

Developers choosing between GLM-4.7 Flash and Qwen3-30B-A3B-Thinking-2507 face a clear trade-off: software engineering mastery versus reasoning depth. Both are 30B-class MoE models with around 3B active parameters per token, long context windows (202K for GLM-4.7 Flash, 262K for Qwen3), and similar VRAM requirements. The divergence lies in what they’re optimized for: GLM-4.7 Flash for agentic coding workflows (tool calling, web browsing, code generation), Qwen3-30B-A3B-Thinking-2507 for multi-step reasoning with dedicated “thinking mode” that exposes internal reasoning traces.
Which Model Should You Choose?
| Choose GLM-4.7 Flash if you need: | Choose Qwen3-30B-A3B-Thinking-2507 if you need: |
|---|---|
| • Software engineering tasks (59.2% SWE-bench Verified) • Browser-based task automation (42.8% BrowseComp vs 2.29%) • Agentic tool calling (79.5% τ²-Bench vs 49.0%) • Lower-latency coding agents • Tasks requiring strong web navigation and automation • Real-time code generation and refactoring | • Multi-step logic with exposed reasoning traces • Scientific research and academic problem-solving • Instruction-following tasks (88.9% IFEval) • Multilingual comprehension and long-context analysis |
Architecture Comparison
Both are 30B‑class MoE models with around 3B active parameters and long context windows, and they have broadly similar VRAM requirements.
| Aspect | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| Total Parameters | 30B | 31B |
| Active Parameters (per token) | 3B (64 experts, 4 active) | 3.3B (128 experts, 8 active) |
| Context Length | 202,752 tokens | 262,144 tokens |
| Hidden Layers | 47 | 48 |
| Attention Heads | 20 (standard) | 32 Q / 4 KV (GQA) |
| Precision | bfloat16 | bfloat16 |
| Multimodal Support | No (text-only) | No (text-only) |
| Special Features | Browser automation, tool calling | Thinking mode (reasoning traces) |
Key architectural difference: Qwen3 uses Grouped Query Attention (32 Q-heads, 4 KV-heads) for efficient KV cache management during long-context inference, while GLM-4.7 Flash uses standard attention with fewer heads (20). Qwen activates 8 experts per token (vs. 4 in GLM-4.7 Flash), providing more routing flexibility at the cost of slightly higher compute per forward pass.
Both models have nearly identical parameter efficiency (3B active). However, GLM-4.7 Flash trades some reasoning depth for faster tool execution, while Qwen3 focuses more on deeper multi-step reasoning through its thinking-mode architecture.
Benchmark Comparison
The performance gap between these models emerges clearly when grouped by task type. We’ve organized benchmarks into three categories: coding/engineering, reasoning/academic, and specialized capabilities.
Coding & Software Engineering Benchmarks
| Benchmark | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| SWE-bench Verified | 59.2% 🏆 | 22.0% |
| τ²-Bench (Tool Use) | 79.5% 🏆 | 49.0% |
| BrowseComp | 42.8% 🏆 | 2.29% |
Source: Unsloth / Hugging Face model pages. Data as of March 2026.
Reasoning & Academic Benchmarks
| Benchmark | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| GPQA (Science QA) | 75.2%🏆 | 73.4% |
| AIME 2025 (Math) | 91.6%🏆 | 85.0% |
Source: Unsloth / Hugging Face model pages. Data as of March 2026.
Specialized Capabilities
| Benchmark | GLM-4.7 Flash | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| HLE (Human-Like Eval) | 14.4% 🏆 | 9.8% |
Source: Unsloth / Hugging Face model pages. Data as of March 2026.
Overall, GLM-4.7 Flash is positioned as an engineering- and tool-oriented model, whereas Qwen3-30B-A3B-Thinking-2507 is optimized for deep reasoning and cognition-heavy tasks.
