

- Why Your Choice of Inference Provider Actually Matters
- Meet the Five Providers in This Comparison
- How Wide Is Each Provider’s Model Catalog?
- Pricing Comparison: Where Novita AI Has a Clear Cost Advantage
- Output Quality Scores: Not All Providers Serve Models Equally Well
- Choosing the Right Provider for Your Use Case
- How to Start Using Novita AI in Your Project
- Conclusion
Choosing an inference API provider for open-source models isn’t just about who offers the model — it’s about which provider delivers the best output quality at the lowest cost with the widest model selection. The same model can return meaningfully different results and come at 5x the price depending on where you call it. This article compares five leading providers — Novita AI, Together AI, Fireworks AI, DeepInfra, and Groq — across three dimensions that actually matter: model catalog coverage, pricing, and real benchmark output quality.
Why Your Choice of Inference Provider Actually Matters
When you call an open-source model through a third-party API, the underlying weights are identical — but the serving infrastructure, quantization choices, and optimization stack differ significantly between providers. This matters more than most developers realize.
Consider gpt-oss-120B (high), OpenAI’s flagship open-weight model: input prices range from $0.05 to $0.60 per 1M tokens across providers — a 12x spread. Output quality scores on the exact same model diverge by measurable margins on independent benchmarks. And while one provider supports 66+ models on OpenRouter, another caps out at a dozen. These differences compound over production-scale usage, affecting both your monthly infrastructure bill and the quality of outputs your users receive.
Meet the Five Providers in This Comparison
Before diving into the numbers, here’s a brief overview of each provider:
Novita AI is an AI & agent cloud platform helping developers and startups build, deploy, and scale models and agentic applications with high performance, reliability, and cost efficiency. It covers a wide range of open-source models — including GLM, MiniMax, Kimi, Qwen, DeepSeek, OpenAI’s open-weight gpt-oss series, Meta’s Llama family, and more — all under one OpenAI-compatible endpoint.
Together AI is a well-established inference provider with strong ecosystem integrations, popular among teams using LangChain, LlamaIndex, and similar frameworks. It offers a solid selection of mainstream open-source models with competitive output speeds.
If Together is a serious finalist, the focused Together AI vs Novita AI comparison covers pricing, API compatibility, batch jobs, dedicated endpoints, and production workflow tradeoffs in more detail.
Fireworks AI focuses on low-latency inference, positioning itself for latency-sensitive applications. Its model catalog is more selective, prioritizing production-ready models over breadth. For teams comparing that positioning against Novita AI’s model APIs, Agent Sandbox, batch inference, and GPU Cloud, see the dedicated Fireworks AI alternative guide.
DeepInfra offers a wide model catalog with consistently competitive pricing, making it a common choice for cost-focused workloads where raw model variety is valued.
Groq is purpose-built for speed, using custom LPU hardware to deliver extremely high token throughput. Its model catalog is intentionally small, optimized around the models that benefit most from Groq’s hardware architecture.
![]()
How Wide Is Each Provider’s Model Catalog?
The breadth of available models determines whether you can consolidate your infrastructure on a single provider or need to maintain multiple API keys for different use cases.
OpenRouter’s provider leaderboard — sorted by daily token volume — gives a direct, real-world signal of which inference providers are handling the most production traffic. Among the 12 providers listed above DeepInfra in that ranking, most are first-party model providers (Xiaomi, Alibaba Cloud, Google Vertex, Amazon Bedrock, MiniMax, xAI, OpenAI, StepFun, Google AI Studio, Z.ai) — companies serving primarily their own models. Excluding closed-source model vendors and model creators, Novita AI ranks #1 among pure third-party inference providers by daily token volume on OpenRouter, processing 135.8 billion tokens per day and 4.6 trillion tokens per month across 66 available models.
DeepInfra is the closest competitor at 103.6B tokens/day with 75 models on OpenRouter. Together AI, Fireworks AI, and Groq do not appear in the top positions of this ranking.
The model count on OpenRouter reflects models actively served through the platform. For comparison, Artificial Analysis tracks the following across each provider’s API endpoint:
| Provider | Models on OpenRouter |
| Novita AI | 66 |
| DeepInfra | 75 |
| Together AI | 28 |
| Groq | 8 |
| Fireworks AI | 7 |
The 66-model figure reflects Novita AI’s listing on OpenRouter. Novita AI’s full API catalog currently supports 200+ models, including models not yet available through OpenRouter. Visit novita.ai/models for the complete list.
