

- What Is Ling-2.6-flash?
- Hybrid Linear Architecture: How Ling-2.6-flash Gets Faster at Scale
- Token Efficiency: 15M vs. 110M to Solve the Same Benchmarks
- Benchmark Results: Where Ling-2.6-flash Leads
- Quick Comparison Table
- Access Ling-2.6-flash backed by Novita AI
- What the Community Is Saying
- Who Should Use Ling-2.6-flash?
- Get Started
- Frequently Asked Questions
Agent token bills are spiraling: multi-step tool calls, long-context planning, and extended outputs turn what looks like a cheap per-token price into a very expensive monthly invoice. The industry’s answer — chain longer reasoning traces to push benchmark scores higher — makes the economics worse, not better.
Ling-2.6-flash is a different kind of model. Built around a hybrid linear attention architecture, it achieves up to 340 tokens/s on 4× H20 hardware, delivers 2.2× the prefill throughput of Nemotron-3-Super, and uses just ~15M output tokens to complete the full Artificial Analysis Intelligence Index — roughly one-tenth of what Nemotron-3-Super consumes. In short: Ling-2.6-flash is a 104B MoE model (7.4B active) with a 256K context window, optimized for agent workloads where speed, cost, and stability matter more than a single headline benchmark. It is now available on Novita AI.
What Is Ling-2.6-flash?
Ling-2.6-flash is a sparse Mixture-of-Experts language model with 104B total parameters and 7.4B active parameters per forward pass. Developed by the Ling team (InclusionAI), it is designed as an “Instant” category model — optimized for production agent deployments where token consumption and latency are real costs, not just benchmark headlines.
- 104B total / 7.4B active parameters — MoE architecture with high sparsity
