

MiniMax M2.5 matches GLM 5’s 77.8% SWE-bench Verified score with an 80.2% result — at one-third the API cost on Novita AI. Released within 24 hours of each other in February 2026, these two Chinese MoE models take different approaches to AI agents. GLM 5 scales to 754B parameters with 40B active, targeting complex systems engineering with a 200K context window and DeepSeek sparse attention. MiniMax M2.5 keeps 228.7B parameters total with spec-writing capabilities, trained across 200,000 real-world RL environments. The choice comes down to whether you need GLM 5’s architectural depth for multi-hour debugging sessions or M2.5’s low cost for high-volume agent pipelines.
Model Overview of MiniMax M2.5 and GLM 5
GLM 5’s 754B-parameter MoE architecture activates 40B parameters per inference, making it 3.2x larger than M2.5’s 228.7B total. This gap reveals distinct design philosophies that cascade through every performance dimension.
| Architecture Component | GLM 5 | MiniMax M2.5 |
|---|---|---|
| Total Parameters | 754B (40B active) | 229B |
| Expert Architecture | 256 routed experts, Top-8, 1 shared expert | 256 local experts, Top-8 selection |
| Attention Mechanism | DeepSeek Sparse Attention (DSA) | Standard attention |
| Hidden Layers | 78 layers, 6144 hidden size | 62 layers, 3072 hidden size |
| Context Window | 202,752 tokens (200K) | 196,608 tokens (197K) |
| Training Data | 28.5T tokens | Not disclosed |
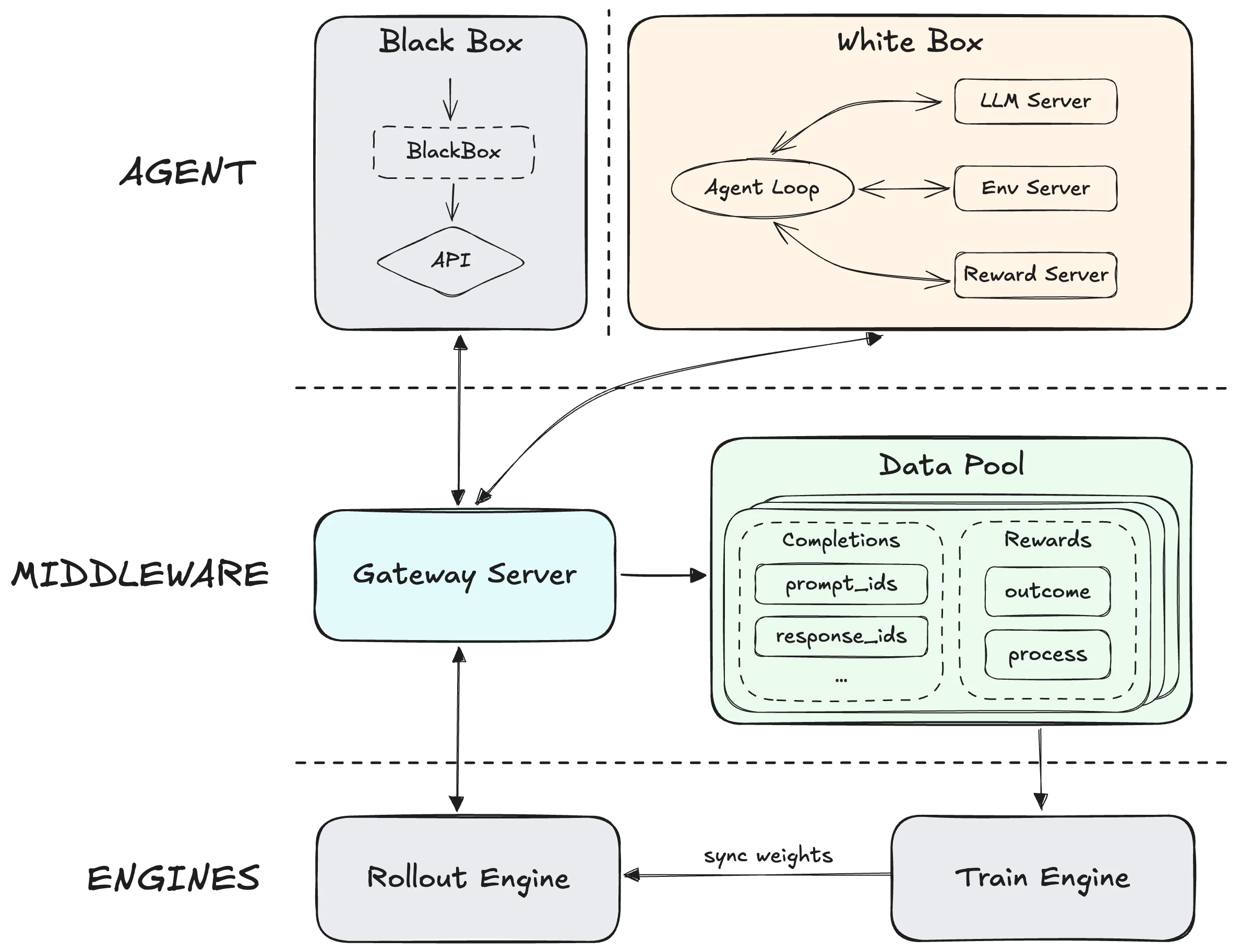
| RL Framework | Slime (asynchronous RL) | Forge (agent-native RL, 200K+ environments) |
DeepSeek Sparse Attention is GLM 5’s key architectural feature. It keeps long-context performance high while cutting deployment costs. The 202K vs 197K context difference looks small on paper, but GLM 5’s DSA maintains coherence across that full window without quadratic memory scaling. MiniMax M2.5 compensates with task decomposition efficiency rather than raw context capacity.
