

- What Is Kimi K2.6?
- What Makes Kimi K2.6 Different from Other Open-Source Models?
- How Does Kimi K2.6 Perform on Agentic Coding Benchmarks?
- How to Use Kimi K2.6 on Novita AI
- When Should You Use Kimi K2.6 Instead of GPT-4o or Claude?
- How Much Does Kimi K2.6 Cost on Novita AI?
- What Are the Technical Specs of Kimi K2.6?
- Is Kimi K2.6 the Right Model for Your Agent Pipeline?
- FAQ
Kimi K2.6: Open-Source Agent for 13-Hour Coding Sessions
Your coding agent halts after 20 minutes, burns through context, and leaves you with a half-finished PR. You switch to a closed frontier model — it lasts longer but costs 5× more per run. Kimi K2.6, Moonshot AI’s newly open-sourced model, is built specifically to break that trade-off. Across 4,000+ tool calls and 13-hour autonomous sessions, it delivered 58.6% on SWE-Bench Pro — edging out GPT-5.4 (57.7%) and outperforming Claude Opus 4.6 (53.4%) — at a fraction of the closed-model price. (Benchmarks sourced from kimi.com/blog/kimi-k2-6.)
Kimi K2.6 is now available on Novita AI via OpenAI-compatible API.
In short: Kimi K2.6 is a 1-trillion-parameter open-source MoE model (32B activated) from Moonshot AI, specialized for agentic coding, long-horizon task execution, and multi-agent coordination — with a 256K context window and OpenAI-compatible API access on Novita AI.
What Is Kimi K2.6?
Kimi K2.6 is an open-source, native multimodal agentic model released by Moonshot AI in April 2026. It is a direct evolution of Kimi K2.5 — the same MoE architecture, now significantly improved for real-world long-horizon tasks, coding-driven UI generation, and coordinated multi-agent execution.
At its core, K2.6 is a 1-trillion-parameter Mixture-of-Experts (MoE) model with only 32B parameters activated per token — giving it frontier-class reasoning at compute costs closer to a dense 30B model. The architecture uses Multi-head Latent Attention (MLA), SwiGLU activations, 384 experts with 8 selected per token, and a 256K-token context window. The model is released under a modified MIT license.
Key capabilities at a glance:
- Long-horizon coding — sustained autonomous execution across hours and thousands of tool calls
- Multi-language generalization — strong performance in Rust, Go, Python, and niche languages like Zig
- Coding-driven design — turns prompts and visual inputs into production-ready front-end interfaces
- Agent Swarm scaling — coordinates up to 300 sub-agents across 4,000 parallel steps
- Native multimodal — processes images and text natively via the MoonViT vision encoder
- Function calling & structured output — OpenAI-compatible tool use, ideal for building agent pipelines and RAG systems
What Makes Kimi K2.6 Different from Other Open-Source Models?
Long-Horizon Coding
Most LLMs degrade after a few hundred tool calls. K2.6 was explicitly trained for multi-hour, multi-thousand-call sessions. In one benchmark task, it deployed a local Qwen3.5-0.8B model on a Mac, rewrote its inference engine in Zig over 12 hours and 4,000+ tool calls, and improved throughput from ~15 to ~193 tokens/sec — roughly 20% faster than LM Studio. In another, it autonomously refactored an 8-year-old financial matching engine (exchange-core) across a 13-hour session, executing 12 optimization strategies and modifying 4,000+ lines of code for a 185% throughput gain.

Kimi Code Bench: K2.6 scores 68.2 vs K2.5’s 57.4 (+19%). [Source: Kimi Official Blog]
According to Moonshot AI’s launch blog, beta partners including Baseten, Blackbox.ai, Factory.ai, and Fireworks.ai noted that K2.6 maintains “architectural integrity over extended coding sessions” and surfaces “non-obvious bugs that would normally take significant developer time to uncover.”
Coding-Driven Design
K2.6 can generate structured front-end layouts, interactive elements, scroll-triggered animations, and lightweight full-stack workflows — authentication, session management, database operations — from a simple text or image prompt. Moonshot AI’s internal Kimi Design Bench, covering Visual Input Tasks, Landing Page Construction, Full-Stack App Development, and General Creative Programming, shows K2.6 competitive with Google AI Studio across all four categories.
