

When building autonomous AI applications in 2026, choosing between MiniMax-M2.1 and DeepSeek V3.2 often comes down to a critical trade-off: agentic versatility versus raw reasoning power.
This comparison dissects the architectural differences, benchmark performance across all variants, hardware requirements (from RTX 4090s to H100 clusters), pricing structures, and real-world deployment trade-offs. Whether you’re building autonomous coding agents, scientific reasoning systems, or cost-sensitive production APIs, understanding which model family fits your use case can save thousands in compute costs and weeks of integration work.
Quick Answer: Which Model Should You Choose?
Choose MiniMax-M2.1 if you need:
- Autonomous coding agents with strong tool-calling reliability (agentic workflows, SWE-bench pipelines)
- Stable multi-step execution in frameworks like Droid / mini-swe-agent
- Multilingual engineering (Python, Java, C++, Rust, Kotlin)
- Higher output-heavy efficiency for long code generation and iterative patching
- More practical GPU deployment (realistic on 4× H100 80GB or 4× L40S 48GB)
Choose DeepSeek V3.2 (or Speciale) if you need:
- Deep reasoning power for complex logical inference and analysis-heavy tasks
- Math / competition-level performance (Speciale dominates AIME 2025, GPQA, reasoning benchmarks)
- Reasoning-heavy coding (LiveCodeBench-style algorithmic and difficult programming tasks)
- Input-heavy workloads like long document analysis and knowledge reasoning
- Data-center scale deployment (often requires 16×+ H100-class GPUs even with quantization)
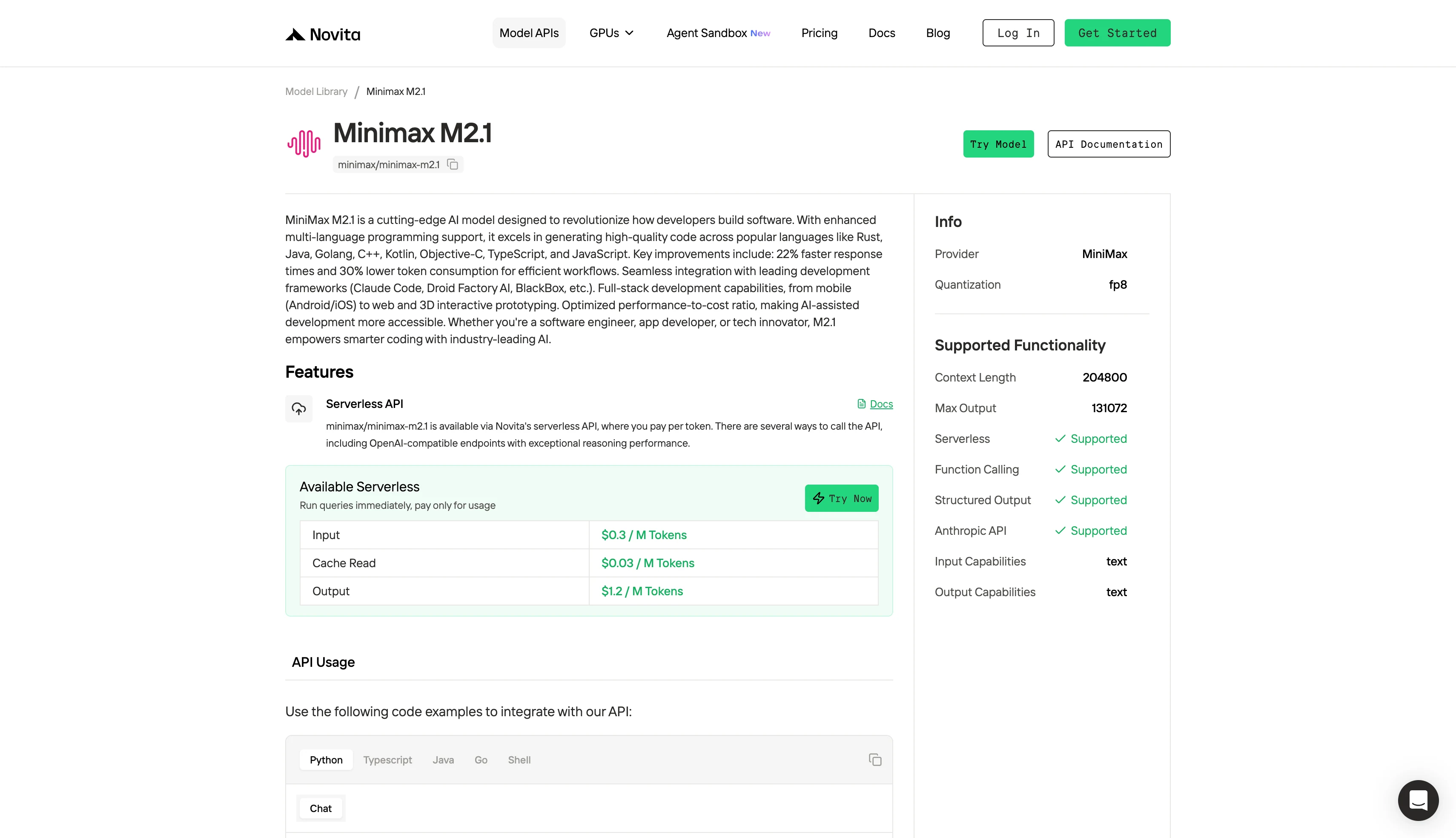
Architecture of Minimax M2.1 and Deepseek V3.2
| Specification | MiniMax-M2.1 | DeepSeek V3.2 (All Variants) |
|---|---|---|
| Total Parameters | 228.7B | 685B |
| Active Parameters (per token) | 10B | 37B |
| Context Length | 128K-204.8K tokens | 128K tokens |
| Precision | FP8 | FP8/BF16/F32 |
| Multimodal Support | Text, audio, images, video | Text only |
| Release Date | December 23, 2025 | December 2025 |
DeepSeek V3.2 Variant Breakdown
