

هل يمكن للمطورين نشر Qwen3.5-397B-A17B محليًا بشكل واقعي؟ الإجابة المختصرة: ليس على الأجهزة الاستهلاكية بدقة كاملة. هذا النموذج MoE المتعدد الوسائط الضخم الذي يحتوي على 403.4 مليار معلمة يتطلب 793 غيغابايت من VRAM بدقة BF16، مما يضعه بقوة في نطاق مجموعات المؤسسات. بالنسبة لمعظم المطورين، تعتبر Novita Severless API البديل العملي — لا حاجة لإعداد الأجهزة.
إجابة سريعة: BF16 الكامل يحتاج إلى 10 × H100 GPU (25.9 دولارًا/ساعة على Novita AI). للنشر العملي، استخدم تكميم 4 بت على 2 × H100 80GB. إذا كنت تبني تطبيق إنتاج، ابدأ باستخدام Novita AI API مقابل 0.60/3.60 دولار لكل مليون رمز.

متطلبات VRAM لـ Qwen3.5-397B-A17B
| الدقة | VRAM/ذاكرة الوصول العشوائي المطلوبة |
|---|---|
| BF16 (كامل) | 793 غيغابايت |
| Q8_0 | 422 غيغابايت |
| Q4_K_S | 228 غيغابايت |
| Q3_K_S | 164 غيغابايت |
تكوينات GPU الموصى بها لـ Qwen3.5-397B-A17B
| التكوين | الدقة | التكلفة (Novita AI) | الأفضل لـ |
|---|---|---|---|
| 10×H100 SXM 80GB | BF16 | 25.9 دولارًا/ساعة حسب الطلب، 13 دولارًا/ساعة (سبوت) | الإنتاج عالي الحجم (أكثر من مليون رمز/يوم) |
| 6×H100 SXM 80GB | Q8_0 | 15.54 دولارًا/ساعة حسب الطلب، 7.8 دولارًا/ساعة (سبوت) | التطبيقات متوسطة الحجم (100k-500k رمز/يوم) |
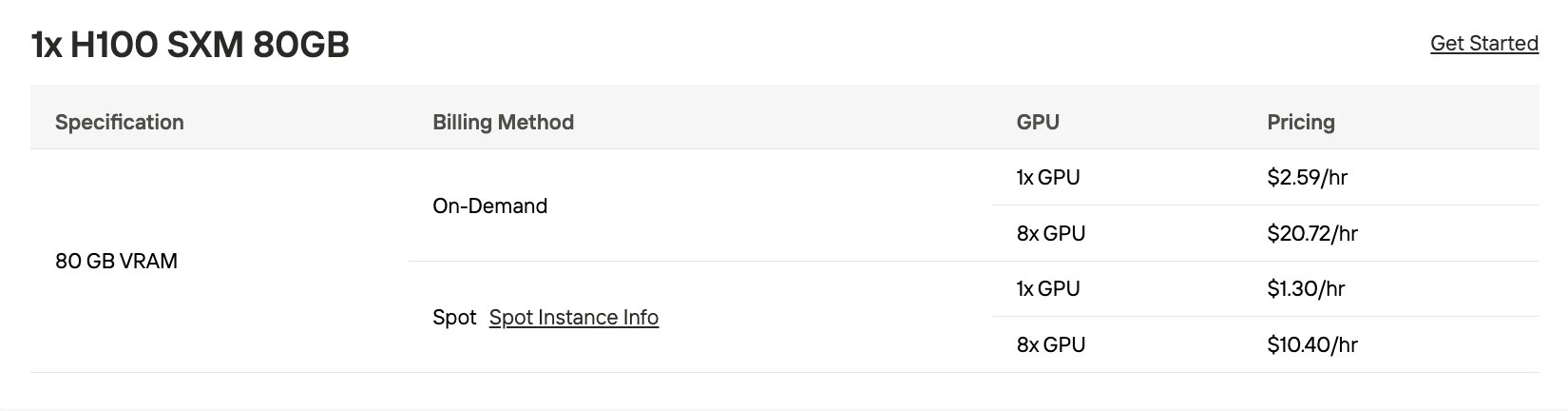
متطلبات إعداد GPU متعدد
التوازي الموتر (Tensor parallelism) إلزامي لنشر GPU متعدد. إليك ما تحتاجه بجانب VRAM الخام:
- NVLink/NVSwitch: مطلوب للاتصال الفعال بين وحدات GPU في إعدادات H100/A100. التكوينات التي تعتمد فقط على PCIe ستواجه عنق زجاجة بسرعة 15-20 رمزًا/ثانية بغض النظر عن عدد وحدات GPU.