- 256K token context window — enabled by hybrid linear attention
- 340 tokens/s peak throughput on 4× H20 (TP=4)
- Hybrid 1:7 MLA + Lightning Linear attention — 4× throughput at long contexts
- Top agent benchmarks — leads BFCL-V4 (67.04), PinchBench (81.10), IFBench (58.10), Multi-IF Turn-3 (74.85)
- BF16, FP8, and INT4 variants — open-source release planned via Linghe
- Validated in production — ~100B daily tokens on OpenRouter within days of launch
Hybrid Linear Architecture: How Ling-2.6-flash Gets Faster at Scale
Most MoE models pair standard transformer attention with a sparse FFN layer. Ling-2.6-flash replaces most attention with a Lightning Linear layer, creating a 1:7 MLA + Lightning Linear hybrid. Attention cost grows linearly with context length rather than quadratically — critical for long agent sessions.
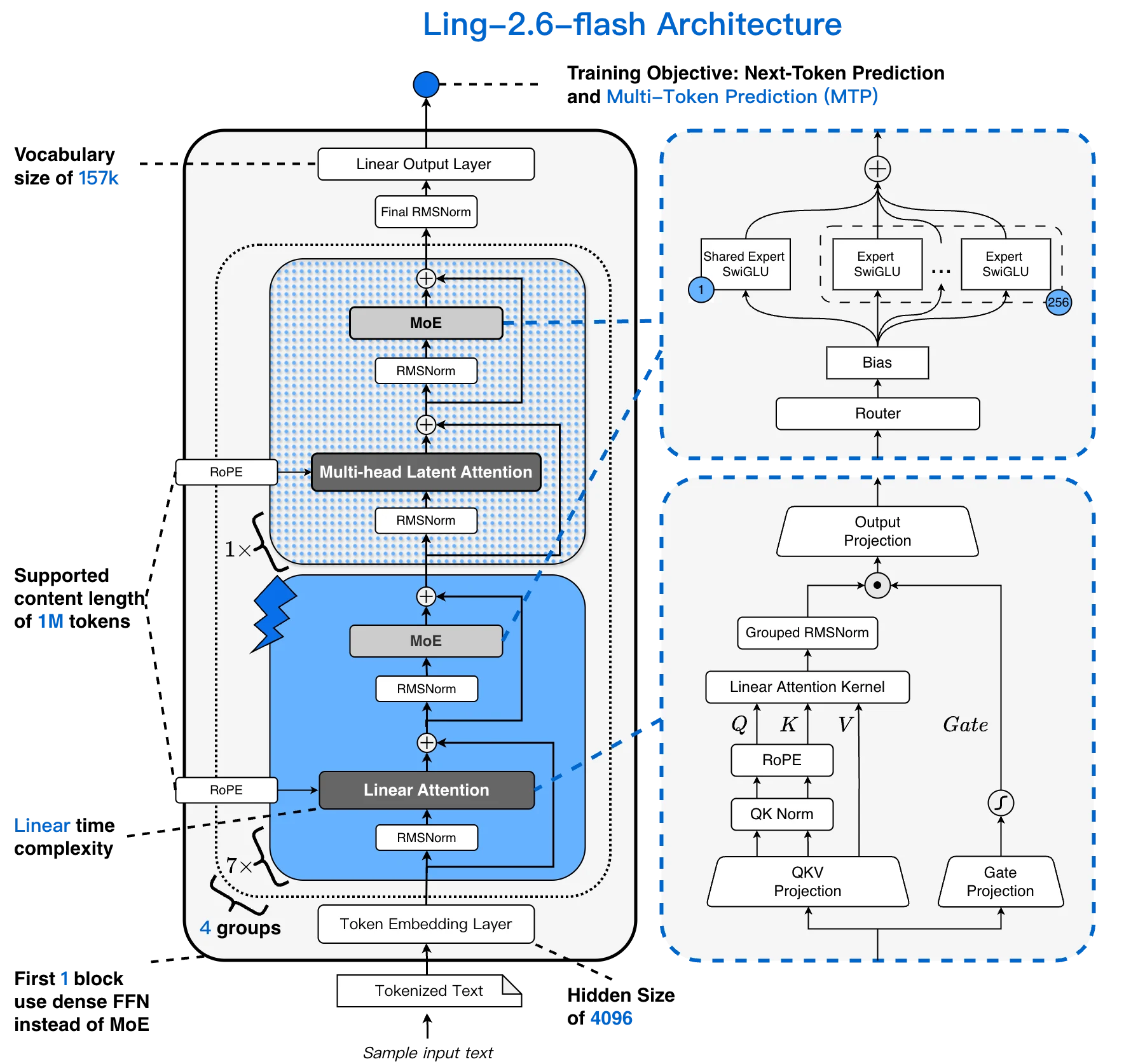