- Deepseek V3.2 Standard and Thinking mode variants are the same base model weights. The difference is how the model is run: one prioritizes a default reasoning balance, the other enables explicit extended reasoning before output.
- Deepseek V3.2 Speciale is a distinct variant tuned for maximum reasoning power but at the expense of tool integration and typical agent capabilities, getting Gold-medal IMO/CMO/ICPC/IOI 2025!
- Deepseek V3.2 Exp is an experimental branch designed to explore new architectural efficiencies (sparse attention) and is not strictly the same as the primary V3.2 training.
Benchmark Comparison of Minimax M2.1 and Deepseek V3.2
DeepSeek V3.2 (Standard) is generally competitive with MiniMax-M2.1 on real-world SWE-bench style coding tasks, but MiniMax-M2.1 tends to show stronger overall robustness across multilingual software engineering and agent frameworks.
In practice, DeepSeek V3.2 is a strong general coding + agent model, but MiniMax-M2.1 is usually better optimized for end-to-end engineering execution, framework generalization, and tool-use reliability in complex multi-step coding pipelines.
| Benchmark | MiniMax M2.1 | DeepSeek V3.2 | Claude Opus 4.5 | Notes |
|---|---|---|---|---|
| SWE-bench Verified | 74.0 | 73.1 | 80.9 | Real-world GitHub issue resolution |
| Multi-SWE-bench | 49.4 | 37.4 | 50.0 | MiniMax outperforms Claude Sonnet 4.5 (44.3) |
| SWE-bench Multilingual | 72.5 | 70.2 | 77.5 | Python, Java, C++, Rust, Kotlin |
| Terminal-bench 2.0 | 47.9 | 46.4 | 57.8 | CLI and shell scripting |
| Framework/Benchmark | MiniMax-M2.1 | DeepSeek V3.2 | Claude Opus 4.5 |
|---|---|---|---|
| SWE-bench Verified (Droid) | 71.3 | 67.0 | 75.2 |
| SWE-bench Verified (mini-swe-agent) | 67.0 | 60.0 | 74.4 |
| SWT-bench (Test Generation) | 69.3 | 62.0 | 80.2 |
| SWE-Review (Code Review) | 8.9 | 6.4 | 16.2 |
| OctoCodingbench | 26.1 | 26.0 | 36.2 |
DeepSeek V3.2 Speciale is essentially a high-compute reasoning-optimized variant compared to both DeepSeek V3.2 Standard and MiniMax-M2.1: it tends to outperform them on math-heavy and deep reasoning benchmarks such as AIME 2025, GPQA, and reasoning-intensive coding evaluations like LiveCodeBench, making it better suited for difficult algorithmic problems and competition-style tasks.
