

DeepSeek-V4-Pro: 1M Context, #1 on LiveCodeBench, Open-Source Frontier
You’re evaluating open-source models for a production coding agent. You need something that handles large codebases—entire repos, not just single files—and actually resolves GitHub issues without hallucinating tool calls. Every model you try either falls apart beyond 128K tokens or lags behind GPT-4o on the benchmarks that matter for real engineering tasks.
DeepSeek-V4-Pro changes this calculus. It’s a 1.6-trillion-parameter MoE model with a true 1M-token context window, the highest published score on LiveCodeBench (93.5 Pass@1), and Codeforces Rating 3206—both #1 among all evaluated models including closed frontier APIs. In short: it’s the best open-source model available today for competitive coding and large-context agentic tasks, released under MIT license. As of today, it’s available via Novita AI.
What Is DeepSeek-V4-Pro?
DeepSeek-V4-Pro is the flagship model in DeepSeek’s V4 series, released April 24, 2026. It sits above the lightweight DeepSeek-V4-Flash (284B total / 13B active) and is positioned as a preview of DeepSeek’s current frontier capabilities—what they describe as the “best open-source model available today” for knowledge and coding. The model is trained on over 32 trillion tokens and fine-tuned through a two-stage pipeline: domain-expert SFT + GRPO reinforcement learning, followed by on-policy distillation. The full technical details are in DeepSeek’s paper DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence.
Key specs at a glance:
- Architecture: Mixture-of-Experts (MoE) with Hybrid Attention — Compressed Sparse Attention (CSA) + Heavily Compressed Attention (HCA)
- Parameters: 1.6T total / 49B activated per forward pass
- Context window: 1,048,576 tokens (1M)
- Precision: FP4 (MoE experts) + FP8 mixed
- Reasoning modes: Non-think (fast), Think (standard CoT), Max (maximum reasoning budget)
- Capabilities: Function calling, structured outputs, reasoning, 1M-context retrieval
- License: MIT
Key Features
Hybrid Attention for Efficient 1M-Token Context
Most models claiming “long context” either truncate silently or degrade sharply beyond 128K tokens. DeepSeek-V4-Pro’s Hybrid Attention Architecture—combining Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA) alongside Manifold-Constrained Hyper-Connections (mHC)—is designed from the ground up for efficient million-token processing. In practice: MRCR 1M scores 83.5 (memory recall across 1M context) and CorpusQA 1M hits 62.0, both while maintaining coherent reasoning over the full window. For agents that need to ingest an entire codebase, a day’s worth of logs, or a book-length document in a single call, this is the architecture that makes it viable without specialized infrastructure.
#1 on LiveCodeBench and Codeforces — The Coding Model That Actually Competes
DeepSeek-V4-Pro scores 93.5 on LiveCodeBench (Pass@1) and 3206 on Codeforces Rating—both the highest published scores in the comparison table, beating Claude Opus 4.6 Max (88.8 / no rating), Gemini 3.1 Pro High (91.7 / 3052), and GPT-5.4 xHigh (no LCB score / 3168). On SWE-Verified (real-world GitHub issue resolution), it hits 80.6, on par with Claude Opus 4.6 Max (80.8) and Gemini 3.1 Pro (80.6). For teams building coding agents where “can it actually fix the bug” matters more than theoretical MMLU scores, V4-Pro is the open-source option that directly competes with closed frontier APIs.
Three Reasoning Modes — Match Compute to the Task
DeepSeek-V4-Pro exposes three inference modes through the same API endpoint:
- Non-think: No chain-of-thought. Fast, low latency—suitable for classification, extraction, structured output tasks where reasoning overhead is wasteful.
- Think: Standard CoT reasoning. The default for coding, math, and multi-step tasks.
- Max (V4-Pro Max): Extended reasoning budget. Use when accuracy matters more than speed—complex proofs, hard competitive programming problems, deep debugging sessions.
All three modes are accessible via the deepseek/deepseek-v4-pro model ID backed by Novita AI. Switching between them is a prompt-level instruction, not a different endpoint—which means you can implement adaptive mode selection in your application without changing API config.
Agentic and Tool Use Performance
Beyond coding benchmarks, V4-Pro holds its own on agentic evaluations. BrowseComp: 83.4 (vs Claude Opus 83.7, Gemini 85.9—within 2.5 points of the frontier). MCPAtlas Public: 73.6, second only to Claude Opus 4.6 (73.8). Toolathlon: 51.8, third overall. These aren’t “leads all models” results, but they confirm that V4-Pro is a capable general-purpose agentic model, not just a benchmark-optimized coding specialist. Combined with native function calling support, it’s a practical choice for agents that need to browse, call tools, and reason in a single session.