Pricing Comparison: Where Novita AI Has a Clear Cost Advantage
We pulled pricing directly from each provider’s official pricing page for OpenAI’s gpt-oss models — the first open-weight models released by OpenAI (August 2025, Apache 2.0 license), now widely supported across major inference providers.
gpt-oss-120B (high) — Pricing Across Providers
| Provider | Input (per 1M) | Output (per 1M) |
| Novita AI | $0.05 | $0.25 |
| DeepInfra | $0.04 | $0.19 |
| Together AI | $0.15 | $0.60 |
| Fireworks AI | $0.15 | $0.60 |
| Groq | $0.15 | $0.60 |
gpt-oss-20B (low) — Pricing Across Providers
| Provider | Input (per 1M) | Output (per 1M) |
| Novita AI | $0.04 | $0.15 |
| Together AI | $0.05 | $0.20 |
| Fireworks AI | $0.07 | $0.30 |
| Groq | $0.08 | $0.30 |
| DeepInfra | N/A | N/A |
*Prices as of March 2026, sourced from each provider’s official pricing page.
Prices vary up to 5.9x across providers for identical models. For gpt-oss-20B, Novita AI is the cheapest available option at $0.07 blended per 1M tokens. For gpt-oss-120B, Novita AI sits just above DeepInfra but well below Together AI, Fireworks, and Groq — which all charge the same $0.26 blended rate, nearly 2.6x Novita’s price.
What That Means at Production Scale
For a team running 100M input + 33M output tokens per month on gpt-oss-120B (high):
| Provider | Monthly Cost | vs. Novita AI |
| Novita AI | ~$10 | — |
| DeepInfra | ~$8 | −$2 |
| Together AI | ~$26 | +$16 |
| Fireworks AI | ~$26 | +$16 |
| Groq | ~$26 | +$16 |
Switching from Together AI, Fireworks, or Groq to Novita AI saves roughly $190/month on this single model. Across a multi-model production stack — which might include DeepSeek, Llama, GLM, and Qwen variants simultaneously — the savings scale proportionally. At Novita AI’s pricing page, you can verify current rates for the full model catalog.
Output Quality Scores: Not All Providers Serve Models Equally Well
Pricing is only half the story. Artificial Analysis independently benchmarks each provider endpoint’s actual output quality — running the same prompts across providers and measuring real response quality, not just throughput or uptime.
For gpt-oss-120B (high), the results are unambiguous. Across five providers evaluated on GPQA Diamond (scientific knowledge and reasoning, N=16 independent runs), Novita AI scores highest:
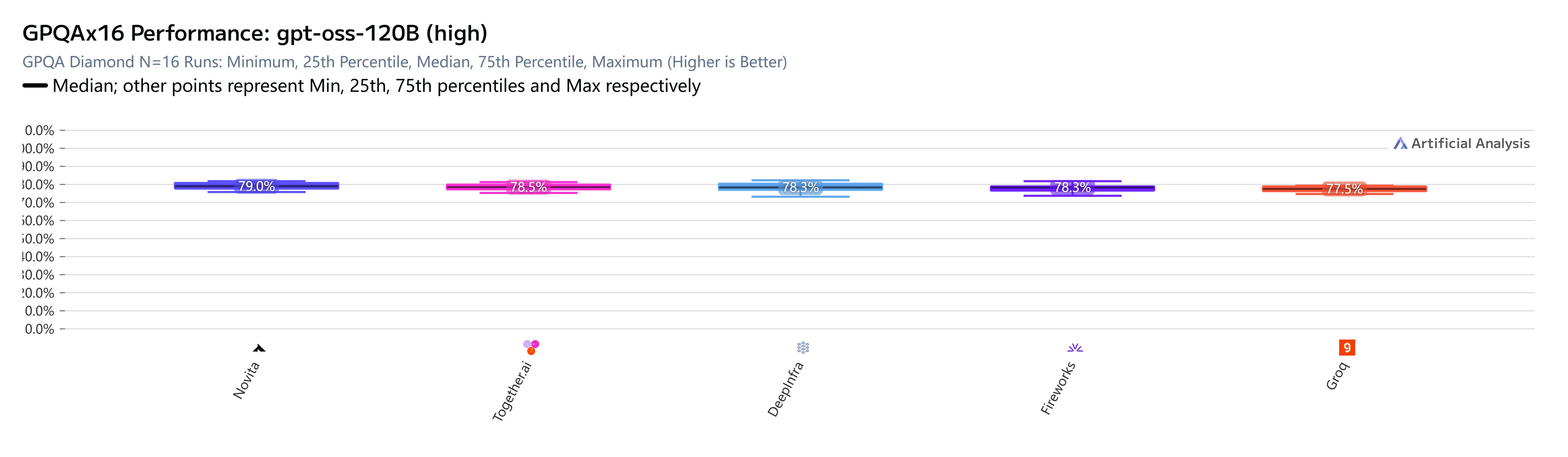
While the GPQA spread looks narrow at first glance — 79.0% vs. 77.5% — these are median scores across 16 independent runs on a benchmark specifically designed to be hard. A 1.5-percentage-point difference at this difficulty level is non-trivial. It reflects real differences in how each provider’s serving stack handles the model’s reasoning chain.