| Metric Category | MiniMax-M2.1 | DeepSeek V3.2 Speciale |
|---|---|---|
| Intelligence Index (overall reasoning) | 39.5 | 34.1 |
| Coding Index | 32.8 | 37.9 |
| Math Index | 82.7 | 96.7 |
| GPQA (grad-level reasoning) | 83.0 % | 87.1 % |
| MMLU Pro (advanced knowledge) | 87.5 % | 86.3 % |
| HLE (hard language evaluation) | 22.2 % | 26.1 % |
| LiveCodeBench (real-world coding) | 81.0 % | 89.6 % |
| AIME 2025 (advanced math) | 82.7 % | 96.7 % |
| SciCode (scientific code) | 40.7 % | 44.0 % |
| LCR (code review) | 59.0 % | 59.3 % |
| IFBench (instruction-following) | 69.9 % | 63.9 % |
| TerminalBench Hard (CLI command generation) | 28.8 % | 34.8 % |
DeepSeek V3.2’s strength lies in its high capability for large-scale reasoning, complex logical inference, and strong general language understanding.
MiniMax-M2.1 focuses more on code quality, adaptation to engineering tasks, and handling long conversational contexts, and it typically scores higher on software development-oriented benchmarks.
VRAM Requirements of Minimax M2.1 and Deepseek V3.2
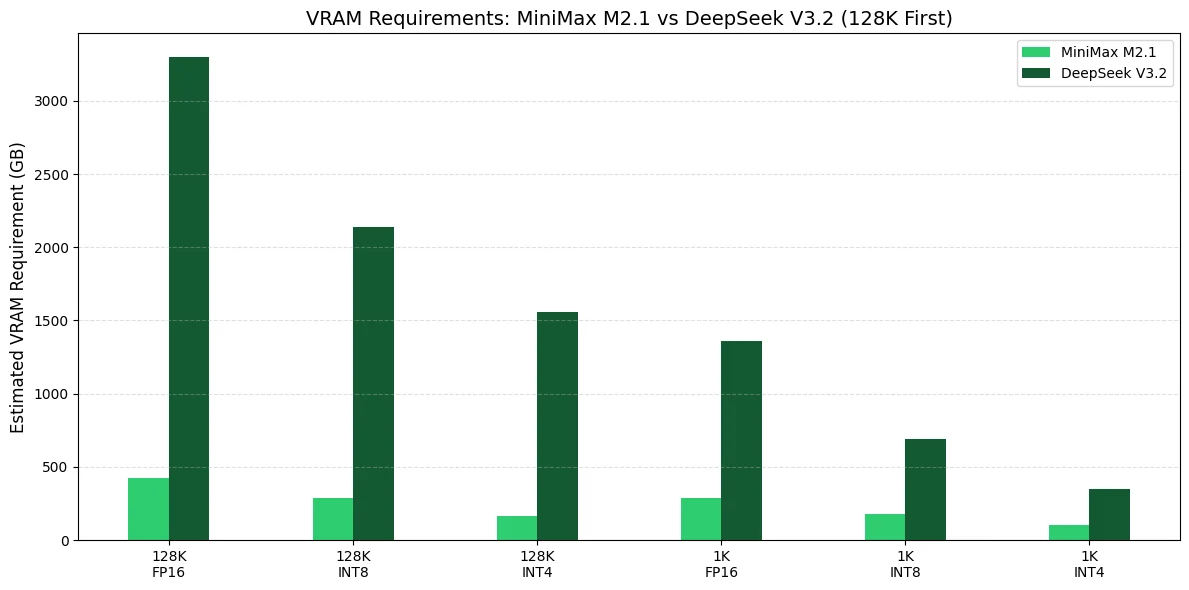
For your own agent production setup, I’d recommend very different GPU strategies for MiniMax M2.1 vs DeepSeek V3.2, because their VRAM footprints are on completely different scales.
Recommended GPU for MiniMax M2.1
Best practical choice: 4× H100 80GB (or 4× H200 141GB if budget allows)
- Stable for long multi-step tool-calling workflows
- Enough VRAM headroom for larger contexts + KV cache
- Good throughput and reliability for SWE-bench style agent pipelines
Cost-efficient alternative: 4× L40S 48GB (INT4/INT8 quantized)
- Good for personal deployment
- Much cheaper than H100
- Still realistic for agent workflows
Not recommended unless budget is tight: 8× RTX 4090 24GB
- Can work, but PCIe bottlenecks and multi-GPU communication will hurt agent latency.
Conclusion: MiniMax M2.1 is the clear winner if you want a realistic “personal production agent” model.