Benchmark Performance
The table below covers the benchmarks from DeepSeek’s official comparison. “V4-Pro” refers to the DeepSeek-V4-Pro Max (extended reasoning) mode—the same model accessible via the deepseek/deepseek-v4-pro API ID on Novita.
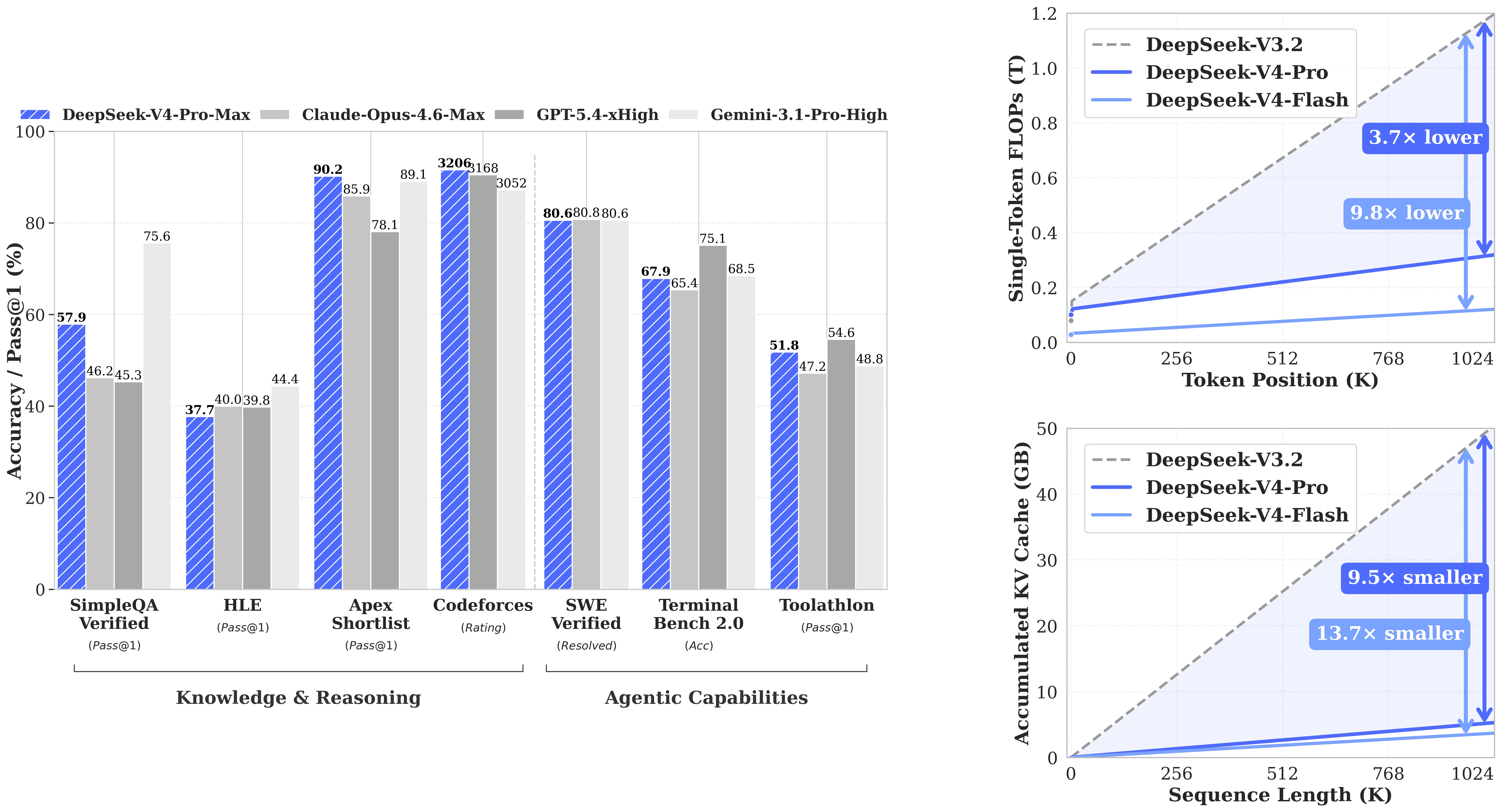
DeepSeek-V4-Pro performance across coding, reasoning, and agentic benchmarks. [Source: DeepSeek HuggingFace]
| Benchmark | DeepSeek-V4-Pro | Claude Opus 4.6 | Gemini 3.1 Pro | GPT-5.4 |
|---|---|---|---|---|
| LiveCodeBench (Pass@1) | 93.5 ✓ | 88.8 | 91.7 | — |
| Codeforces Rating | 3206 ✓ | — | 3052 | 3168 |
| SWE-Verified | 80.6 | 80.8 | 80.6 | — |
| SWE Pro | 55.4 | 57.3 | 54.2 | 57.7 |
| BrowseComp | 83.4 | 83.7 | 85.9 | 82.7 |
| MCPAtlas Public | 73.6 | 73.8 | 69.2 | 67.2 |
| GPQA Diamond | 90.1 | 91.3 | 94.3 | 93.0 |
| HLE (Pass@1) | 37.7 | 40.0 | 44.4 | 39.8 |
| IMOAnswerBench | 89.8 | 75.3 | 81.0 | 91.4 |
| HMMT 2026 Feb | 95.2 | 96.2 | 94.7 | 97.7 |
| MRCR 1M (MMR) | 83.5 | 92.9 | 76.3 | — |
| CorpusQA 1M | 62.0 | 71.7 | 53.8 | — |
| Terminal Bench 2.0 | 67.9 | 65.4 | 68.5 | 75.1 |
✓ = highest published score in this comparison. Last verified: 2026-04-25. Scores reflect “Max” / extended reasoning mode where applicable. Source: DeepSeek HuggingFace model card.
Honest read: On knowledge benchmarks (GPQA Diamond, HLE), Gemini 3.1 Pro and GPT-5.4 are clearly ahead. V4-Pro’s edge is in coding—LiveCodeBench and Codeforces are unambiguous #1 scores—and in long-context retrieval over other open-source models. For math reasoning, the gap is mixed: V4-Pro beats GPT-5.4 on IMOAnswerBench (89.8 vs 91.4, close) but trails on HMMT 2026 (95.2 vs 97.7).
How to Use DeepSeek-V4-Pro backed by Novita AI
Option 1: Playground (No Code)
Test directly at novita.ai/models/model-detail/deepseek-deepseek-v4-pro. No API key required to explore. Set the system prompt to activate Think or Non-think mode.
Option 2: API (Python)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="YOUR_NOVITA_API_KEY",
)
# Standard (Think mode)
response = client.chat.completions.create(
model="deepseek/deepseek-v4-pro",
messages=[
{"role": "user", "content": "Implement a Rust async runtime from scratch."}
],
)