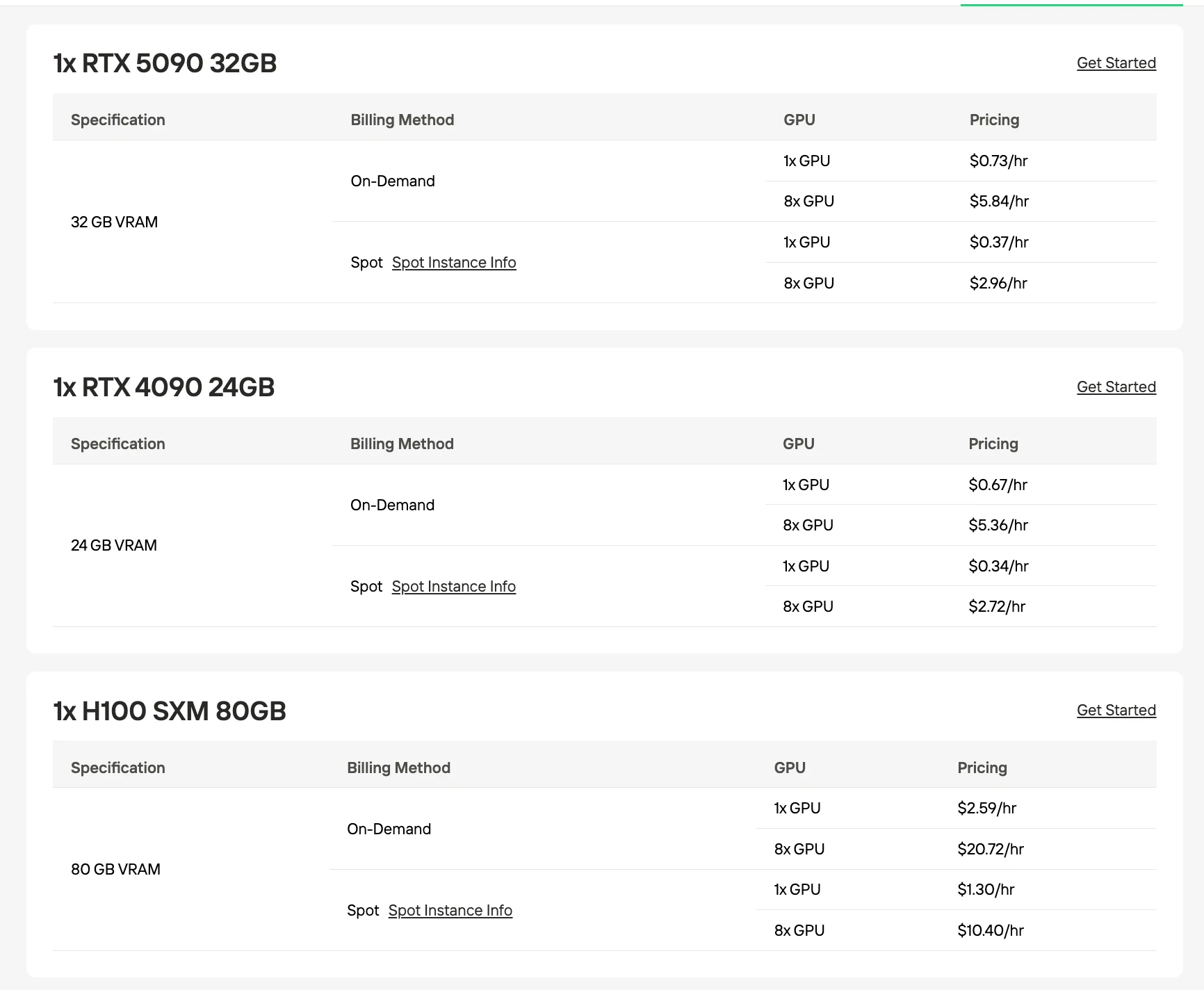
VRAM & GPU Requirements
Both models require similar base VRAM due to their shared 30B parameter count, but quantization strategies differ based on optimization focus.
