

Points clés
Convient à ces modèles ✅
LLMs : Qwen 2.5 7B, Qwen 3 (0.6B–8B), Llama 3.1 8B, Llama 3.2 1B
Modèles vidéo : HunyuanVideo (544×960), Wan T2V-1.3B, T2V-14B
Défis et solutions de déploiement
Problèmes de chaleur, d’alimentation et de taille ? Nous couvrons les spécifications d’alimentation, le dimensionnement du châssis, les environnements Docker et des alternatives cloud économiques.
Évitez les coûts matériels avec Novita AI
Lancez des instances L40S dans le cloud. Payez à l’heure. Évoluez instantanément. Pas besoin de construire votre propre machine.

Novita AI

Runpod
Le coût d’utilisation de L40S sur Novita AI est environ la moitié du prix de RunPod.
Lancez votre instance GPU L40S maintenant
Vous pensez que votre modèle est trop volumineux pour un seul GPU ? Détrompez-vous. Le NVIDIA L40S pourrait vous surprendre. Avec 48 Go de VRAM et des Tensor Cores de 4e génération, il peut gérer plus que ce que vous imaginiez—y compris des modèles comme Qwen 3 8B, Llama 3.1 8B, et même T2V 14B.
Dans ce guide, nous détaillons exactement quels LLM et modèles vidéo tiennent sur un seul L40S—afin que vous puissiez arrêter de deviner et commencer à construire.
Pourquoi le L40S se démarque : une plongée approfondie dans le matériel
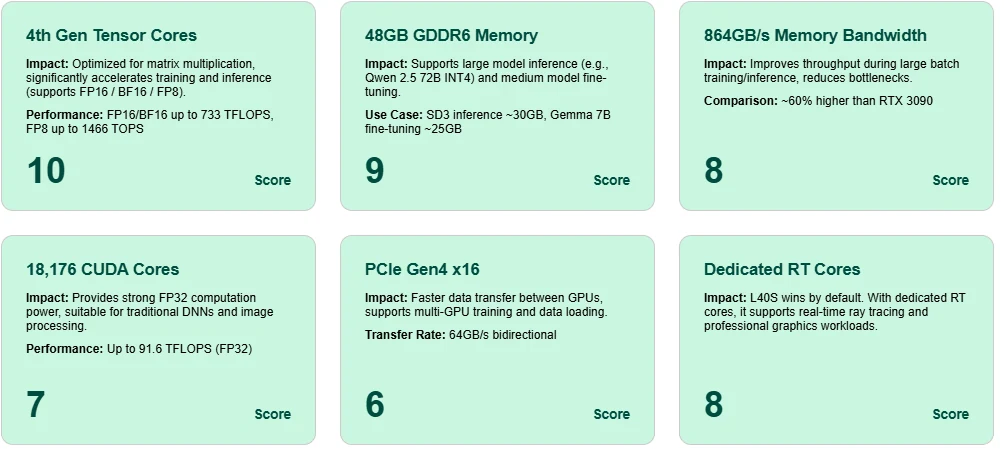
Excellence des Tensor Cores
Équipé de Tensor Cores de 4e génération, le L40S atteint jusqu’à 1466 TOPS avec FP8 et 733 TFLOPS avec BF16/FP16, permettant un entraînement et une inférence très efficaces pour les modèles d’IA modernes.
Mémoire GDDR6 massive de 48 Go
Prend en charge l’inférence de modèles à grande échelle comme Qwen 2.5 72B (INT4) et le fine-tuning de modèles de taille moyenne comme Gemma 7B—le tout sur une seule carte.
Bande passante mémoire élevée
Une bande passante de 864 Go/s assure un déplacement rapide des activations et des paramètres pendant l’entraînement, réduisant la latence et les goulots d’étranglement dans les scénarios de grands lots.
Versatilité des cœurs CUDA
Avec 18 176 cœurs CUDA et 91,6 TFLOPS FP32, le L40S offre une puissance de calcul fiable pour l’apprentissage profond conventionnel et le traitement d’image.
Débit PCIe Gen4 x16
Permet une communication à haute vitesse entre les GPU, essentielle pour les déploiements multi-GPU en entraînement ou inférence.
Cœurs RT dédiés pour le ray tracing
Le L40S n’est pas seulement pour l’IA—il excelle également dans les tâches graphiques et de rendu en temps réel, grâce à ses cœurs RT intégrés.
Quels modèles LLM peuvent être exécutés sur un seul GPU L40S ?
| Modèle | Paramètres | Poids FP16 (est.) | Verdict sur une carte |
|---|---|---|---|
| Qwen 2.5 7B | 7 B | ~14 GB | ✅ Convient |
| Qwen 3 8B / 4B / 1.7B / 0.6B | ≤ 8 B | ≤ 18 GB | ✅ Convient |
| Llama 3.1 8B | 8 B | ~18 GB | ✅ Convient |
| Llama 3.2 1B | 1 B | ~2 GB | ✅ Convient |
| Gemma 3 27B | 27 B | ~54 GB | ❌ Trop volumineux |
| GLM-4-32B | 32 B | ~64 GB | ❌ Trop volumineux |
| QWQ 32B | 32 B | ~65 GB | ❌ Trop volumineux |
| Qwen 3 30B A3B | 30 B total | ~61 GB* | ❌ Trop volumineux |
| Llama 3.3 70B | 70 B | ~140 GB | ❌ Trop volumineux |
| Qwen 2.5-VL 72B | 72 B | ~144 GB | ❌ Trop volumineux |
| Llama 4 Scout / Maverick | 109 B / 400 B | ~218 GB / ~800 GB | ❌ Trop volumineux |
| DeepSeek R1 / V3** | 671 B total | ~1.34 TB* | ❌ Beaucoup trop volumineux |
| Qwen 3 235B A22B | 235 B total | ~470 GB* | ❌ Trop volumineux |
Quels modèles vidéo peuvent être exécutés sur un GPU L40S ?
| Modèle / Résolution | L40 S sur une carte (48 Go) |
|---|---|
| HunyuanVideo 544 × 960 | ✅ Tient sur une carte |
| HunyuanVideo 720 × 1280 | ❌ Nécessite ≥ 2 cartes liées par NVLink |
| Wan T2V-1.3B | ✅ Beaucoup de marge |
| Wan T2V-14B | ✅ Tient sur une carte |
Quels obstacles lors du déploiement d’un GPU NVIDIA L40S ?
Obstacle : Une consommation électrique élevée (350 à 400 W) peut surcharger les alimentations de bureau classiques.
Solution : Installez une alimentation ATX 3.0 / 80 Plus Gold (≥ 1000 W) incluant un connecteur natif 12VHPWR ou des adaptateurs double 8 broches.
Obstacle : Une production de chaleur importante sature rapidement les petits boîtiers.
Solution : Choisissez un châssis spacieux avec flux d’air ou un rack 4U, ajoutez des ventilateurs à haut régime ou un watercooling AIO de 240 mm+.
Obstacle : La longueur et la hauteur de trois emplacements dépassent les dégagements de nombreuses tours moyennes.
Solution : Mesurez d’abord ; si c’est serré, passez à un banc d’essai ouvert, un support GPU vertical ou un châssis de station de travail.
Obstacle : Les piles logicielles doivent cibler CUDA 12+, cuDNN 9 et des noyaux récents.
Solution : Isolez avec des environnements Conda ou des images Docker épinglées sur des versions pilote/CUDA correspondantes ; testez les builds en CI avant l’installation sur l’hôte.
Obstacle : Le coût matériel initial est élevé pour les développeurs individuels.
Solution : Prototypez sur des nœuds L40S cloud à l’heure (par exemple, Novita AI) et n’achetez localement qu’après avoir dimensionné la charge de travail.
Une alternative plus économique : Novita AI
Novita AI fournit une plateforme cloud avec des instances GPU haute performance. Avec des GPU puissants, elle garantit des performances efficaces pour les tâches complexes, améliore l’accessibilité pour le déploiement sur divers matériels et offre une solution économique par rapport à la maintenance de matériel local pour les déploiements d’IA à grande échelle.
Étape 1 : Créer un compte
Créez votre compte Novita AI sur notre site web. Après inscription, accédez à la section « Explorer » dans la barre latérale gauche pour voir nos offres GPU et commencer votre parcours de développement IA.

