

- Qu'est-ce que la mise en cache des prompts ?
- Comment la mise en cache des prompts réduit-elle la latence et le coût de calcul ?
- Mise en cache des prompts sur Novita AI
- Comment utiliser la mise en cache des prompts plus efficacement ?
- Quels risques devez-vous surveiller concernant la mise en cache des prompts ?
De nombreux développeurs et entreprises sont confrontés à une latence élevée et des coûts en tokens lorsqu’ils utilisent des grands modèles de langue (LLM) de manière répétée sur des prompts similaires. Chaque requête oblige le modèle à retraiter les mêmes instructions ou documents, gaspillant des ressources de calcul et du temps.
Cet article explique comment la mise en cache des prompts résout ce problème en stockant les préfixes de prompts pré-calculés pour les réutiliser entre plusieurs requêtes. Il clarifie la différence entre le cache de prompts et le cache KV, montre comment des systèmes comme Novita AI implémentent une mise en cache efficace et fournit des conseils pratiques pour structurer les prompts, surveiller les performances du cache et éviter les abus ou les risques de sécurité.
Qu’est-ce que la mise en cache des prompts ?
La mise en cache des prompts consiste à stocker des parties pré-calculées d’un prompt (par exemple, des instructions système, un contexte ou des documents répétés) afin que lorsque vous réutilisez le même prompt ou un prompt similaire, le modèle évite de recalculer l’ensemble depuis le début.
For prompt cache to hit successfully, the following token sequences must be identical:
System: [system_instructions] # Fixed prefix, reusable
Document: [retrieved_context] # Changes will break cache reuse
User: [query] # Changes will break cache reuse
| Étape | Description |
|---|---|
| 1. Soumission du prompt | Une requête avec un prompt long ou répété est envoyée au modèle. |
| 2. Encodage et mise en cache | Le système encode le préfixe du prompt dans des embeddings internes ou des états cachés, puis les stocke dans un cache. |
| 3. Vérification du cache | Lorsqu’une requête ultérieure inclut le même préfixe, le système détecte une correspondance et charge la représentation mise en cache. |
| 4. Réutilisation et continuation | Le modèle saute le retraitement de ce préfixe et poursuit la génération à partir de l’état mis en cache. |
| 5. Expiration | Les entrées du cache expirent après une durée de vie (TTL) définie (par exemple, 5 minutes d’inactivité sur Amazon Bedrock). La TTL est réinitialisée à chaque réutilisation). |
https://www.youtube.com/watch?v=RDjaUJz-uWo
Quelle est la différence entre le cache de prompts et le cache KV ?
| Aspect | Cache KV | Cache de prompts |
|---|---|---|
| Portée | Au sein d’une seule génération ou session | Entre plusieurs requêtes ou sessions |
| Objectif | Évite de recalculer l’attention pour les tokens précédents | Évite de retraiter les préfixes de prompts répétés |
| Données stockées | Clés et valeurs d’attention du transformateur | Préfixes de prompts encodés ou modules |
| Avantage | Réduit la latence par token | Réduit le coût des tokens d’entrée et le temps de traitement complet du prompt |
| Utilisation typique | Décodage autorégressif (ex. génération de LLM) | Réutilisation de prompts courants dans des applications ou des API |
Comment la mise en cache des prompts réduit-elle la latence et le coût de calcul ?
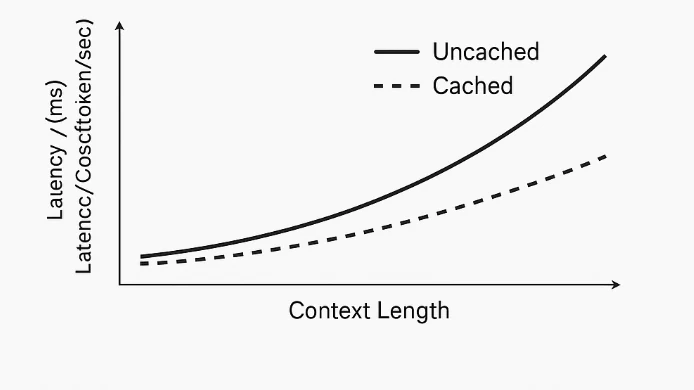
La mise en cache des prompts fonctionne au niveau du système, et non à l’intérieur du modèle. Le modèle lui-même traite tous les tokens de manière égale et ne distingue pas le « prompt » du « contenu de référence ». Lorsqu’un préfixe de tokens répété est détecté, le système met en cache ses représentations calculées, telles que les embeddings et les états du transformateur. Lors de requêtes ultérieures avec le même préfixe, le modèle saute le recalcul de cette partie et ne traite que les nouveaux tokens. Cela réduit les calculs redondants, abaisse la latence et diminue les coûts liés aux tokens.
