PCIe (teto de 15-20 tokens/s).
Solução: Use H100/A100 com NVSwitch para throughput de 45+ tokens/s. Evite GPUs de consumo para configurações multi-GPU de produção.
Se você deseja executar o Qwen3.5-397B-A17B localmente: 10×H100 80GB com NVLink ($25,9/h on-demand)
Se isso for muito caro: Use a API da Novita AI a $0,60/$3,60 por 1M de tokens com zero overhead operacional.
Conclusão
Executar o Qwen3.5-397B-A17B localmente é tecnicamente possível, mas a barreira de hardware é extremamente alta — 793GB VRAM em BF16 coloca-o firmemente no território de clusters empresariais. Para a maioria dos desenvolvedores e equipes, a API Novita AI oferece o mesmo desempenho de ponta a uma fração do custo, sem sobrecarga de infraestrutura. Seja construindo pipelines agentivos, executando inferência em larga escala ou apenas explorando as capacidades do modelo, o caminho da API leva você lá mais rápido.
Experimente GPU com Custo Eficiente Agora!
Perguntas Frequentes
Posso executar o Qwen3.5-397B-A17B em uma única RTX 4090?
Não. Mesmo com quantização de 3 bits, o modelo requer 165GB+ de VRAM — os 24GB da RTX 4090 são insuficientes por uma ordem de grandeza.
Qual é a configuração mínima de GPU para implantação em produção?
10×H100 80GB em BF16 para fidelidade total, ou 6×H100 em INT8 para produção otimizada em custo. Qualquer coisa menor corre o risco de gargalos de throughput ou degradação de qualidade em tarefas multimodais.
Quanto custa executar o Qwen3.5-397B-A17B para 1 milhão de tokens?
API Novita AI: $4,20 por 1M de tokens (média de entrada+saída).
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construir e escalar.
Leitura Recomendada