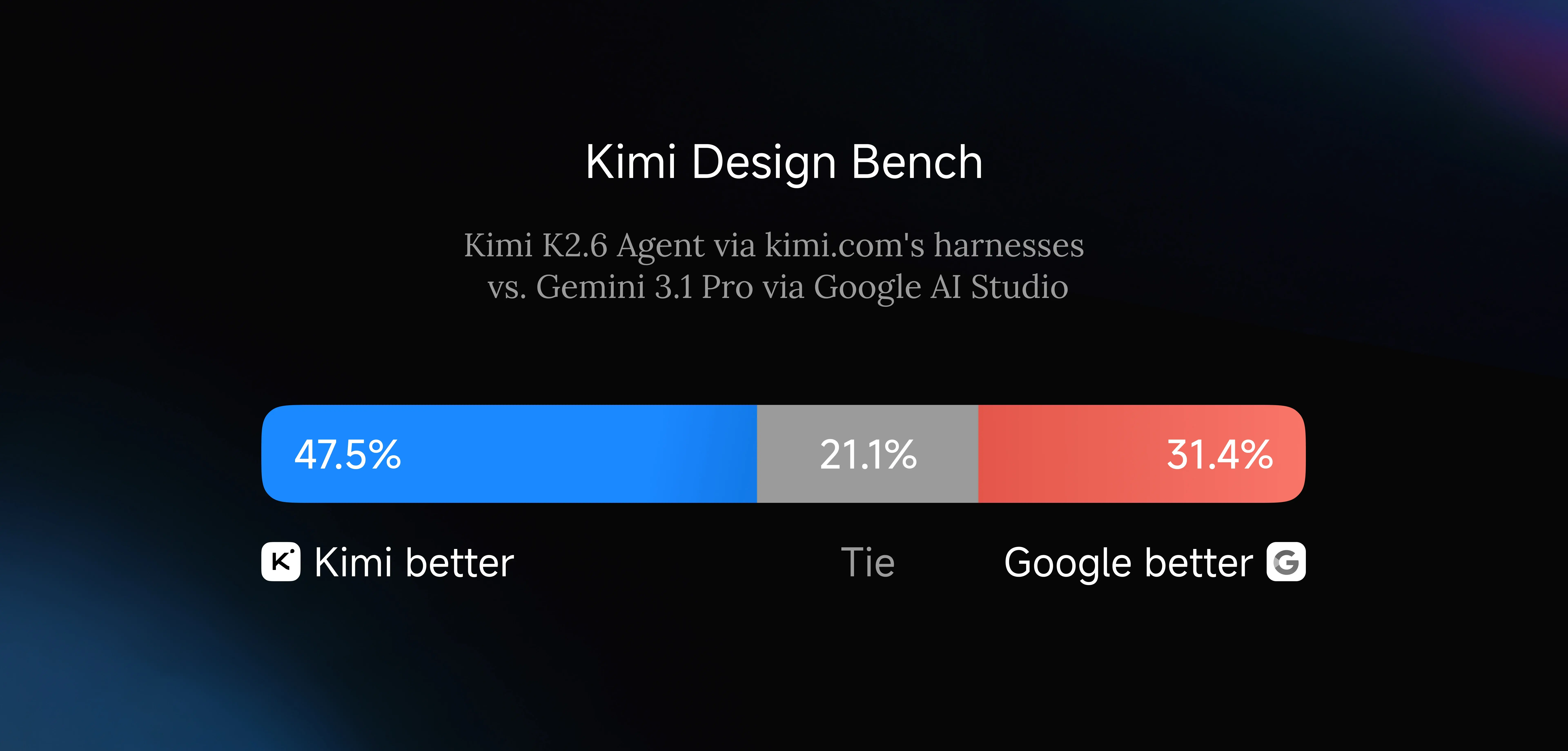
Kimi Design Bench: K2.6 (47.5%) outperforms Google AI Studio (31.4%) on UI generation tasks. [Source: Kimi Official Blog]
Elevated Agent Swarm
K2.6 scales the agent swarm architecture from K2.5’s 100 sub-agents / 1,500 steps to 300 sub-agents executing across 4,000 coordinated steps simultaneously. The coordinator dynamically assigns tasks to agents based on skill profiles, detects failures, reassigns work, and manages the full lifecycle from initiation to validation. Outputs span documents, websites, slides, and spreadsheets — produced in a single autonomous run. Moonshot AI’s own marketing team uses a K2.6-backed Claw Group internally, with specialized agents for demo creation, benchmarking, social media, and video production all coordinated by K2.6.

Kimi Claw Bench: K2.6 scores 65.5 vs K2.5’s 59.6 (+9.9%) on multi-step agent tasks. [Source: Kimi Official Blog]
Proactive Background Agents
One of the more striking K2.6 use cases from Moonshot’s own RL infrastructure team: a K2.6-backed agent ran autonomously for 5 days, handling monitoring, incident response, and system operations — persistent context, multi-threaded task management, and full-cycle execution from alert to resolution, without human intervention. This kind of persistent, 24/7 background agent is a specific design target for K2.6.