print(response.choices[0].message.content)Get your API key at novita.ai/settings. The same model ID works for all three reasoning modes—pass mode instructions in the system prompt or use DeepSeek’s documented mode-switching syntax.
Option 3: Third-Party Tools
Since Novita AI is OpenAI-API-compatible, you can drop in deepseek/deepseek-v4-pro as the model ID in Cursor (custom OpenAI provider), Claude Code-compatible setups, LangChain, LlamaIndex, or any OpenAI SDK-based framework. Just point base_url to https://api.novita.ai/v3/openai.
curl https://api.novita.ai/v3/openai/chat/completions \\
-H "Authorization: Bearer YOUR_NOVITA_API_KEY" \\
-H "Content-Type: application/json" \\
-d '{"model":"deepseek/deepseek-v4-pro","messages":[{"role":"user","content":"Implement a Rust async runtime."}]}'Use Cases
Full-codebase analysis and refactoring: With 1M-token context, you can pass an entire medium-sized repository in one call. Ask V4-Pro to find architectural issues, generate migration guides, or refactor patterns across 50+ files simultaneously—without chunking or retrieval hacks.
Competitive programming and hard algorithm problems: Codeforces Rating 3206 puts V4-Pro in the top tier for algorithmic problem solving. Use it for generating solutions to competitive programming challenges, verifying complexity proofs, or stress-testing edge cases in production algorithms.
GitHub issue resolution agents: SWE-Verified 80.6 places V4-Pro on par with Claude Opus 4.6 on real-world bug fixing. Combined with function calling and long context, it can read issue descriptions, browse code history, and generate patches without losing track across large repos.
Long-document reasoning: Legal contracts, research papers, technical specifications, audit logs—V4-Pro’s 1M context means you’re not forced to summarize or chunk before analysis. CorpusQA 1M (62.0) and MRCR 1M (83.5) confirm retrieval accuracy holds at full context length.
Math and science tutoring / problem generation: IMOAnswerBench 89.8 (beats all closed models except GPT-5.4’s 91.4) makes V4-Pro a strong choice for generating competition-level math problems, verifying proofs, or building STEM education tools where mathematical reasoning is the bottleneck.