Recommended GPU for GLM-4.7 Flash
| Quantization / Format | Model Size | VRAM Requirement | Recommended Setup |
|---|---|---|---|
| UD-Q4_K_XL (recommended) | 17.52 GB | 24 GB | Single RTX 4090 |
| Q4_K_M | 18.31 GB | 24 GB | Single RTX 4090 |
| Q5_K_M | 21.41 GB | 24 GB | Single RTX 4090 |
| Q8_0 | 31.84 GB | 40 GB | 2× RTX 4090 or H100 80GB |
| BF16 (full) | 60 GB | 80 GB | H100 80GB |
Source: Unsloth / Hugging Face. VRAM figures are estimates based on quantized model sizes.
Recommended GPU for Qwen3-30B-A3B-Thinking-2507
| Format | File Size | Minimum VRAM | Best For |
|---|---|---|---|
| UD-Q4_K_XL (recommended) | 17.72 GB | 24 GB | Single RTX 4090 |
| Q4_K_M | 18.56 GB | 24 GB | Single RTX 4090 |
| Q5_K_M | 21.73 GB | 24 GB | Single RTX 4090 |
| Q8_0 | 32.48 GB | 40 GB | 2× RTX 4090 or H100 80GB |
| BF16 (full) | 61 GB | 80 GB+ | H100 80GB |
Source: Unsloth / Hugging Face. VRAM figures are estimates based on quantized model sizes.
How to Access GLM-4.7 Flash or Qwen3-30B-A3B?
Both models support OpenAI-compatible API access, making integration straightforward for developers already using the OpenAI SDK.
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.

Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.7-flash",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131100,
temperature=0.7
)
print(response.choices[0].message.content)The choice between GLM-4.7 Flash and Qwen3-30B-A3B-Thinking-2507 comes down to a clear specialization: GLM-4.7 Flash wins decisively for software engineering agents (59.2% SWE-bench, 79.5% τ²-Bench, 42.8% BrowseComp) at an unbeatable $0.47/1M blended cost via Novita AI. For developers building Claude Code integrations, terminal automation, or browser-based agents, GLM-4.7 Flash is the obvious choice—its 2.7× SWE-bench advantage over Qwen3 (59.2% vs 22.0%) and rock-bottom pricing make it ideal for production coding workflows.
Conclusion
Both GLM-4.7 Flash and Qwen3-30B-A3B-Thinking-2507 are strong 30B-class MoE models with near-identical VRAM requirements, but they serve distinct use cases. GLM-4.7 Flash is the clear choice for software engineering agents, browser automation, and tool-heavy workflows. Qwen3-30B-A3B-Thinking-2507 excels when you need transparent multi-step reasoning with explicit thinking traces for research and analysis tasks.
Key Takeaway: If you’re building a coding agent or automation pipeline, go with GLM-4.7 Flash. If you need structured deep reasoning, choose Qwen3-30B-A3B-Thinking-2507. Both are available on Novita AI — try GLM-4.7 Flash or explore the full model catalog today.
Which is better for coding agents: GLM-4.7 Flash or Qwen3-30B-A3B-Thinking-2507?
GLM-4.7 Flash dominates with 59.2% on SWE-bench Verified (vs Qwen’s 22.0%) and 79.5% on τ²-Bench tool use (vs 49.0%).
Which is easier to deploy locally?
Both require ~18GB VRAM with INT4 quantization on 1× RTX 4090.
Can I run GLM-4.7 Flash in Claude Code or Trae?
Yes, both tools support custom model integration via API.
Recommended Reading
- Use GLM-4.5 in Trae to Unlock Smarter Coding Agents
- Use MiniMax M2.1 in OpenCode
- DeepSeek vs Qwen: Identify Which Ecosystem Fits Production Needs
Novita AI is an AI & agent cloud platform helping developers and startups build, deploy, and scale models and agentic applications with high performance, reliability, and cost efficiency.