How Does Kimi K2.6 Perform on Agentic Coding Benchmarks?
K2.6 competes directly with top closed models. It leads on the benchmarks most relevant to agentic coding workflows:
Coding Benchmarks (Last verified: 2026-04-21, source: kimi.com/blog/kimi-k2-6)
| Benchmark | Kimi K2.6 | GPT-5.4 (xhigh) | Claude Opus 4.6 (max) | Gemini 3.1 Pro (thinking) | Kimi K2.5 |
|---|---|---|---|---|---|
| SWE-Bench Pro | 58.6 | 57.7 | 53.4 | 54.2 | 50.7 |
| SWE-Bench Verified | 80.2 | — | 80.8 | 80.6 | 76.8 |
| SWE-Bench Multilingual | 76.7 | — | 77.8 | 76.9 | 73.0 |
| Terminal-Bench 2.0 | 66.7 | 65.4 | 65.4 | 68.5 | 50.8 |
| LiveCodeBench (v6) | 89.6 | — | 88.8 | 91.7 | 85.0 |
Agentic Benchmarks (Last verified: 2026-04-21)
| Benchmark | Kimi K2.6 | GPT-5.4 (xhigh) | Claude Opus 4.6 (max) | Gemini 3.1 Pro | Kimi K2.5 |
|---|---|---|---|---|---|
| HLE-Full w/ tools | 54.0 | 52.1 | 53.0 | 51.4 | 50.2 |
| DeepSearchQA (f1-score) | 92.5 | 78.6 | 91.3 | 81.9 | 89.0 |
| BrowseComp | 83.2 | 82.7 | 83.7 | 85.9 | 74.9 |
| OSWorld-Verified | 73.1 | 75.0 | 72.7 | — | 63.3 |
| Toolathlon | 50.0 | 54.6 | 47.2 | 48.8 | 27.8 |
The headline: K2.6 leads all models on SWE-Bench Pro (58.6%) and outperforms GPT-5.4 and Claude Opus 4.6 on Terminal-Bench 2.0 and DeepSearchQA by a notable margin. Gemini 3.1 Pro edges it on Terminal-Bench (68.5 vs. 66.7) and LiveCodeBench. Its reasoning scores (AIME 2026: 96.4%, GPQA-Diamond: 90.5%) are competitive but trail Gemini and GPT-5.4 — this is a coding-first model, not a math olympiad specialist.
How to Use Kimi K2.6 on Novita AI
Option 1: Playground
Navigate to Kimi K2.6 on Novita AI and click Try in Playground. No API key needed to start.
Option 2: API (Python)
Kimi K2.6 is fully OpenAI-compatible. Swap in the Novita base URL and your API key:
pip install openaifrom openai import OpenAI
client = OpenAI(
api_key="YOUR_NOVITA_API_KEY",
base_url="https://api.novita.ai/v3/openai",
)
response = client.chat.completions.create(
model="moonshotai/kimi-k2.6",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Your prompt here"}
],
max_tokens=8192,
temperature=0.7,
)
print(response.choices[0].message.content)Get your API key at novita.ai/settings.
Option 3: Third-Party Tools
Because Novita’s API is OpenAI-compatible, Kimi K2.6 works out of the box with LangChain, LlamaIndex, OpenWebUI, and coding assistants like Cursor or Continue. Point the base URL to https://api.novita.ai/v3/openai and set the model name to moonshotai/kimi-k2.6.
When Should You Use Kimi K2.6 Instead of GPT-4o or Claude?
Scenario 1: Long-Running Engineering Agents
K2.6 is well-suited for long-running engineering agents — legacy codebase refactoring, CI/CD pipeline debugging, and infrastructure optimization. Its Kimi Code Bench results and the exchange-core case study show it maintains task coherence across thousands of tool calls without drifting from the original objective.
Scenario 2: Design-to-Code Pipelines
Designers drop a mockup; K2.6 produces a working React/HTML/CSS implementation with animations and responsive layouts. The model’s native multimodal input (via MoonViT) means it processes the image reference directly rather than relying on a verbal description. This makes it a strong backbone for AI-assisted UI generation workflows.
Scenario 3: Multi-Agent Orchestration
When you need to coordinate specialized agents in parallel — one scraping data, another writing analysis, a third formatting output — K2.6 acts as the coordinator layer. Its 300-agent / 4,000-step architecture makes it a practical choice for content pipelines, research workflows, or any task where parallel specialization reduces latency compared to sequential single-agent runs.