DSA Introduction By kaitchup
Forge Introduction By MiniMax
The RL training gap tells a deeper story. GLM 5’s Slime framework enables asynchronous RL at unprecedented scale, pushing pre-training and post-training boundaries simultaneously. MiniMax’s Forge framework decouples the training engine from agents entirely, optimizing for generalization across scaffolds rather than single-task mastery. You’re choosing between a model trained to handle anything thrown at it (GLM 5) versus one trained in the exact environments your agents will face (M2.5’s 200K+ real-world training scenarios).
Try GLM 5 and MiniMax M2.5 Now!
Head-to-Head Coding Battle of MiniMax M2.5 and GLM 5
M2.5’s 80.2% SWE-bench Verified score edges GLM 5’s 77.8%, putting both within striking distance of Claude Opus 4.6’s 80.9%.
| Coding Benchmark | GLM 5 | MiniMax M2.5 | What It Measures |
|---|---|---|---|
| SWE-bench Verified | 77.8% | 80.2% | Real GitHub PR resolution |
| SWE-bench Multilingual | 73.3% | 74.1% | Cross-language bug fixing |
| Terminal-Bench 2.0 | 56.2% | 51.7% | CLI environment manipulation |
The gap emerges in how they achieve similar scores. Kilo AI’s controlled testing reveals the pattern: GLM 5 excels at agentic engineering — iterative debugging cycles where the model self-reflects on compiler errors and refactors until tests pass. It scored perfect 35/35 on the API-from-spec test by writing 94 test cases, creating reusable middleware, and using standard database patterns. Zero bugs across three autonomous runs.
M2.5 wins on spec-writing — the architect’s approach. Before touching code, it decomposes features into structure, UI design, and system boundaries. On the bug-hunt task, M2.5 documented every fix with inline comments and preserved all original API contracts, scoring 28/30 versus GLM 5’s 24.5/30. The catch: M2.5 completed all tests in 21 minutes versus GLM 5’s 44 minutes, but produced a critical authorization bug in the attachments endpoint that GLM 5’s comprehensive testing would have caught.

Test From Kilo Code
Key Takeaway: GLM 5’s self-reflection loops shine when you’re building from scratch and need bulletproof code. M2.5’s upfront planning dominates when working with legacy codebases where minimal changes and clear documentation matter more than perfect architecture. Real developers report M2.5 requires more babysitting but finishes faster, while GLM 5 aligns better with intent at the cost of occasional rate limits. GLM 5 builds more and tests more. MiniMax M2.5 changes less and finishes faster.
https://www.youtube.com/watch?v=t94H-DkFIys
Try GLM 5 and MiniMax M2.5 Now!
Agentic Performance of MiniMax M2.5 and GLM 5
GLM 5 dominates tool-calling benchmarks. It scores 67.8% on MCP-Atlas (Public Set), 38% on Tool-Decathlon, and 89.7% on τ²-Bench. These aren’t generic function-calling tests; they measure whether an agent can chain 5-10 tool invocations to solve real research tasks.