For reasoning-heavy workloads — agentic pipelines, code generation, complex Q&A — you’re not just paying less with Novita AI, you’re getting measurably better outputs.
Choosing the Right Provider for Your Use Case
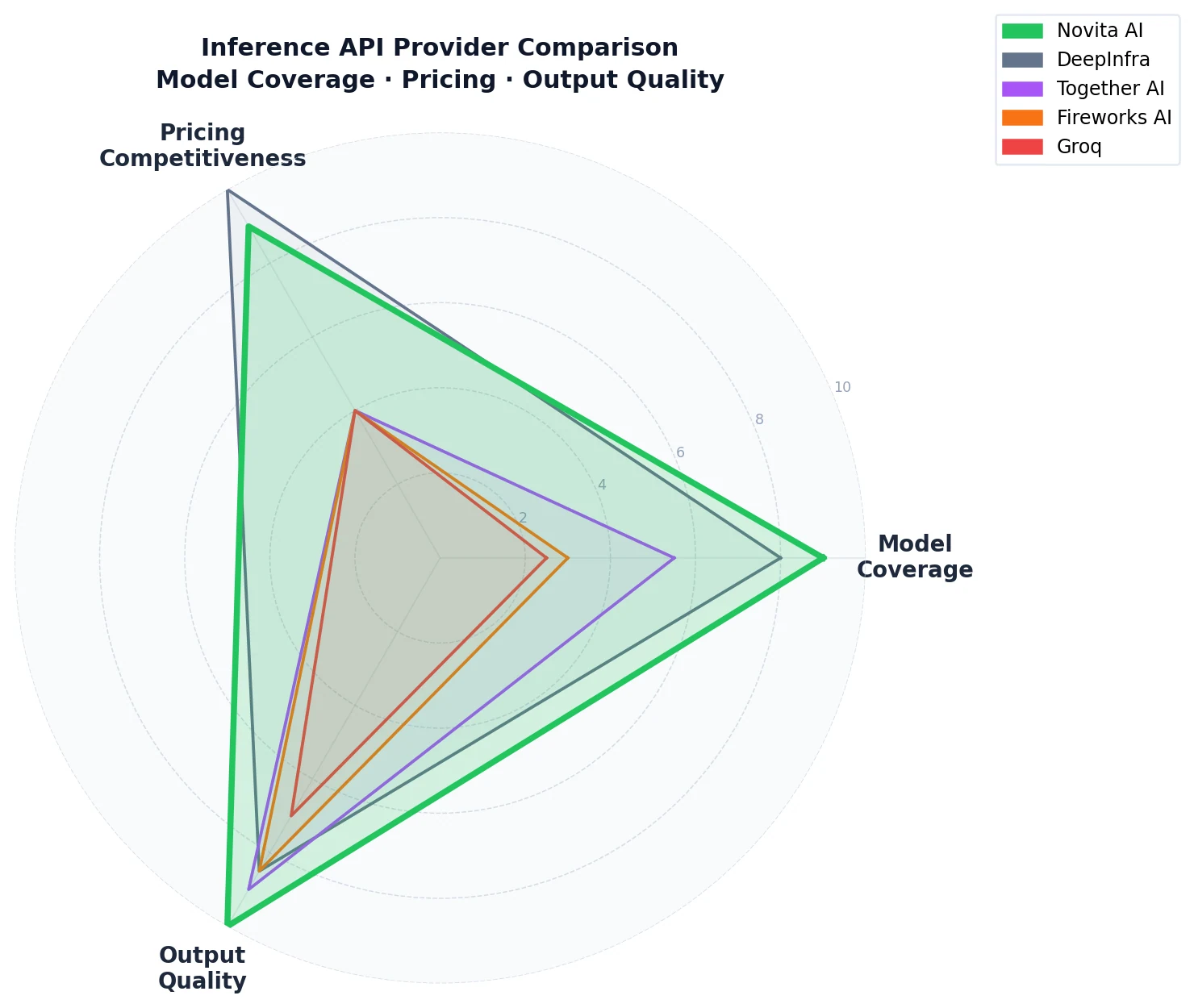
Choose Novita AI if:
- You need a single API that covers a broad catalog of open-source models — including frontier models, OpenAI open-weight, and Meta Llama — in one place
- Cost efficiency at scale is a priority — especially on the 120B+ tier
- Your workloads involve reasoning, agents, or math — where output quality differences compound
- You want production-grade reliability backed by the highest daily token volume among third-party inference providers
Choose Groq if:
- Raw tokens-per-second throughput is the primary requirement
- You’re building latency-sensitive, interactive applications with a small, fixed model set
Choose Together AI if:
- Your stack is already integrated with LangChain, LlamaIndex, or similar frameworks
- You want a balance between speed and a moderate model catalog
Choose DeepInfra if:
- Absolute lowest blended price is the only criterion
- Model catalog breadth and output quality scores are secondary concerns
Choose Fireworks AI if:
- Minimizing time-to-first-token is critical and you can work within a smaller model selection
How to Start Using Novita AI in Your Project
Step 1: Get Your API Key
- Sign up at novita.ai
- Navigate to Settings → API Keys
- Click Create New Key and store it securely — treat it like a password
Step 2: Make Your First API Call
Novita AI supports both OpenAI and Anthropic client libraries — swap it in by updating only the base URL and API key
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="deepseek/deepseek-v3.2",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)To try a different model, simply change the model parameter — no other configuration changes needed. Browse the full catalog at novita.ai/models.
Conclusion
