

Google’s Gemma 4 is now available on Novita AI. The two larger models — 31B and 26B A4B — are live on the Model API. All four sizes, including the on-device E2B and E4B, are deployable via GPU Application: Novita AI’s one-click model deployment product where you pick a model, launch an instance, and you’re running.
This article covers what Gemma 4 actually is, how the architectures differ, and what each size is built for — so you can choose the right access path before you start building.
What Is Gemma 4?
Gemma 4 is Google’s fourth-generation open model family, built across three different architectures optimized for different memory and performance targets. The lineup covers everything from on-device inference to server-grade deployments, with each architecture designed around specific memory footprint and performance targets.
The four model sizes are:
| Model | Architecture | Parameters | Context | Modalities |
|---|---|---|---|---|
| Gemma 4 E2B | Dense (small) | 2.3B effective, 5.1B with embeddings | 128K | Text, Vision, Audio |
| Gemma 4 E4B | Dense (small) | 4.5B effective, 7.9B with embeddings | 128K | Text, Vision, Audio |
| Gemma 4 26B A4B | MoE | 4B active / 26B total | 256K | Text, Vision |
| Gemma 4 31B | Dense | 31B | 256K | Text, Vision |
All four sizes include instruction-tuned (-it) variants alongside base pre-trained checkpoints.
How the Three Architectures Work
Dense architecture (31B): built for long-context quality
The 31B model is the flagship dense architecture. It extends the Gemma baseline with architectural changes that improve efficiency and long-context quality.
MoE architecture (26B A4B): high capability, fixed memory footprint
The 26B A4B model uses a Mixture of Experts (MoE) design with 128 total experts — a high number of small experts — plus a single shared expert that is always active. Only 8 experts are activated per forward pass, yielding 3.8B active parameters out of 26.8B total.
The design targets memory footprints that can run on high-end laptops and server architectures with quantization applied. Quantization-aware training (QAT) checkpoints — Q3-2, Q3-0, and Q4-0 — are provided, enabling high-quality inference at reduced memory footprints.
Small architecture (E2B and E4B): on-device with real throughput
The E2B and E4B models are purpose-built for on-device inference. The design starts from the Gemma 4 dense base and adds selected innovations from Gemma 3n to increase tokens per second, reduce prefill time, and broaden compatibility across devices, frameworks, and runtimes.
Two key features carry over from Gemma 3n:
- Per-Layer Embeddings (PLE): retained from Gemma 3n
- KV-Cache Sharing: reduces both prefill time and KV-cache memory size with minimal quality impact
Key Capabilities
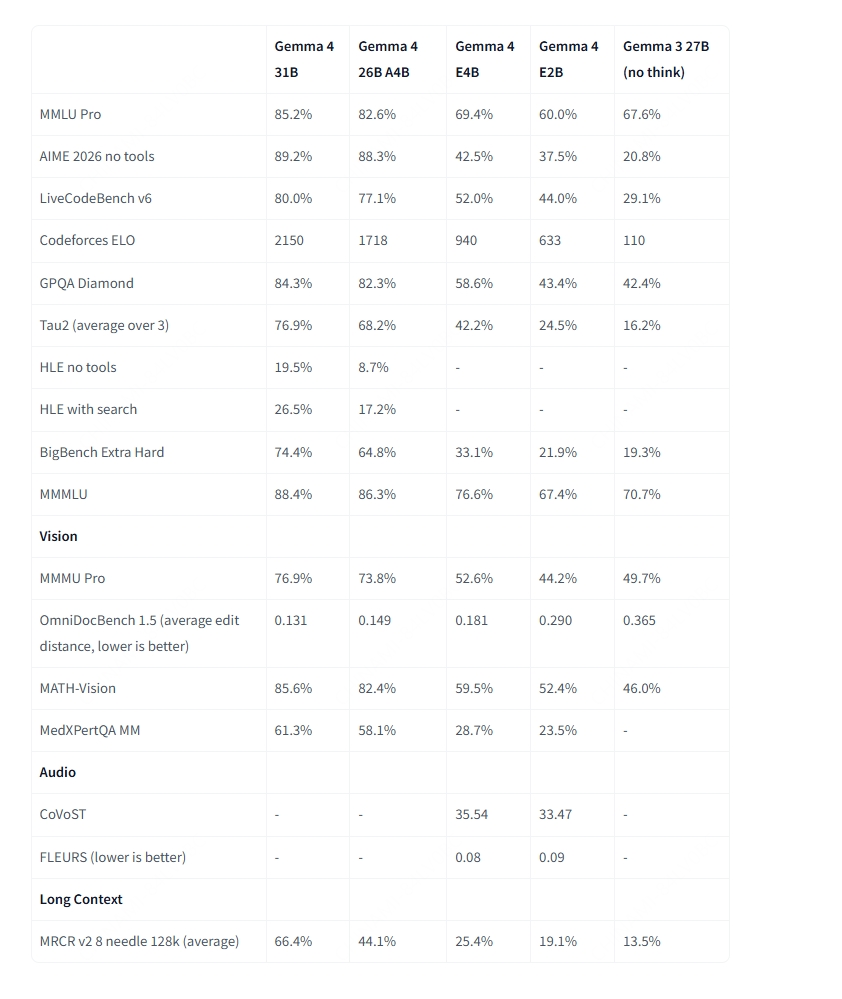
Beyond the architecture differences, all Gemma 4 sizes share a strong set of built-in capabilities:
- Thinking — A built-in reasoning mode that lets the model think step by step before answering.