Recommended GPU for DeepSeek V3.2
Minimum realistic setup: 16× H100 80GB (INT4/INT8)
- DeepSeek V3.2 requires massive VRAM even with quantization
- Tool-calling agents will be expensive to run continuously
More realistic production setup: 32× H100 80GB (or 16× H200 141GB)
- Needed if you want long context (128K) without constant memory pressure
- Better stability and throughput
Conclusion: DeepSeek V3.2 is more of a data-center model. It’s not cost-efficient for personal agent production unless you already have a GPU cluster.
If your goal is a stable, scalable coding agent system, go with:
MiniMax M2.1 + 4× H100 80GB (best balance of performance, context, and deployment feasibility).
On-Demand is a pay-as-you-go model billed strictly by runtime, offering maximum flexibility for variable workloads and experimentation since you only pay while the GPU is running.
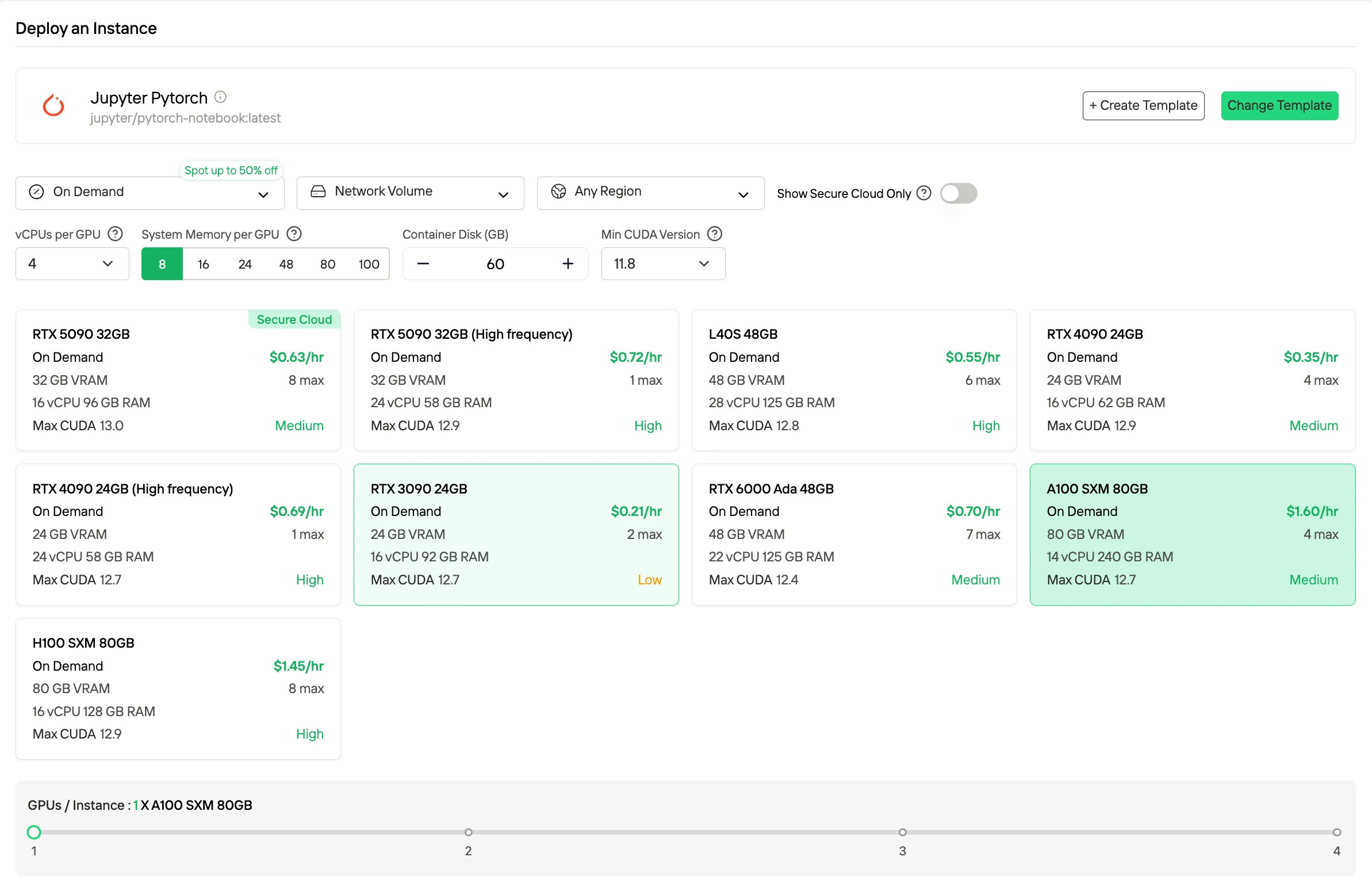
If you want lower cost, Spot Instances are typically up to 50% cheaper by using idle capacity, but they can be interrupted, so they are best for fault-tolerant or batch workloads.