Ling-2.6-flash architecture: 157K vocabulary, 256K context, 1:7 MLA + Lightning Linear hybrid, 256 selectable experts [Source: Ling Official Blog]
Decode Throughput: Up to 4.38× at Long Outputs
On 4× H20-3e (TP=4, batch size 32), Ling-2.6-flash reaches 4.38× normalized decode throughput at 65,536-token output length vs. GLM-4.5-Air baseline. Qwen3.5-122B-A10B reaches 1.90×; Nemotron-3-Super 3.37×. The gap compounds as task output length increases.
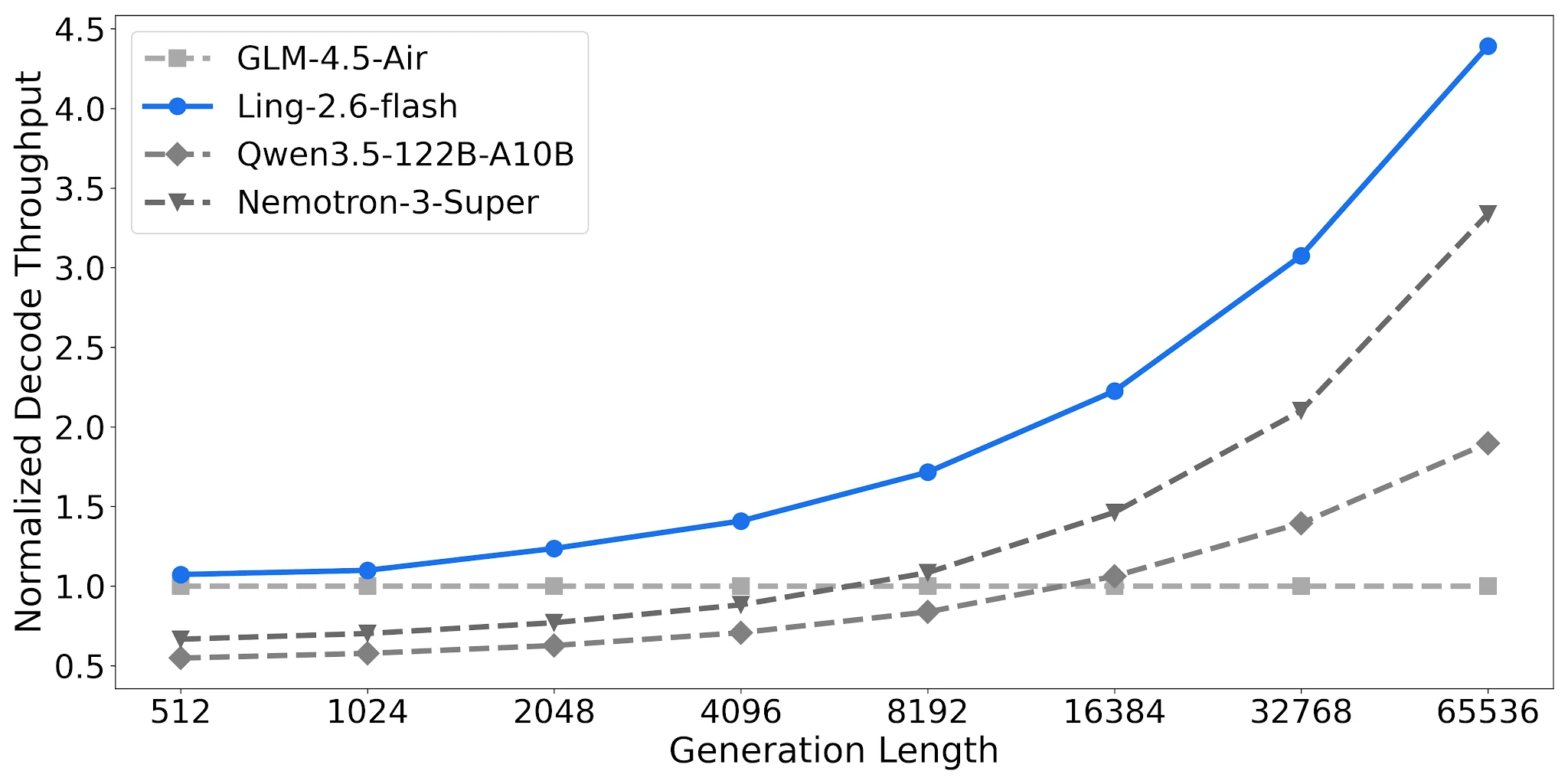
Decode Throughput Comparison, 4× H20-3e, TP=4, Batch=32 [Source: Ling Official Blog]
Prefill Throughput: 2.2× Nemotron at Long Contexts
Ling-2.6-flash achieves ~4.68× normalized prefill throughput at 65K context vs. ~2.12× for Nemotron-3-Super. For RAG pipelines and multi-turn agents with long system prompts, this directly reduces per-request cost.