- vLLM أو TGI: استخدم التوازي الموتر في vLLM (
--tp 8) أو Hugging Face Text Generation Inference لتقسيم النموذج تلقائيًا. - معالجة النصوص الطويلة جدًا: يدعم Qwen3.5 أصلاً أطوال سياق تصل إلى 262,144 رمزًا. للمهام طويلة الأمد حيث يتجاوز الطول الإجمالي (بما في ذلك الإدخال والإخراج) هذا الحد، نوصي باستخدام تقنيات تحجيم RoPE (مثل YaRN) للتعامل مع النصوص الطويلة بشكل فعال. تدعم العديد من أطر الاستدلال YaRN حاليًا، مثل
transformersوvllmوsglang. يمكنك تمكينها بتعديل حقولrope_parametersفي ملفconfig.json:
{"mrope_interleaved": true, "mrope_section": [11, 11, 10], "rope_type": "yarn", "rope_theta": 10000000, "partial_rotary_factor": 0.25, "factor": 4.0, "original_max_position_embeddings": 262144}
- 512 غيغابايت على الأقل من ذاكرة الوصول العشوائي للنظام: مطلوب لتحميل النموذج، وذاكرة التخزين المؤقت KV، والمعالجة المسبقة للوسائط المتعددة (ترميز الصور/الفيديو).
دليل النشر لـ Qwen3.5-397B-A17B
الخطوة 1: إنشاء حساب
أنشئ حسابك على Novita AI من خلال موقعنا الإلكتروني. بعد التسجيل، انتقل إلى قسم “Explore” في الشريط الجانبي الأيسر لعرض عروض GPU وابدأ رحلتك في تطوير الذكاء الاصطناعي.

الخطوة 2: استكشاف القوالب وخوادم GPU
اختر من بين القوالب مثل PyTorch أو TensorFlow أو CUDA التي تناسب احتياجات مشروعك. ثم حدد تكوين GPU المفضل لديك — تتضمن الخيارات GPU القوي، مع مواصفات مختلفة من VRAM والذاكرة والتخزين.
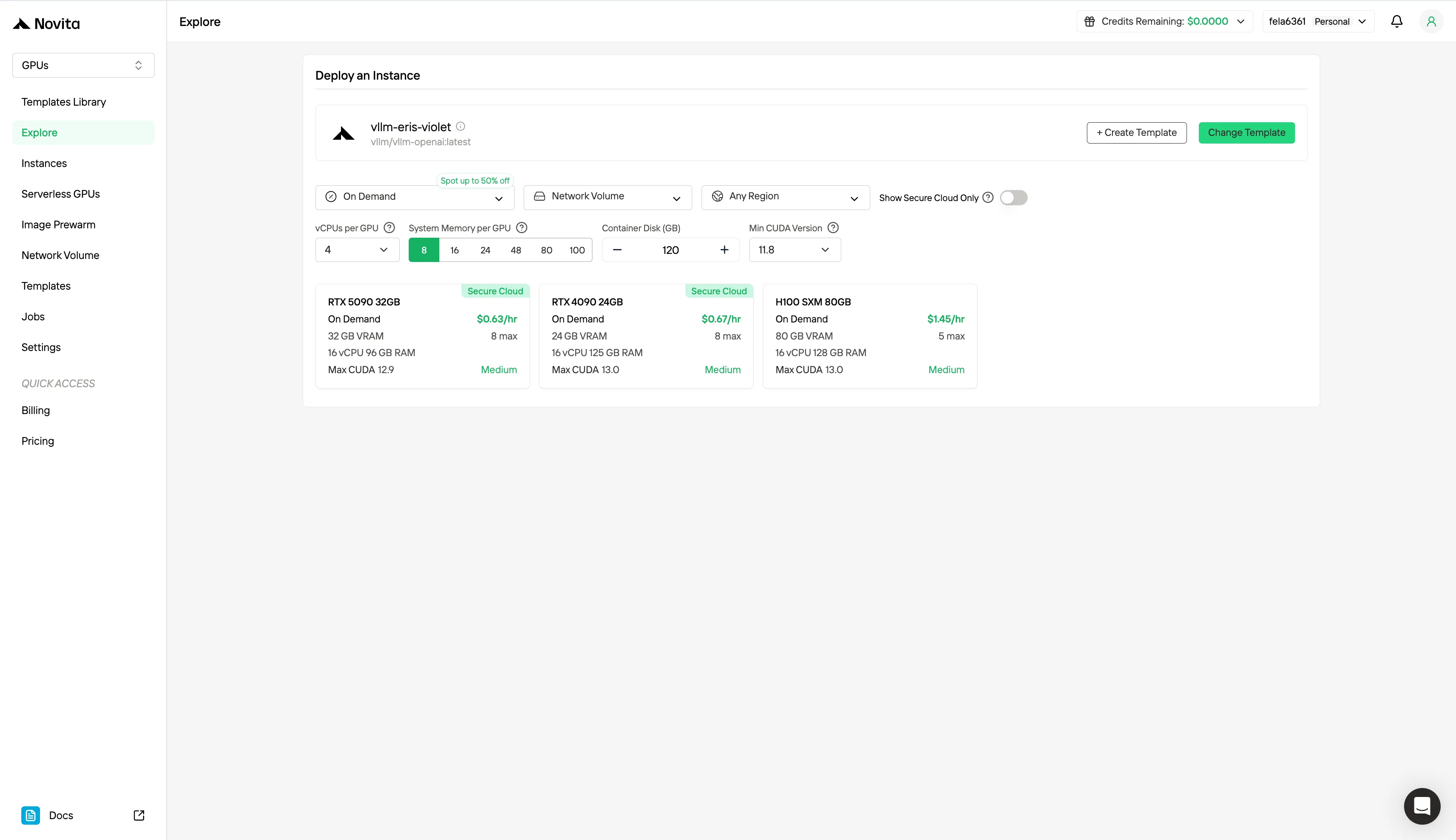
الخطوة 3: تخصيص النشر الخاص بك
