

DeepSeek-V4-Flash backed by Novita AI: 1M Context at $0.14/M Tokens
Most open-source models with reasoning capabilities force a trade-off: small context windows, slow throughput, or prices that climb above $1/M tokens the moment you enable extended thinking. DeepSeek-V4-Flash sidesteps that entirely — 284B parameters, only 13B activated per inference, a native 1,048,576-token context window, and three selectable reasoning modes. At $0.14/M input tokens, it lands in a category where reasoning-capable models rarely compete.
In short: DeepSeek-V4-Flash is a MoE model from DeepSeek AI that brings 1M-token context and adjustable reasoning depth to developers who need throughput without the closed-model price premium. As of today, it’s available through the Novita AI API.
Open DeepSeek-V4-Flash in the Novita AI model console
What Is DeepSeek-V4-Flash?
DeepSeek-V4-Flash is a Mixture-of-Experts (MoE) language model from DeepSeek AI, released as part of the DeepSeek-V4 series alongside the larger DeepSeek-V4-Pro. The model has 284B total parameters with 13B activated at inference — keeping per-token compute cost low while retaining the parameter capacity of a much larger model.
Key capabilities at a glance:
- 284B total / 13B activated parameters — MoE architecture, low inference cost
- 1,048,576-token context window (1M tokens) — enabled by Hybrid Attention Architecture
- Three reasoning modes: Non-think (fast), Think (step-by-step), Think Max (maximum reasoning budget)
- Function calling support — tool use, structured outputs, JSON mode
- Trained on 32T+ tokens with multi-stage post-training (SFT, RL with GRPO, on-policy distillation)
- MIT License — weights available for download on HuggingFace; commercial use permitted
- FP4 + FP8 mixed precision — MoE expert weights in FP4, remaining layers in FP8
Key Features: Why DeepSeek-V4-Flash Stands Out
Selectable Reasoning Depth Without Switching Models
Most models lock you into a single inference mode: either reasoning-on or reasoning-off. DeepSeek-V4-Flash gives you three distinct operating modes on the same API endpoint:
| Mode | Characteristics | Best For |
|---|---|---|
| Non-think | Fast, no chain-of-thought | High-volume tasks, chat, summarization |
| Think | Step-by-step reasoning, balanced | Complex Q&A, code generation, analysis |
| Think Max | Maximum reasoning budget | Math competitions, hard coding tasks, benchmarks |
The gap between modes is significant: on GPQA Diamond, V4-Flash Non-think scores 71.2 vs Think at 87.4 and Think Max at 88.1. On LiveCodeBench, Think Max reaches 91.6 vs Non-think’s 55.2. You choose cost vs quality per request — no infrastructure change required.
Hybrid Attention Architecture for 1M-Token Context
Native million-token context is harder than it sounds. DeepSeek-V4-Flash achieves it through a purpose-built Hybrid Attention Architecture that combines two mechanisms:
- Compressed Sparse Attention (CSA) — dramatically reduces the attention compute budget for long sequences
- Heavily Compressed Attention (HCA) — compresses KV cache footprint for 1M-context inference
The result: inference over 1M-token inputs with manageable FLOP and memory cost. For workloads like codebase analysis, legal document review, or long-session agents, this architecture makes the difference between feasible and prohibitive.
MoE Efficiency: 13B Activated at 284B Scale
The 284B/13B activated ratio is where the cost efficiency comes from. Only 13B parameters are active per forward pass, keeping latency and per-token cost close to a 13B dense model — while the full 284B parameter pool provides knowledge capacity comparable to a much larger dense network. The FP4 + FP8 mixed precision further reduces memory bandwidth pressure on expert weights.
Strong Post-Training Pipeline
DeepSeek-V4-Flash follows a two-stage post-training process: first, domain-specific expert cultivation via SFT and reinforcement learning with GRPO; then, unified model consolidation through on-policy distillation. This produces a single model with differentiated capability profiles across coding, reasoning, and general knowledge — not a generic instruction-follower.
Benchmark Performance
The benchmark story for DeepSeek-V4-Flash is about reasoning mode selection. In Non-think mode, it behaves like an efficient 13B-activated model. Dial up to Think Max and it reaches a different tier entirely.