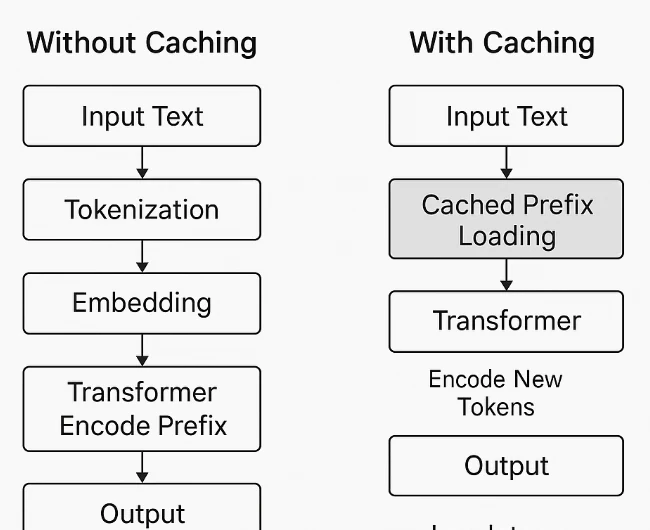
Mise en cache des prompts sur Novita AI
Novita AI a élargi sa gamme de modèles pour inclure la prise en charge du cache de prompts sur plusieurs modèles à contexte élevé, permettant aux développeurs de réduire considérablement les coûts et d’améliorer la latence pour des tâches longues ou répétées. La mise en cache des prompts stocke les prompts ou embeddings précédemment utilisés afin que les appels API ultérieurs référençant le même contenu puissent être traités à un taux de lecture de cache beaucoup plus bas.
Cette fonctionnalité est idéale pour les conversations multi-tours, les systèmes de génération augmentée par récupération (RAG) ou les pipelines de workflow qui réutilisent de grands prompts système. En exploitant les lectures en cache, les équipes peuvent obtenir des réponses plus rapides et des coûts plus bas tout en maintenant la précision du modèle et l’intégrité du contexte.
Modèles pris en charge et tarification
| Modèle | Fenêtre de contexte | Prix d’entrée (par 1M de tokens) | Lecture de cache (par 1M de tokens) | Prix de sortie (par 1M de tokens) |
|---|---|---|---|---|
| deepseek/deepseek-v3-0324 | 163 840 | 0,27 $ / Mt | 0,135 $ / Mt | 1,12 $ / Mt |
| deepseek/deepseek-r1-0528 | 163 840 | 0,70 $ / Mt | 0,35 $ / Mt | 2,50 $ / Mt |
| zai-org/glm-4.6 | 204 800 | 0,60 $ / Mt | 0,11 $ / Mt | 2,20 $ / Mt |
| zai-org/glm-4.5 | 131 072 | 0,60 $ / Mt | 0,11 $ / Mt | 2,20 $ / Mt |
| zai-org/glm-4.5v | 65 536 | 0,60 $ / Mt | 0,11 $ / Mt | 1,80 $ / Mt |
💡 Pourquoi c’est important
Avec des longueurs de contexte allant jusqu’à 204k tokens, ces modèles peuvent traiter des entrées extrêmement longues telles que des documents entiers, des transcriptions ou des bases de code. L’ajout de la mise en cache des prompts garantit que les utilisateurs peuvent réutiliser des prompts volumineux sans payer le coût d’entrée complet à chaque fois, réduisant ainsi les dépenses totales et améliorant le temps de réponse pour les requêtes répétées.