- Long context — 128K tokens for E2B and E4B, and 256K tokens for 26B A4B and 31B.
- Image understanding — Object detection, document and PDF parsing, screen and UI understanding, chart comprehension, OCR, handwriting recognition, and pointing.
- Video understanding — Analyze video by processing sequences of frames.
- Interleaved multimodal input — Text and images can be freely mixed in one prompt.
- Function calling — Native support for structured tool use and agentic workflows.
- Coding — Code generation, completion, and correction.
- Multilingual — Out-of-the-box support for 35+ languages, pre-trained on 140+ languages.
- Audio (E2B and E4B only) — Automatic speech recognition (ASR) and speech-to-translated-text across multiple languages.
Multimodal Capabilities: Vision and Audio
Vision: all four sizes, native aspect ratio
All four Gemma 4 sizes support vision input. Images are handled at their native aspect ratio using mixed-resolution processing — no pan-and-scan cropping and no forced square resizing.
Audio: E2B and E4B only
Audio input is supported on the E2B and E4B small models only. The 26B A4B and 31B do not support audio.
The audio model supports:
- Automatic Speech Recognition (ASR) — Transcribes speech into text in the source language.
- Automatic Speech Translation (AST) — Transcribes speech in a source language and translates the output into a target language.
Recommended Sampling Parameters
Google’s standardized sampling configuration across Gemma 4 use cases:
| Parameter | Value |
|---|---|
| temperature | 1.0 |
| top_p | 0.95 |
| top_k | 64 |
Use these as a baseline sampling configuration across Gemma 4 use cases.
Model Comparison
| Model | Context | Audio | Access |
|---|---|---|---|
| Gemma 4 31B | 256K | No | Model API or GPU Application |
| Gemma 4 26B A4B | 256K | No | Model API or GPU Application |
| Gemma 4 E4B | 128K | Yes | GPU Application |
| Gemma 4 E2B | 128K | Yes | GPU Application |
Run Gemma 4 on Novita AI
Novita AI offers two ways to run Gemma 4, depending on whether you want a managed API or full control over your instance.
Model API: 31B and 26B A4B
Gemma 4 31B and Gemma 4 26B A4B are available on the Novita AI Model API — OpenAI-compatible, pay-per-token, and with no monthly commitment.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="google/gemma-4-31b-it",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)No SDK changes are needed if you’re already using an OpenAI-compatible client. Swap the base_url and api_key, update the model string, and you’re running.
GPU Application: all four sizes
All four Gemma 4 models — E2B, E4B, 26B A4B, and 31B — are available via Novita AI GPU Application. GPU Application is a library of pre-configured, ready-to-run model deployments: pick a model, launch an instance, and it’s running in one click. No infrastructure setup and no manual container configuration.
Launch Gemma 4 via GPU Application →
Conclusion
Gemma 4 brings three distinct architectures under one model family: a 31B dense model for long-context quality, a 26B A4B MoE model designed for constrained memory targets with QAT support, and small E2B/E4B models purpose-built for on-device inference. Vision input is available across all four sizes, while audio (ASR and AST) is supported on E2B and E4B only. All sizes ship with thinking, function calling, multilingual support, and video understanding built in.
On Novita AI, the 31B and 26B A4B are live on the Model API — OpenAI-compatible and drop-in ready. All four sizes, including the small models, are available via GPU Application for one-click deployment.
Frequently Asked Questions
What’s the difference between Gemma 4 31B and Gemma 4 26B A4B?
The 31B is a dense model — all 31.3B parameters are active on every forward pass, optimized for long-context quality. The 26B A4B is a Mixture of Experts model with 26.8B total parameters but only 3.8B active at inference time, designed for constrained-memory deployments with quantization support.
Do all Gemma 4 sizes support vision and audio?
Vision is supported across all four sizes. Audio is supported on E2B and E4B only — the 26B A4B and 31B accept text and image input but not audio.
What quantization formats are available for Gemma 4?
QAT-based checkpoints are provided for the MoE (26B A4B) variant: Q3-2, Q3-0, and Q4-0.
What is Novita AI GPU Application?
GPU Application is a one-click model deployment product on Novita AI. Choose from a library of pre-configured, ready-to-run model apps — LLM, image, audio, and video — pick a model, launch an instance, and it’s running. No container setup or infrastructure configuration required. All four Gemma 4 sizes are available there.
Novita AI is an AI & agent cloud platform helping developers and startups build, deploy, and scale models and agentic applications with high performance, reliability, and cost efficiency.