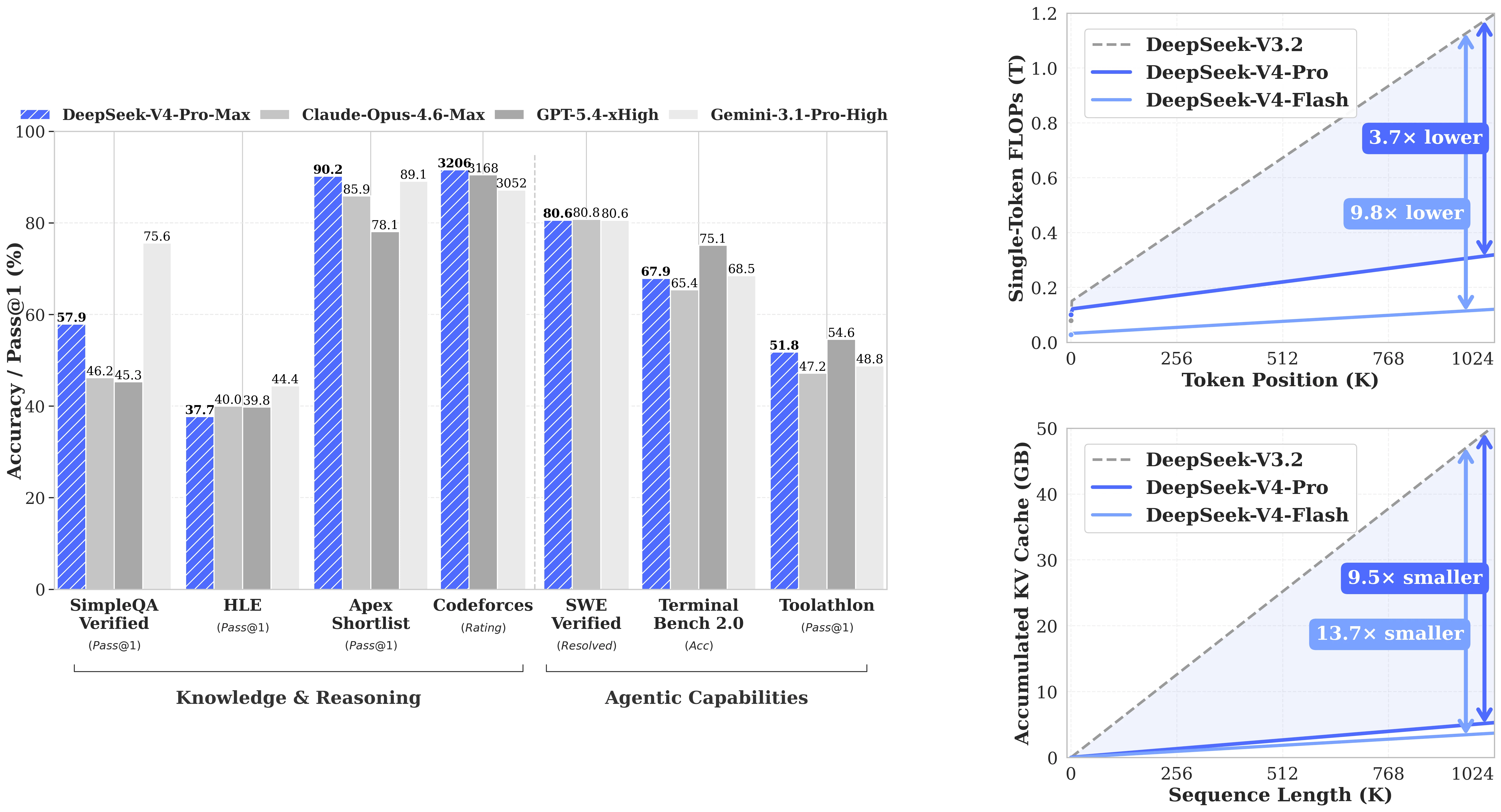
DeepSeek-V4-Flash performance across modes vs frontier models [Source: DeepSeek AI / HuggingFace]
Performance Across Reasoning Modes
Below are V4-Flash’s scores across key benchmarks, comparing all three operating modes:
| Benchmark | V4-Flash Non-Think | V4-Flash Think | V4-Flash Think Max |
|---|---|---|---|
| LiveCodeBench (Pass@1) | 55.2 | 88.4 | 91.6 |
| GPQA Diamond (Pass@1) | 71.2 | 87.4 | 88.1 |
| HMMT 2026 Feb (Pass@1) | 40.8 | 91.9 | 94.8 |
| IMOAnswerBench (Pass@1) | 41.9 | 85.1 | 88.4 |
| Codeforces Rating | — | 2816 | 3052 |
| SWE Verified (Resolved) | 73.7 | 78.6 | 79.0 |
| MRCR 1M (MMR) | 37.5 | 76.9 | 78.7 |
| MCPAtlas (Pass@1) | 64.0 | 67.4 | 69.0 |
| MMLU-Pro (EM) | 83.0 | 86.4 | 86.2 |
Last verified: 2026-04-27. Source: DeepSeek-V4 technical report and HuggingFace model card.