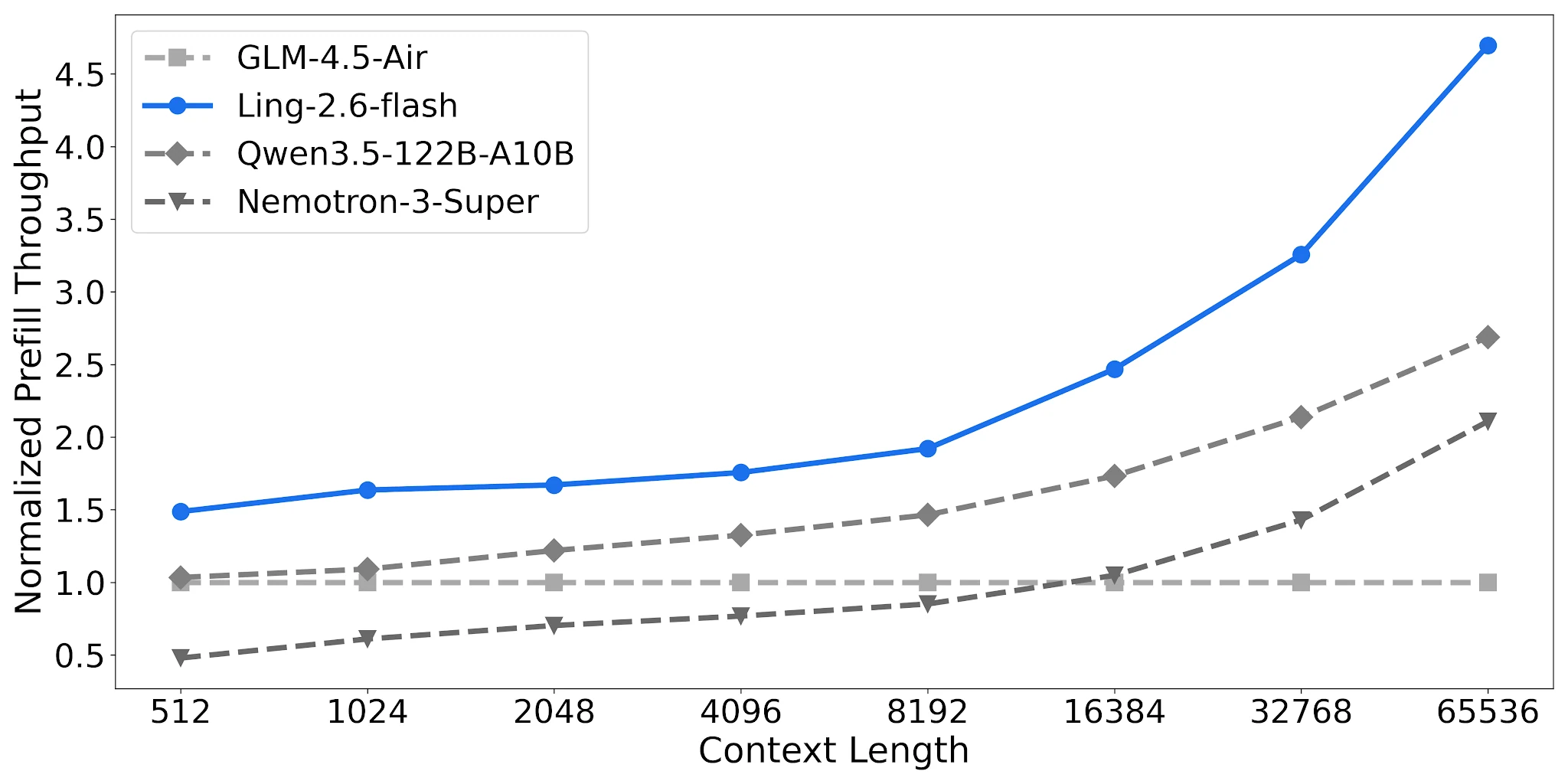
Prefill Throughput Comparison, 4× H20-3e, TP=4, Batch=32 [Source: Ling Official Blog]
Token Efficiency: 15M vs. 110M to Solve the Same Benchmarks
On the full Artificial Analysis Intelligence Index, Ling-2.6-flash uses ~15M output tokens. Nemotron-3-Super uses 110M+ — roughly 7× more — for a model that scores lower on agent tasks. For applications running hundreds of thousands of agent tasks daily, this gap is a direct line item on a cost budget.
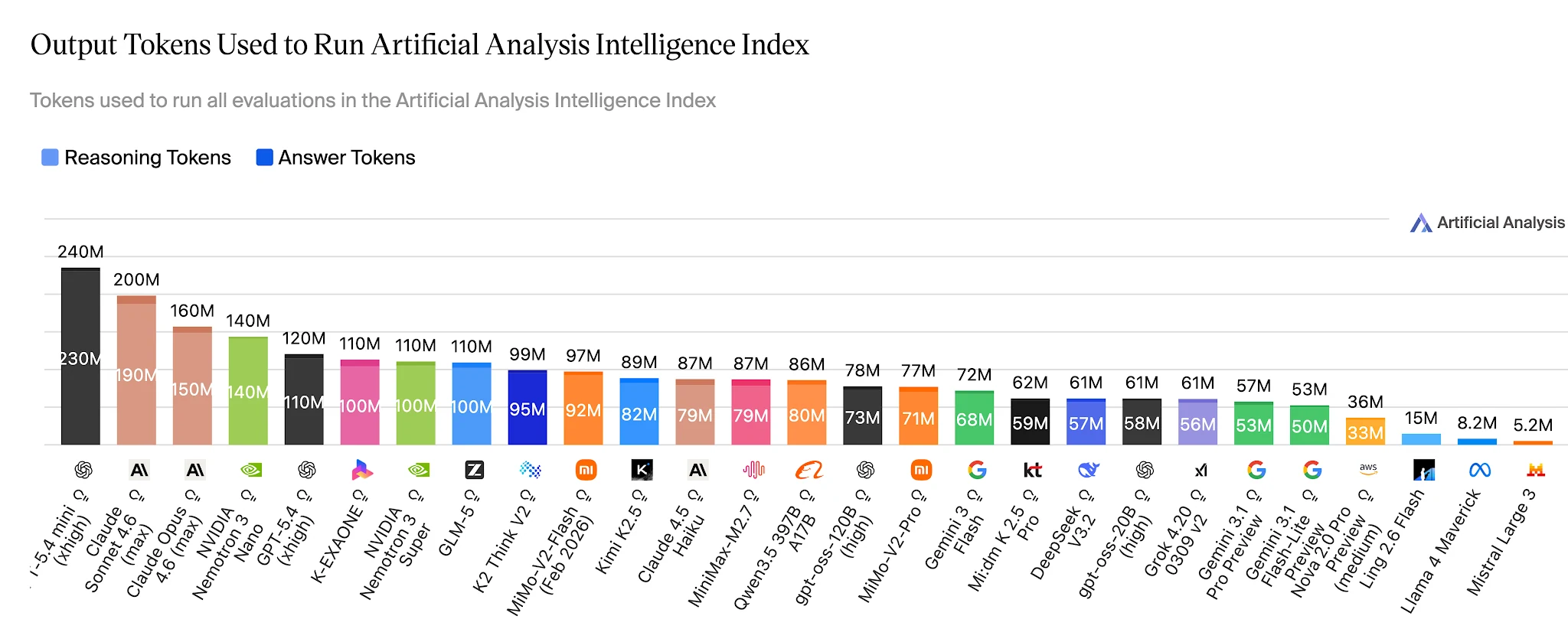
Output tokens to complete Artificial Analysis Intelligence Index — Ling 2.6 Flash: ~15M vs Nemotron-3-Super: ~110M+ [Source: Artificial Analysis]
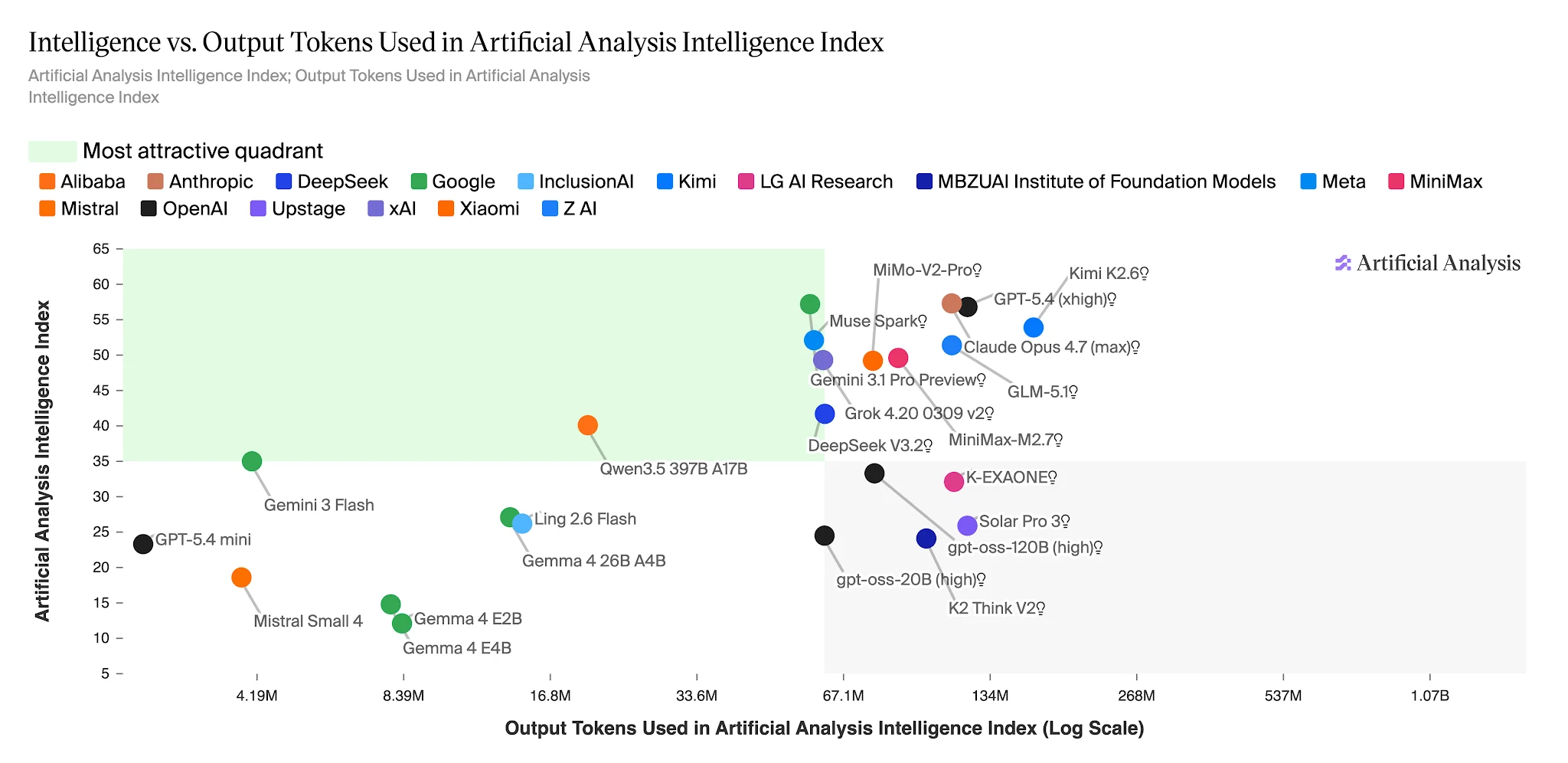
Intelligence vs. Output Tokens: Ling 2.6 Flash lands in the high-efficiency zone [Source: Artificial Analysis]
Benchmark Results: Where Ling-2.6-flash Leads