خصص بيئتك عن طريق اختيار نظام التشغيل المفضل وخيارات التكوين لضمان الأداء الأمثل لأعباء عمل الذكاء الاصطناعي واحتياجات التطوير الخاصة بك.
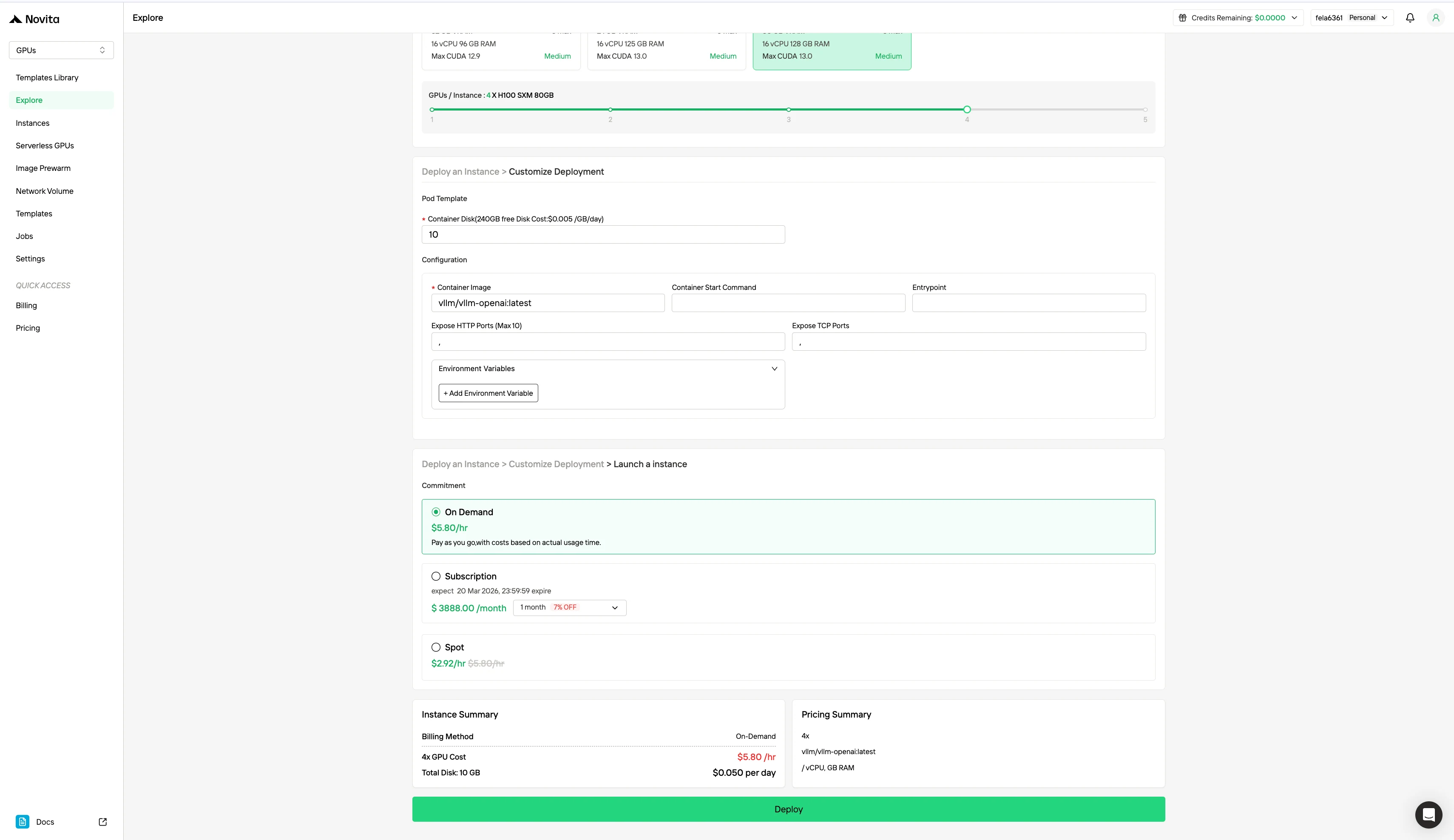
بالإضافة إلى نموذج التسعير القياسي حسب الطلب (On-Demand)، تقدم Novita AI أيضًا وضع Spot، وهو خيار GPU أرخص بكثير مصمم لأعباء العمل الحساسة للتكلفة. على عكس الحالات حسب الطلب التي تحجز أجهزة مخصصة للاستخدام المستقر والمستمر، فإن حالات Spot قابلة للمقاطعة — قد يتم إيقاف مهمتك أو إنهاؤها إذا تم استعادة GPU بواسطة النظام. نظرًا لأن وضع Spot يعيد تخصيص موارد GPU غير المستخدمة، فإنه عادةً ما يكون أرخص بنسبة 40-60% من التسعير حسب الطلب.
المشكلات الشائعة في النشر
1. تجاوز طول السياق
المشكلة: سياق 262k الأصلي غالبًا غير كافٍ لـ RAG المستندات الطويلة أو تحليل الفيديو. تجاوزه يؤدي إلى تدهور الجودة.