How V4-Flash Compares to Competitors
V4-Flash Think Max (79.0 SWE Verified, 91.6 LiveCodeBench) competes with models running at much higher per-token cost. It doesn’t top every leaderboard — V4-Pro Max leads on most frontier benchmarks — but for developers looking at cost-per-task rather than raw peak performance, the trade-off is favorable:
If you are choosing between the two DeepSeek V4 APIs for production routing, use the DeepSeek V4 Pro vs Flash pricing and routing guide to compare when Flash should handle baseline traffic and when Pro is worth the higher token price.
| Benchmark | V4-Flash Max | V4-Pro Max | Claude Opus 4.6 Max | Gemini 3.1 Pro High |
|---|---|---|---|---|
| LiveCodeBench (Pass@1) | 91.6 | 93.5 | 88.8 | 91.7 |
| GPQA Diamond (Pass@1) | 88.1 | 90.1 | 91.3 | 94.3 |
| SWE Verified (Resolved) | 79.0 | 80.6 | 80.8 | 80.6 |
| HMMT 2026 Feb (Pass@1) | 94.8 | 95.2 | 96.2 | 94.7 |
| MRCR 1M (MMR) | 78.7 | 83.5 | 92.9 | 76.3 |
Last verified: 2026-04-27. Claude Opus 4.6 Max and Gemini 3.1 Pro High figures sourced from the DeepSeek-V4 technical report (V4-Pro frontier comparison table). These scores were not measured head-to-head against V4-Flash in that report.
Notably, V4-Flash Think Max on MRCR 1M (78.7) beats Gemini 3.1 Pro High (76.3) on the long-context retrieval task — the benchmark that most directly maps to 1M-context use cases. On SWE Verified, all four models cluster between 79–81, making V4-Flash competitive in the real-world coding agent category at a fraction of the closed-model price.
How to Use DeepSeek-V4-Flash via Novita AI
Option 1: Playground (No Code)
Test the model directly in your browser at the Novita AI model console. No API key required to start — switch between Non-think, Think, and Think Max modes via the chat interface.
Option 2: API (Python)
DeepSeek-V4-Flash uses the OpenAI-compatible API. Use the model ID deepseek/deepseek-v4-flash with the Novita base URL:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="YOUR_NOVITA_API_KEY",
)
response = client.chat.completions.create(
model="deepseek/deepseek-v4-flash",
messages=[{"role": "user", "content": "Your prompt here"}]
)
print(response.choices[0].message.content)To enable Think or Think Max mode, pass the reasoning parameter in the request body:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="YOUR_NOVITA_API_KEY",
)
# Think Max mode — maximum reasoning budget
response = client.chat.completions.create(
model="deepseek/deepseek-v4-flash",
messages=[{"role": "user", "content": "Solve: x^4 - 5x^2 + 4 = 0"}],
extra_body={"reasoning": {"effort": "high"}} # "low" = Think, "high" = Think Max
)
print(response.choices[0].message.content)Get your API key at novita.ai/settings.
Option 3: Third-Party Tools
Because Novita AI exposes an OpenAI-compatible endpoint, DeepSeek-V4-Flash works out of the box with:
- LangChain / LlamaIndex — use
ChatOpenAIwithbase_url="https://api.novita.ai/v3/openai" - OpenWebUI — add as a custom OpenAI-compatible endpoint
- Continue.dev / Cursor — configure as a custom model with the Novita base URL
Pricing
DeepSeek-V4-Flash is priced consistently across major providers. All figures are per million tokens, as of 2026-04-27:
| Provider | Input ($/M) | Output ($/M) | Cache Read ($/M) | Max Context |
|---|---|---|---|---|
| Novita AI | $0.14 | $0.28 | $0.028 | 1,048,576 tokens |
| DeepSeek Official | $0.14 | $0.28 | $0.028 | 131,072 tokens |
| SiliconFlow | $0.14 | $0.28 | $0.028 | 65,536 tokens |
| DeepInfra | $0.14 | $0.28 | — | 16,384 tokens |
The per-token rate is the same everywhere — but max context varies significantly. Novita AI offers the full 1M token context window. DeepInfra caps at 16,384 tokens. If your workload involves long documents, codebases, or multi-turn agents, Novita is the practical choice.