Pricing
| Model | Input ($/M tokens) | Cache Read ($/M tokens) | Output ($/M tokens) |
|---|---|---|---|
| DeepSeek-V4-Pro (Novita) | $1.74 | $0.145 | $3.48 |
| DeepSeek-V4-Flash (Novita) | $0.10 | — | $0.50 |
| Claude Opus 4.6 (Anthropic) | $15.00 | $1.50 | $75.00 |
| Gemini 3.1 Pro (Google) | $1.25 | $0.31 | $10.00 |
| GPT-5.4 (OpenAI) | $10.00 | $2.50 | $40.00 |
Last verified: 2026-04-25. Novita pricing from novita.ai/pricing. Competitor pricing: Claude from anthropic.com (unverified), Gemini from ai.google.dev (unverified), GPT-5.4 from platform.openai.com (unverified).
Via Novita AI, V4-Pro is roughly 8× cheaper than Claude Opus 4.6 for input tokens, and 21× cheaper for output. Compared to Gemini 3.1 Pro, input pricing is similar but output is 2.9× cheaper. For coding agents with long context and multi-turn sessions—where output tokens dominate costs—the gap compounds fast.
Migrating from DeepSeek-V3 or DeepSeek-R1
If you’re currently running DeepSeek-V3 or R1 on Novita, upgrading to V4-Pro is a one-line model ID change. The API is OpenAI-compatible, same endpoint, same request format. V4-Pro’s three reasoning modes give you the flexibility to replicate both V3 (non-think mode) and R1-style deep reasoning (Max mode) from a single model—without maintaining separate deployments. If you’re migrating from another provider’s model (GPT-4o, Claude 3.5, etc.), point your existing OpenAI SDK client to base_url="https://api.novita.ai/v3/openai" and swap the model ID.
Conclusion
Bottom line: DeepSeek-V4-Pro is the strongest open-source model available for coding tasks, with definitive #1 scores on LiveCodeBench and Codeforces, and it’s the only model in its tier that handles a genuine 1M-token context window. It doesn’t lead every benchmark—Gemini 3.1 Pro holds the edge on knowledge recall, and Claude Opus leads on long-context retrieval—but for teams building coding agents, fixing GitHub issues at scale, or processing massive documents, V4-Pro delivers frontier-class performance at a fraction of closed-model API costs. Now available backed by Novita AI — 200+ model APIs and OpenAI-compatible infrastructure.
For teams that do not need Pro on every request, the DeepSeek V4 Pro vs Flash comparison explains how to use Flash for lower-cost baseline traffic and reserve Pro for higher-failure-cost coding or long-context work.
Try DeepSeek-V4-Pro via Novita AI →
FAQ
What is DeepSeek-V4-Pro?
DeepSeek-V4-Pro is a 1.6-trillion-parameter Mixture-of-Experts language model from DeepSeek AI, released April 2026. It activates 49B parameters per forward pass, supports 1,048,576 tokens of context, and currently leads all publicly evaluated models on LiveCodeBench (93.5) and Codeforces Rating (3206). It’s available under the MIT license and via Novita AI.
How do I access DeepSeek-V4-Pro via API?
Use model ID deepseek/deepseek-v4-pro with base_url="https://api.novita.ai/v3/openai" and your Novita API key from novita.ai/settings. The endpoint is OpenAI SDK-compatible—no custom SDK required.
How does DeepSeek-V4-Pro compare to Claude Opus 4.6 and Gemini 3.1 Pro?
V4-Pro leads on coding: LiveCodeBench 93.5 (vs Opus 4.6 88.8, Gemini 91.7) and Codeforces 3206 (vs Gemini 3052). On knowledge benchmarks like GPQA Diamond and HLE, Gemini 3.1 Pro leads. On long-context retrieval (MRCR 1M), Claude Opus leads. V4-Pro is the best open-source choice for coding-heavy and agentic workloads—closed models maintain edges in raw factual recall.
What is DeepSeek-V4-Pro’s context window?
1,048,576 tokens (1M). The model is specifically architected for long-context efficiency using Hybrid Attention (CSA + HCA). MRCR 1M scores 83.5 and CorpusQA 1M hits 62.0, confirming usable retrieval accuracy at full context length.
How much does DeepSeek-V4-Pro cost backed by Novita AI?
$1.74/M input tokens, $3.48/M output tokens, $0.145/M cache read. This makes it approximately 8× cheaper than Claude Opus 4.6 for input and 21× cheaper for output. Last verified: 2026-04-25.