الحل: قم بتمكين تحجيم YaRN RoPE لتوسيع النطاق إلى أكثر من مليون رمز:
YaRN مدعوم حاليًا من قبل العديد من أطر الاستدلال، مثل transformers وvllm وktransformers وsglang. بشكل عام، هناك طريقتان لتمكين YaRN للأطر المدعومة:
- تعديل ملف تكوين النموذج: في ملف
config.json، قم بتغيير حقولrope_parametersفيtext_configإلى:
{
"mrope_interleaved": true,
"mrope_section": [
11,
11,
10
],
"rope_type": "yarn",
"rope_theta": 10000000,
"partial_rotary_factor": 0.25,
"factor": 4.0,
"original_max_position_embeddings": 262144,
}
- تمرير وسائط سطر الأوامر:
لـ vllm، يمكنك استخدام
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve ... --hf-overrides '{"text_config": {"rope_parameters": {"mrope_interleaved": true, "mrope_section": [11, 11, 10], "rope_type": "yarn", "rope_theta": 10000000, "partial_rotary_factor": 0.25, "factor": 4.0, "original_max_position_embeddings": 262144}}}' --max-model-len 1010000
لـ sglang وktransformers، يمكنك استخدام
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server ... --json-model-override-args '{"text_config": {"rope_parameters": {"mrope_interleaved": true, "mrope_section": [11, 11, 10], "rope_type": "yarn", "rope_theta": 10000000, "partial_rotary_factor": 0.25, "factor": 4.0, "original_max_position_embeddings": 262144}}}' --context-length 1010000
2. مخاطر التكميم
المشكلة: قد يفقد GGUF بدقة 3 بت الدقة متعددة الوسائط — تتدهور مهام الرؤية واللغة بشكل ملحوظ.
الحل: استخدم INT4 GPTQ/AWQ للحصول على توازن أفضل. قم دائمًا بتشغيل معايير الرؤية بعد التكميم قبل النشر.
3. اختناقات NVLink
المشكلة: إعدادات GPU المتعددة بدون NVLink تواجه حدود عرض نطاق PCIe (سقف 15-20 رمزًا/ثانية).
الحل: استخدم H100/A100 مع NVSwitch لتحقيق إنتاجية 45+ رمزًا/ثانية. تجنب وحدات GPU الاستهلاكية لإعدادات GPU متعددة في الإنتاج.
إذا كنت ترغب في تشغيل Qwen3.5-397B-A17B محليًا: 10 × H100 80GB مع NVLink (25.9 دولارًا/ساعة حسب الطلب)
إذا كان ذلك مكلفًا جدًا: استخدم Novita AI API مقابل 0.60/3.60 دولار لكل مليون رمز مع عدم وجود تكاليف تشغيلية.
استنتاج
تشغيل Qwen3.5-397B-A17B محليًا ممكن تقنيًا، لكن حاجز الأجهزة مرتفع جدًا — 793 غيغابايت من VRAM بدقة BF16 تضعه بقوة في نطاق مجموعات المؤسسات. بالنسبة لمعظم المطورين والفرق، توفر Novita AI API نفس الأداء المتطور بجزء صغير من التكلفة، دون أعباء البنية التحتية. سواء كنت تبني خطوط أنابيب وكيلة، أو تدير استدلالًا واسع النطاق، أو تستكشف فقط قدرات النموذج، فإن مسار API يوصلك إلى هناك بشكل أسرع.
أسئلة شائعة
هل يمكنني تشغيل Qwen3.5-397B-A17B على RTX 4090 واحد؟
لا. حتى مع تكميم 3 بت، يتطلب النموذج أكثر من 165 غيغابايت من VRAM — VRAM سعة 24 غيغابايت في RTX 4090 غير كافية بمرتبة من الحجم.
ما هو الحد الأدنى لتكوين GPU للنشر في الإنتاج؟
10 × H100 80GB بدقة BF16 للحصول على دقة كاملة، أو 6 × H100 بدقة INT8 للإنتاج المحسن من حيث التكلفة. أي شيء أصغر قد يسبب اختناقات في الإنتاجية أو تدهور الجودة في المهام متعددة الوسائط.
كم تكلفة تشغيل Qwen3.5-397B-A17B لمليون رمز؟
Novita AI API: 4.20 دولارًا لكل مليون رمز (مزيج إدخال+إخراج).
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام API البسيط، مع توفير سحابة GPU موثوقة وبأسعار معقولة لبناء وتوسيع النطاق.
قراءات موصى بها