Evaluated on 19 benchmarks across 7 categories against Qwen3-57B-A14B, Qwen3.5-122B-A10B, GLM-4.5-Air, Nemotron-3-Super, and MiniMax-M1-80k:
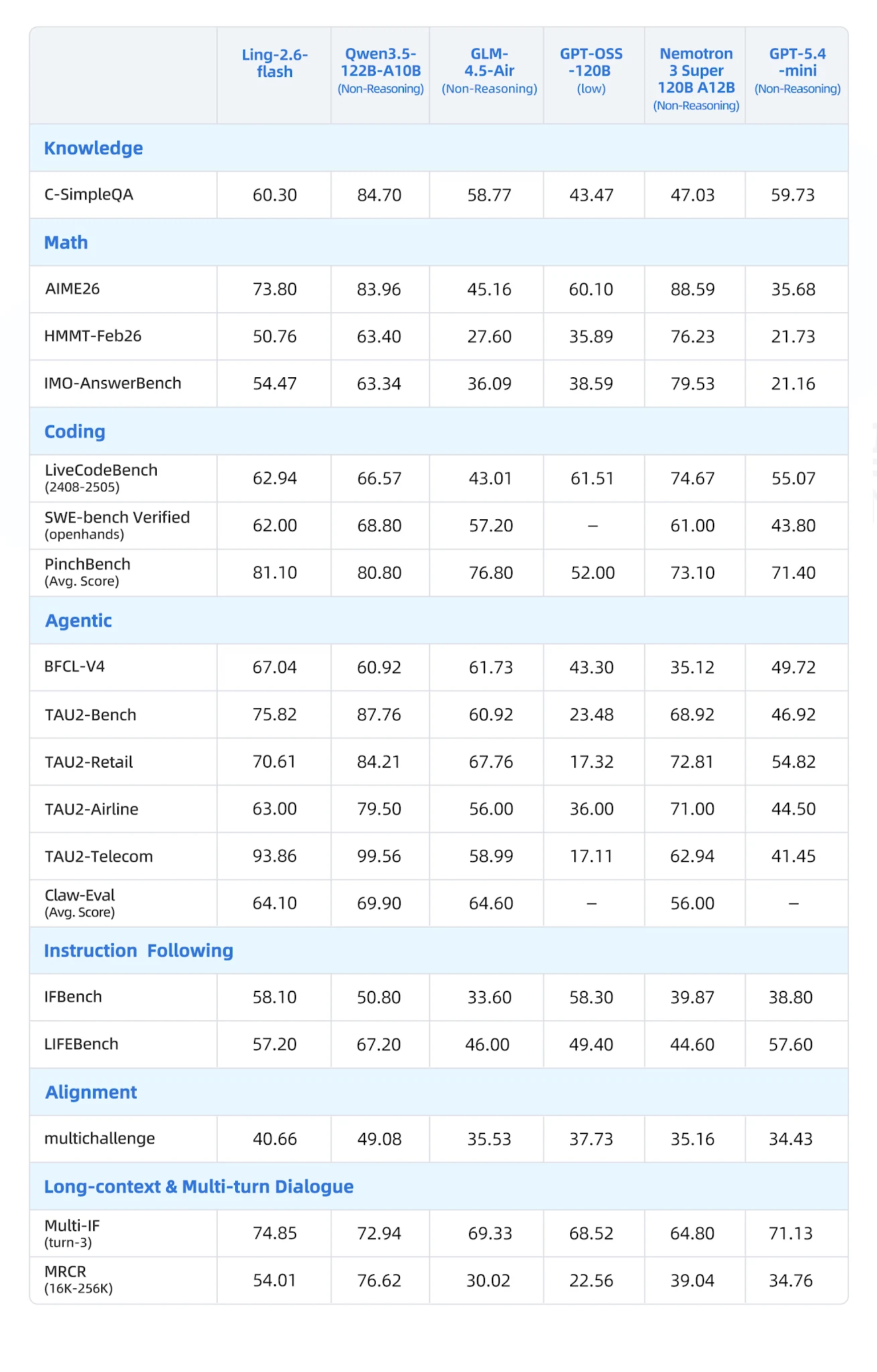
Comprehensive benchmark table [Source: Ling Official Blog]
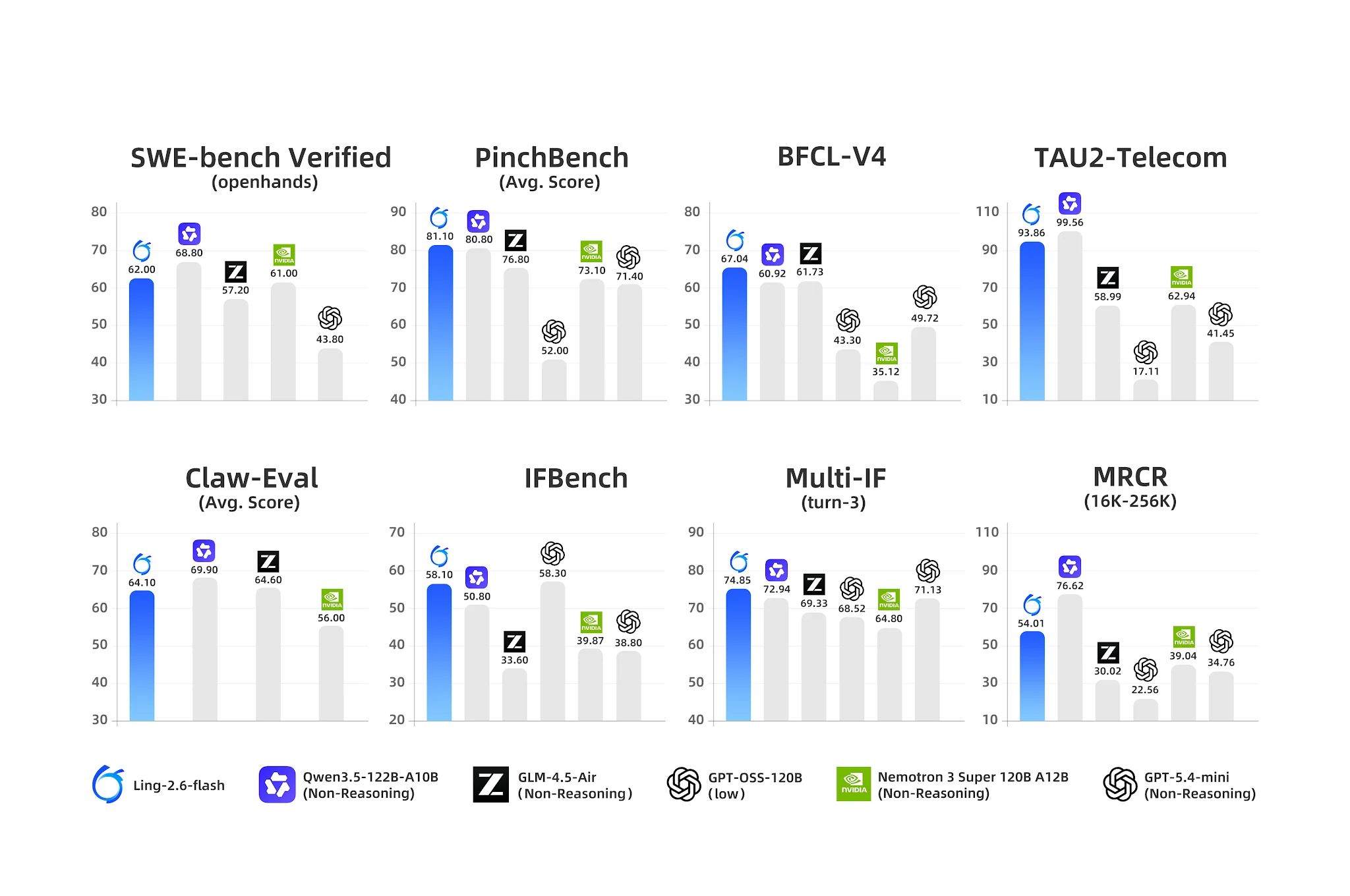
Agent benchmarks: Ling-2.6-flash leads on tool-use and multi-turn IF [Source: Ling Official Blog]
Where Ling-2.6-flash Leads
- BFCL-V4 (Function Calling): 67.04 — nearest competitor Nemotron at 35.12 (90% gap)
- PinchBench (Agent Tasks): 81.10 vs. Nemotron 73.10
- IFBench (Instruction Following): 58.10
- Multi-IF Turn-3: 74.85 — strong multi-turn instruction persistence
- LongBench-v2: 54.80 — top in long-context category
- CCAlignBench (Chinese): 7.44 — best among all tested models
Where Others Lead
- Math (AIME 2025, MATH-500): Nemotron-3-Super and Qwen3 reasoning variants win
- Coding (LiveCodeBench): Qwen3.5-122B-A10B leads; Ling is competitive but not top
- GPQA-Diamond: GLM-4.5-Air and Nemotron score higher
Quick Comparison Table
| Model | Active Params | BFCL-V4 ↑ | PinchBench ↑ | Decode TP @ 65K ↑ | Output Tokens ↓ |
|---|---|---|---|---|---|
| Ling-2.6-flash | 7.4B | 67.04 | 81.10 | 4.38× | ~15M |
| Nemotron-3-Super | 49B total | 35.12 | 73.10 | 3.37× | ~110M+ |
| Qwen3.5-122B-A10B | 10B | — | 78.20 | 1.90× | — |
| GLM-4.5-Air | — | 50.67 | 73.30 | 1.00× (baseline) | — |
| MiniMax-M1-80k | — | 44.07 | 75.70 | — | — |
| Qwen3-57B-A14B | 14B | 52.32 | 76.30 | — | — |
Access Ling-2.6-flash backed by Novita AI
Ling-2.6-flash is available now. Try it on OpenRouter — free tier, no setup required:
Get started on OpenRouter — inclusionai/ling-2.6-flash:free. Free tier available, no code changes needed for OpenAI-compatible clients.