Les développeurs peuvent désormais créer des applications IA évolutives, peu coûteuses et riches en contexte directement sur l’infrastructure de Novita AI.
Comment utiliser la mise en cache des prompts plus efficacement ?
Comment structurer les prompts pour augmenter le taux de succès du cache ?
- Séparez le préfixe statique (instructions, documents, modèles) de la requête variable.
- Conservez le texte du préfixe identique entre toutes les requêtes.
- Définissez clairement les limites des points de contrôle du cache.
- Utilisez des modèles modulaires comme « System : [rôle]… Document : [contexte]… User : [requête] ».
Quelle est la durée de validité du cache ? La mise en œuvre et l’expiration varient selon le fournisseur, la charge de travail et la configuration. Certains systèmes font expirer les caches après quelques minutes ou quelques heures ; d’autres les conservent jusqu’à ce que les limites de mémoire soient atteintes.
Si vous modifiez légèrement le prompt, le cache sera-t-il toujours utilisé ? Aucune garantie. Les succès de cache dépendent d’une correspondance exacte du préfixe ou d’une réutilisation structurelle. Même de petites différences de texte ou de formatage peuvent entraîner un échec.
Peut-on mettre en cache du contenu dynamique ? Seule la partie statique d’un prompt peut être mise en cache efficacement. Les éléments dynamiques tels que les données utilisateur, les horodatages ou les valeurs en temps réel doivent rester en dehors du préfixe mis en cache.
Différentes versions de modèle peuvent-elles réutiliser le même cache ? Généralement non. Les caches sont liés à des architectures de modèle, des tokenizers et des espaces d’embedding spécifiques. La mise à niveau ou le changement de modèle invalide généralement les anciens caches.
Qu’en est-il des textes longs ou des scénarios de RAG (génération augmentée par récupération) ? La mise en cache des prompts fonctionne le mieux lorsqu’un document statique volumineux ou un préfixe est répété, comme dans les questions-réponses basées sur des documents. Dans le RAG, où le contexte récupéré change à chaque requête, seule une partie du préfixe peut être réutilisée, donc les taux de succès du cache sont plus faibles.
Quels risques devez-vous surveiller concernant la mise en cache des prompts ?
Succès de cache obsolètes ou erronés Les préfixes mis en cache peuvent devenir obsolètes si le contexte change, par exemple lorsque des documents sont mis à jour. Des erreurs de limites ou un contenu dynamique non correspondant peuvent entraîner une dérive sémantique.
Risques de confidentialité et de sécurité Les caches KV ou de prompts partagés dans des systèmes multi-tenants peuvent fuir des données entre utilisateurs. L’attaque « PROMPTPEEK » a démontré la reconstruction de prompts via des canaux latéraux de cache partagé. N’incluez pas de données dynamiques ou spécifiques à l’utilisateur dans les préfixes de cache partagés.
Surveillance de l’efficacité Suivez les taux de succès et d’échec, le nombre de tokens lus depuis le cache par rapport au nombre total de tokens, la réduction de la latence et les économies de coûts.
Éviter les abus
- Ne mettez en cache que du contenu statique.
- Invalidez les caches lorsque les données sources changent.
- Isolez les caches par utilisateur ou par tenant pour préserver la confidentialité.
Perspectives futures
- Améliorer l’identification des caches et prendre en charge la correspondance sémantique des préfixes.
- Construire des systèmes de cache unifiés et sécurisés entre les modèles et les sessions.
- Utiliser la compression et le déchargement sur GPU, CPU et disque.
La mise en cache des prompts réduit les calculs redondants, abaisse la latence et diminue les coûts en tokens en réutilisant des embeddings de préfixe identiques entre les requêtes. Son efficacité dépend d’une structure de prompt stable, d’une séparation soigneuse du contenu statique et dynamique, et d’une gestion responsable du cache. Des fournisseurs comme Novita AI démontrent comment une mise en cache peu coûteuse et stable peut améliorer l’efficacité globale tout en maintenant la sécurité et la précision.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API intuitive, tout en fournissant un cloud GPU abordable et fiable pour construire et mettre à l’échelle des projets.