M2.5’s edge shows in decision efficiency. Across BrowseComp, Wide Search, and RISE, M2.5 achieves better results using 20% fewer search rounds than M2.1. It learned to solve problems with more precise queries rather than exhaustive exploration. That efficiency compounds in production: when your agent runs 1,000 research tasks per day, M2.5’s token efficiency cuts costs by 20% before you even factor in its lower API pricing.
| Agent Benchmark | GLM 5 | MiniMax M2.5 | Test Scenario |
|---|---|---|---|
| BrowseComp (w/ Context Manage) | 75.9% | 75.1%~76.3% | Real browsing with history discard strategy |
| RISE (Internal) | Not disclosed | 50.2% | Professional research tasks |
| BFCL | Not disclosed | 76.8% | |
| τ²-Bench | 89.7% | Not disclosed | Tool selection and sequencing |
| MCP-Atlas (Public Set) | 67.8% | Not disclosed | MCP server integration tasks |
Cost Analysis of MiniMax M2.5 and GLM 5
M2.5’s $0.30 input / $1.20 output per 1M tokens undercuts GLM 5’s estimated $1.00 input / $3.20 output by 70% on input, 62.5% on output. Running M2.5 continuously costs $1/hour ($8,760/year). GLM 5’s pricing puts continuous operation around $2.80/hour ($24,528/year) — 2.8x more for comparable uptime.
| Cost Scenario | GLM 5 | MiniMax M2.5 | MiniMax M2.5 Highspeed |
|---|---|---|---|
| API Pricing (1M tokens) | $1.00 in / $3.20 out | $0.30 in / $1.20 out | $0.60 in / $2.4 out |
| Cache Read | $0.2 /Mt | $0.03 /Mt | $0.03 /Mt |
| OpenClaw Daily Usage (500K in / 100K out) | $0.82/day | $0.27/day | $0.54/day |
Cache Read refers to the cost of reading tokens that were previously stored in the prompt cache. When the same prompt content is reused across requests, the model retrieves these tokens directly from the cache instead of processing them again from scratch. This reduces both inference latency and cost.
Try GLM 5 and MiniMax M2.5 Now!
Use Case Recommendations of MiniMax M2.5 and GLM 5
Choose MiniMax M2.5 when speed-cost dominance matters more than architectural flexibility. Customer-facing agents requiring sub-second responses at scale — chatbots handling 10K+ conversations/day, code completion across developer teams, automated documentation generation — all benefit from M2.5’s high throughput and 3x lower API cost.
Choose GLM 5 when architectural depth and customization needs outweigh cost constraints. Research environments requiring full codebase context, multi-hour debugging sessions, or integration with custom tool stacks favor GLM 5’s 200K context window and MCP-Atlas/Tool-Decathlon dominance. The 754B-parameter scale with DeepSeek sparse attention maintains coherence across complex systems engineering tasks that would cause M2.5 to lose context mid-session.
| Use Case Category | GLM 5 | MiniMax M2.5 | Deciding Factor |
|---|---|---|---|
| Customer-Facing Agents | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | cheap API Price |
| Complex Systems Engineering | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | 200K context + DSA for multi-hour sessions |
| High-Volume Automation (10K+ tasks/day) | ⭐⭐ | ⭐⭐⭐⭐⭐ | 3x cheaper API = 3x more tasks per dollar |
| Exploratory Development | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | M2.5’s 21-min task time vs GLM 5’s 44 min on kilo test |
| Custom Tool Stack Integration | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | 67.8% MCP-Atlas, 89.7% τ²-Bench |
| Multilingual Codebase Maintenance | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | 73.3% vs 51.3% SWE-bench Multilingual |
| Office Productivity (Word/Excel/PPT) | ⭐⭐ | ⭐⭐⭐⭐⭐ | 59% win rate vs mainstream models (GDPval-MM) |
Try GLM 5 and MiniMax M2.5 Now!
How to Access Both Models via Novita AI?
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.

Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
Try GLM 5 and MiniMax M2.5 Now!
Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

Step 5: Install the API
Install API using the package manager specific to your programming language.
After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-5 or minimax/minimax-m2.5",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)The One Question Test: Do you need customization or just performance? If your workflow requires fine-tuning, self-hosting, or integration with proprietary tool stacks → GLM 5’s architectural flexibility and MIT license justify the premium. If you’re shipping agents that need to scale to millions of invocations without budget constraints → M2.5’s low-cost intelligence becomes your moat. The Chinese open model landscape just forced every competitor to recalibrate what “affordable AI” means in 2026.
Frequently Asked Questions
Which model is better for coding tasks, MiniMax M2.5 or GLM 5?
MiniMax M2.5 performs better for coding tasks with 80.2% on SWE-bench Verified, slightly outperforming GLM 5.
Which model is better for agentic workflows, MiniMax M2.5 or GLM 5?
GLM 5 performs better for complex agentic workflows with stronger results on HLE with tools and Terminal-Bench than MiniMax M2.5.
Can MiniMax M2.5 and GLM 5 run on consumer GPUs?
Both MiniMax M2.5 and GLM5 require large VRAM and are typically accessed through APIs rather than consumer GPUs.
Novita AI is an AI & agent cloud platform helping developers and startups build, deploy, and scale models and agentic applications with high performance, reliability, and cost efficiency.
Recommended Reading