Étape 2 : Explorer les modèles et serveurs GPU
Choisissez parmi des modèles comme PyTorch, TensorFlow ou CUDA qui correspondent aux besoins de votre projet. Sélectionnez ensuite votre configuration GPU préférée—les options incluent le puissant L40S, RTX 4090 ou A100 SXM4, chacun avec différentes spécifications de VRAM, RAM et stockage.

Étape 3 : Personnaliser votre déploiement
Personnalisez votre environnement en sélectionnant votre système d’exploitation préféré et les options de configuration pour garantir des performances optimales pour vos charges de travail IA spécifiques et vos besoins de développement.

Étape 4 : Lancer une instance
Sélectionnez « Lancer une instance » pour démarrer votre déploiement. Votre environnement GPU haute performance sera prêt en quelques minutes, vous permettant de commencer immédiatement vos projets de machine learning, rendu ou calcul.
Le NVIDIA L40S se distingue comme un GPU bien équilibré, offrant des performances tensor puissantes, une grande capacité mémoire et une large compatibilité avec les modèles—le tout sur une seule carte. Bien qu’il ne puisse pas exécuter des modèles massifs comme Qwen 2.5 72B ou DeepSeek V3, c’est un excellent choix pour les LLM de milieu de gamme et les tâches vidéo en temps réel. Avec l’accès cloud de Novita AI au L40S, les développeurs peuvent exploiter ces performances sans les coûts matériels initiaux, rendant le développement IA plus rapide, évolutif et abordable.
Questions fréquemment posées
Quels modèles LLM peuvent fonctionner sur un seul L40S ?
Qwen 2.5 7B
Qwen 3 8B / 4B / 1.7B / 0.6B
Llama 3.1 8B
Llama 3.2 1B
Quels modèles vidéo sont pris en charge ?
HunyuanVideo (544×960)
Wan T2V-1.3B
Wan T2V-14B
Quels sont les défis lors du déploiement local du L40S ?
Coût → Utilisez des fournisseurs cloud comme Novita AI pour prototyper à moindre coût
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API facile, tout en fournissant un cloud GPU abordable et fiable pour construire et passer à l’échelle.
Lectures recommandées