When the data is laid out side by side, the picture is clear: Novita AI leads among third-party inference providers on the combination of model catalog breadth, competitive pricing, and verified output quality. For most production workloads — especially those involving reasoning models or multi-model pipelines — it offers strong overall value.
Novita AI is available now — no GPU setup, no reserved capacity, pay only for what you use. Start with the code examples above, or explore the full model catalog in the Novita AI Playground.
Novita AI is an AI & agent cloud platform helping developers and startups build, deploy, and scale models and agentic applications with high performance, reliability, and cost efficiency.
Frequently Asked Questions
Can I switch to Novita AI from another inference provider without rewriting my code?
In most cases, yes. Novita AI’s API is compatible with both the OpenAI and Anthropic client libraries. If you’re already using either SDK, switching requires changing only the base URL and your API key — no changes to your prompt logic, model call structure, or response parsing are needed. Check the model’s documentation page on Novita AI to confirm which client library it supports. For a full checklist on evaluating platforms before committing to avoid LLM API lock-in, see How to Switch LLM API Providers Without Lock-In: Platform Checklist.
Why does output quality differ between providers running the same model?
Even with identical model weights, inference quality varies based on how each provider configures quantization, batching, and serving infrastructure. Artificial Analysis measures this directly through repeated benchmark runs on live endpoints — and the differences are real, not theoretical.
How does Novita AI pricing compare to self-hosting gpt-oss-120B?
gpt-oss-120B fits on a single 80GB GPU (NVIDIA H100 or AMD MI300X). A cloud H100 instance costs roughly $2–3/hour. At Novita AI’s rate of $0.05/1M input tokens, you’d need to process around 40–60M input tokens per hour to break even on infrastructure costs — making the API significantly more cost-effective for most teams that don’t run at that constant throughput.