Recommended Use Cases
Autonomous Coding Agents
V4-Flash’s 1M context window means an agent can load an entire codebase into context without chunking. Combined with 79.0 SWE Verified in Think Max mode, it handles multi-file refactors and debugging without losing state between turns.
Long-Document QA and RAG
MRCR 1M (Multi-Round Context Retrieval) at 78.7% Think Max — the benchmark measures retrieval accuracy over a genuine 1M-token window. For indexing legal documents, academic papers, or long technical specs, V4-Flash retrieves accurately where most models degrade after 32K tokens.
Math and Science Reasoning
94.8% on HMMT 2026 February (competition math) with Think Max. The budget-thinking mode lets you tune cost vs accuracy — use Think for standard problems, Think Max for the hard ones. A single request doesn’t burn a fixed compute budget; you choose.
Production APIs with Caching
At $0.028/M cache reads, repeated system prompts and tool schemas effectively cost nothing at scale. Chatbot products and API wrappers that re-inject the same context on every call benefit from cache read pricing over raw input pricing.
For a mixed-model setup, keep Flash as the default for repeated production calls and escalate difficult long-context or coding-agent prompts to Pro. The DeepSeek V4 Pro long-context guide shows how to configure the Pro model ID, base URL, request shape, and cost controls for those higher-difficulty paths.
Frequently Asked Questions
What is DeepSeek-V4-Flash?
DeepSeek-V4-Flash is a 284B-parameter Mixture-of-Experts language model developed by DeepSeek AI, released on 2026-04-23. It activates only 13B parameters per forward pass, making it significantly faster and cheaper than dense models of comparable capability. It supports a 1,048,576-token context window and three reasoning modes: Non-thinking (fast), Budget Thinking, and Extended Thinking (Think Max).
How is DeepSeek-V4-Flash different from DeepSeek-V4-Pro?
V4-Flash is the lighter, faster variant optimized for speed and cost. V4-Pro is the flagship model with higher peak benchmark scores (e.g., 93.5 vs 91.6 on LiveCodeBench Think Max). V4-Flash “achieves comparable reasoning performance to the Pro version when given a larger thinking budget” — in practice, V4-Flash Think Max closes most of the gap against V4-Pro Think Max at lower per-token cost.
If you need a production routing rule, compare both models in the DeepSeek V4 Pro vs Flash API decision guide before moving all traffic to one model.
What does “Flash” mean in the model name?
Flash signals a speed-optimized variant, consistent with how Google uses the term for Gemini Flash. DeepSeek-V4-Flash prioritizes lower latency and cost over raw maximum accuracy, with the thinking modes available when you need to close the performance gap.
Does DeepSeek-V4-Flash support a 1M context window backed by Novita AI?
Yes. Novita AI exposes the full 1,048,576-token context window — the largest available across all current providers for this model. Max completion tokens on Novita is 393,216.
How do I switch reasoning modes via the API?
Pass the extra_body={"reasoning": {"effort": "low"}} parameter for Budget Thinking, or "effort": "high" for Think Max. Omit the parameter entirely for Non-thinking (fast) mode. The API is OpenAI-compatible — no SDK changes required.
What is the pricing for DeepSeek-V4-Flash backed by Novita AI?
As of 2026-04-27: $0.14/M input tokens, $0.28/M output tokens, $0.028/M cache read tokens. This matches DeepSeek’s official pricing and is consistent across providers — the differentiator on Novita is the full 1M context window and reliable uptime.
Is DeepSeek-V4-Flash open source?
Yes. The model weights are available on HuggingFace under the MIT License — confirmed in the official DeepSeek-V4 repository. Self-hosting and commercial use are permitted under MIT terms. Using it via Novita AI’s API requires no self-hosting at all.
Start Using DeepSeek-V4-Flash Today
DeepSeek-V4-Flash is now available via Novita AI with the full 1M context window, competitive pricing, and zero infrastructure overhead. You pick the reasoning mode; Novita handles the rest.
→ Try DeepSeek-V4-Flash backed by Novita AI
→ Novita AI LLM API documentation