Ling-2.6-flash works with LangChain, LlamaIndex, and OpenAI Agent SDK — no adapter or code change needed. Streaming, function calling, and structured outputs are all supported. Pair it with Novita Agent Sandbox for secure code execution alongside inference.
What the Community Is Saying
Ling-2.6-flash launched on OpenRouter as “Elephant Alpha” before the official reveal. Within days it had processed ~100B tokens and topped the platform trending leaderboard — without any announcement.
“Ling-2.6-flash is kind of work-oriented. About 75% less verbose than big models. Still a bit of boilerplate, but when it comes to writing code — it’s almost perfect.”
— Early user on X/Twitter
“Just tried Ling-2.6-flash on a few llama.cpp coding tasks. Much better than expected. Handles tool calls reliably and doesn’t pad the output with unnecessary explanation.”
— Early user on Reddit
The “75% less verbose” comment matches the 15M vs. 110M token gap on Artificial Analysis benchmarks exactly. The training objective appears to reward direct, complete answers — a property that compounds in cost savings at production scale.
Who Should Use Ling-2.6-flash?
- ✅ High-volume function calling / tool-use agents — BFCL-V4 leadership by a wide margin
- ✅ Multi-turn agent sessions — consistent across long conversation histories
- ✅ Long context RAG pipelines — 256K token window, linear-cost prefill
- ✅ Cost-sensitive production deployments — ~7× fewer output tokens than Nemotron
- ✅ Chinese-language applications — top CCAlignBench
- ❌ Math competition / AIME-style reasoning — use Nemotron or Qwen3 reasoning variants
- ❌ Maximum coding benchmark performance — Qwen3.5-122B-A10B leads
Get Started
Ling-2.6-flash is available now. Access it via the OpenRouter model page — free tier available immediately, no code changes needed for OpenAI-compatible clients. The Agent Sandbox is available alongside for teams combining inference and secure execution.
Frequently Asked Questions
What is Ling-2.6-flash?
Ling-2.6-flash is a 104B MoE model (7.4B active) with hybrid linear attention, 256K context window, and up to 340 tokens/s inference speed — optimized for agent workloads.
How do I use Ling-2.6-flash via API?
Use OpenRouter with your Novita AI API key (BYOK). Add your Novita key at openrouter.ai/settings/integrations, select Novita as the provider, and route requests to inclusionai/ling-2.6-flash:free via the OpenAI-compatible endpoint:
POST https://openrouter.ai/api/v1/chat/completions
Authorization: Bearer YOUR_OPENROUTER_API_KEY
{
"model": "inclusionai/ling-2.6-flash:free",
"provider": {
"order": ["Novita"],
"api_key": "YOUR_NOVITA_API_KEY"
},
"messages": [{"role": "user", "content": "Hello!"}]
}See OpenRouter BYOK docs for full setup. When using BYOK, OpenRouter charges no fees — you pay Novita directly at free-tier pricing.
How does Ling-2.6-flash compare to Nemotron-3-Super?
Ling leads on BFCL-V4 (67.04 vs 35.12), PinchBench (81.10 vs 73.10), and uses ~7× fewer output tokens. Nemotron leads on math. For agent workloads, Ling-2.6-flash is the better economic choice.
What is the context window?
256K tokens (262,144), with linear-cost prefill thanks to hybrid linear attention. Long RAG and multi-turn sessions scale efficiently.
Is Ling-2.6-flash open source?
BF16, FP8, and INT4 variants plus Linghe kernels are planned for open-source release. Timeline TBD — check the Ling official site for updates.
You Might Also Like
- Kimi K2.6: Open-Source Agent for 13-Hour Coding Sessions — 1T MoE model with 256K context and 58.6% SWE-Bench Pro
- GLM-5.1 API on Novita AI: Long-Horizon Agentic Model — tops SWE-Bench Pro at 58.4, runs autonomous coding tasks for 8 hours
- Top Inference API Providers for Open-Source Models in 2026 — compare Novita AI, Together AI, Fireworks, DeepInfra, and Groq