Scenario 4: Migrating from Claude or GPT-4o Agent Pipelines
If you’re running agentic coding workflows on Claude Opus or GPT-4o and looking to cut costs without sacrificing reliability, K2.6 is a strong open-source drop-in. Its SWE-Bench Pro score (58.6%) exceeds both Claude Opus 4.6 (53.4%) and GPT-5.4 (57.7%) on the same benchmark. The OpenAI-compatible API means migration is a one-line change.
How Much Does Kimi K2.6 Cost on Novita AI?
Kimi K2.6 on Novita AI is priced as follows (Last verified: 2026-04-21):
| Model | Input ($/M tokens) | Cache Read ($/M tokens) | Output ($/M tokens) | Context |
|---|---|---|---|---|
| Kimi K2.6 | $0.95 | $0.16 | $4.00 | 262K |
| Kimi K2.5 | $0.60 | $0.10 | $3.00 | 262K |
For long-horizon agentic runs where cache hit rates are high, the $0.16/M cache-read price makes extended autonomous sessions materially cheaper than the headline input price suggests.
What Are the Technical Specs of Kimi K2.6?
| Property | Value |
|---|---|
| Architecture | Mixture-of-Experts (MoE) |
| Total Parameters | 1T |
| Activated Parameters | 32B |
| Number of Layers | 61 (incl. 1 dense layer) |
| Number of Experts | 384 |
| Selected Experts per Token | 8 |
| Context Length | 256K tokens |
| Attention Mechanism | MLA (Multi-head Latent Attention) |
| Vision Encoder | MoonViT |
| Vocabulary Size | 160K |
| License | Modified MIT |
Full architecture details, weights, and evaluation code available on the Kimi K2.6 HuggingFace model card. Benchmark methodology published on the Moonshot AI blog.
Is Kimi K2.6 the Right Model for Your Agent Pipeline?
Bottom line: Kimi K2.6 is one of the strongest open-source models for long-horizon agentic coding as of April 2026. Its SWE-Bench Pro score of 58.6% outperforms several closed-source models on these benchmarks, its 256K context and MoE architecture keep inference costs reasonable, making it a compelling alternative to Claude or GPT-4o for agent pipeline developers.
It is not the top reasoning model overall — GPT-5.4 and Gemini 3.1 Pro lead on pure math (AIME, HLE without tools). But for developers building coding agents, design-to-code pipelines, or multi-agent orchestration systems, K2.6 is a strong open-source option available on the Novita AI API today.
Recommended Reading
- How to Access Kimi K2.5: Web, API, Claude Code, Self-Host
- Top 8 AI Inference Platforms in 2026
- Qwen3 Coder vs DeepSeek V3.1: Choosing the Right LLM for Your Program
FAQ
What is Kimi K2.6?
Kimi K2.6 is an open-source, native multimodal agentic model from Moonshot AI, released in April 2026. It is a 1-trillion-parameter Mixture-of-Experts model (32B activated) with a 256K context window, built for long-horizon coding, autonomous agent execution, and multi-agent swarm coordination.
How do I access Kimi K2.6 via API on Novita AI?
Use the OpenAI Python SDK with base_url="https://api.novita.ai/v3/openai" and model ID moonshotai/kimi-k2.6. Get your API key at novita.ai/settings. No special SDK or wrapper required.
How does Kimi K2.6 compare to Claude Opus 4.6 for coding tasks?
On SWE-Bench Pro, Kimi K2.6 scores 58.6% vs. Claude Opus 4.6’s 53.4% — a 5-point gap on real-world software engineering tasks. K2.6 also beats Claude on DeepSearchQA (92.5% vs. 91.3%) and Terminal-Bench 2.0 (66.7% vs. 65.4%); Gemini 3.1 Pro tops Terminal-Bench at 68.5%. For pure reasoning benchmarks like AIME or HLE without tools, Claude Opus 4.6 holds a slight edge.
What is the context window for Kimi K2.6?
Kimi K2.6 supports a 256K-token context window (262,144 tokens). On Novita AI, both the context length and max output are set to 262,144 tokens, making it suitable for long-document analysis and sustained multi-turn agentic sessions.
What is the pricing for Kimi K2.6 on Novita AI?
On Novita AI, Kimi K2.6 is priced at $0.95 per million input tokens, $0.16 per million cache-read tokens, and $4.00 per million output tokens. The 256K context window and max output are both included. View current pricing on Novita AI.
Novita AI is an AI & Agent Cloud for developers — offering 200+ models via serverless API alongside Agent Sandbox infrastructure and GPU Cloud. Build, scale, and deploy AI applications without managing infrastructure. Get started at novita.ai.