Cost Analysis of Minimax M2.1 and Deepseek V3.2
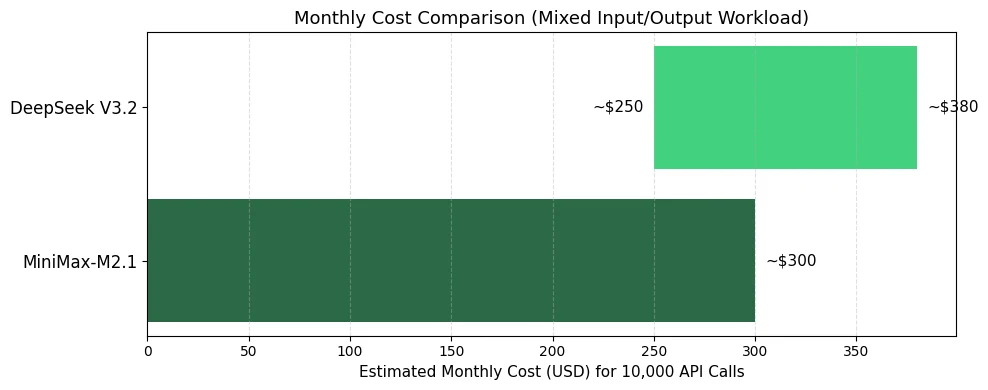
- Choose MiniMax-M2.1 for: High output-to-input ratio workloads, agent tasks with tool calling, applications requiring lower overall blended costs
- Choose DeepSeek V3.2 for: Input-heavy workloads (e.g., document analysis), specialized reasoning tasks where quality justifies slightly higher costs
How to Access Minimax M2.1 and Deepseek V3.2
Option 1: Fast API
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.

Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.1",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)Option 2: Multi-Agent Workflows with OpenAI Agents SDK
Build advanced multi-agent systems by integrating Novita AI with the OpenAI Agents SDK:
- Plug-and-play: Use Novita AI’s LLMs in any OpenAI Agents workflow.
- Supports handoffs, routing, and tool use: Design agents that can delegate, triage, or run functions, all powered by Novita AI’s models.
- Python integration: Simply point the SDK to Novita’s endpoint (
https://api.novita.ai/v3/openai) and use your API key.
Option 3:Connect GLM 4.7 Flash API on Third-Party Platforms
- Hugging Face: Use GLM 4.7 and MInimax M2.1 in Spaces, pipelines, or with the Transformers library via Novita AI endpoints.
- Agent & Orchestration Frameworks: Easily connect Novita AI with partner platforms like Continue, AnythingLLM,LangChain, Dify and Langflow through official connectors and step-by-step integration guides.
- OpenAI-Compatible API: Easily connect Novita AI with partner platforms like Claude code,Cursor,Trae,Continue, Codex, OpenCode, AnythingLLM,LangChain, Dify and Langflow through official connectors and step-by-step integration guides.
For autonomous agents, multilingual coding, and cost-sensitive production, choose MiniMax-M2.1. For scientific reasoning, competitive programming, or specialized mathematical tasks, select the appropriate DeepSeek V3.2 variant—Standard for balanced daily use, Speciale for maximum reasoning, Thinking for chain-of-thought problem-solving, or Exp for long-context research.
Frequently Asked Questions
Which model is better for autonomous coding agents, MiniMax-M2.1 or DeepSeek V3.2?
MiniMax-M2.1 is usually better than DeepSeek V3.2 for tool-calling coding agents and multi-step SWE-bench workflows.
Which model is stronger for math and competition-level reasoning, MiniMax-M2.1 or DeepSeek V3.2?
DeepSeek V3.2 Speciale is stronger than MiniMax-M2.1 for AIME-style math and deep reasoning benchmarks.
Which is easier to deploy for personal production, MiniMax-M2.1 or DeepSeek V3.2?
MiniMax-M2.1 is far easier to deploy than DeepSeek V3.2, requiring much smaller GPU clusters.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing affordable and reliable GPU cloud for building and scaling.



