

Muchos desarrolladores y empresas enfrentan alta latencia y costos de tokens al usar modelos de lenguaje grandes repetidamente con prompts similares. Cada solicitud obliga al modelo a reprocesar las mismas instrucciones o documentos, desperdiciando cómputo y tiempo.
Este artículo explica cómo el Caché de Prompts soluciona ese problema almacenando prefijos de prompts precomputados para reutilizarlos entre solicitudes. Aclara la diferencia entre Caché de Prompts y Caché KV, muestra cómo sistemas como Novita AI implementan un almacenamiento en caché eficiente y ofrece orientación práctica sobre cómo estructurar los prompts, monitorear el rendimiento del caché y evitar malos usos o riesgos de seguridad.
¿Qué es el Caché de Prompts?
El caché de prompts se refiere al almacenamiento de partes precomputadas de un prompt (por ejemplo, instrucciones del sistema, contexto repetido o documentos) para que al reutilizar el mismo prompt o uno similar, el modelo evite recomputar desde cero.
Para que el caché de prompts funcione correctamente, las siguientes secuencias de tokens deben ser idénticas:
System: [system_instructions] # Prefijo fijo, reutilizable
Document: [retrieved_context] # Los cambios rompen la reutilización del caché
User: [query] # Los cambios rompen la reutilización del caché
| Paso | Descripción |
|---|---|
| 1. Envío del prompt | Se envía una solicitud al modelo con un prompt largo o repetido. |
| 2. Codificación y almacenamiento | El sistema codifica el prefijo del prompt en embeddings internos o estados ocultos y luego los almacena en un caché. |
| 3. Verificación de acierto de caché | Cuando una solicitud posterior incluye el mismo prefijo, el sistema detecta una coincidencia y carga la representación almacenada. |
| 4. Reutilización y continuación | El modelo omite reprocesar ese prefijo y continúa la generación desde el estado almacenado. |
| 5. Caducidad | Las entradas almacenadas caducan después de un TTL definido (por ejemplo, 5 minutos de inactividad en Amazon Bedrock). El TTL se reinicia en cada reutilización. |
https://www.youtube.com/watch?v=RDjaUJz-uWo
¿En qué se diferencia el Caché de Prompts del Caché KV?
| Aspecto | Caché KV | Caché de Prompts |
|---|---|---|
| Alcance | Dentro de una sola generación o sesión | Entre múltiples solicitudes o sesiones |
| Propósito | Evita recomputar la atención para tokens anteriores | Evita reprocesar prefijos de prompts repetidos |
| Datos Almacenados | Claves y valores de atención del Transformer | Prefijos de prompts o módulos codificados |
| Beneficio | Reduce la latencia por token | Reduce el costo de tokens de entrada y el tiempo de procesamiento completo del prompt |
| Uso Típico | Decodificación autoregresiva (ej. generación con LLM) | Reutilización de prompts comunes en aplicaciones o APIs |
¿Cómo Reduce la Latencia y el Costo de Cómputo el Caché de Prompts?
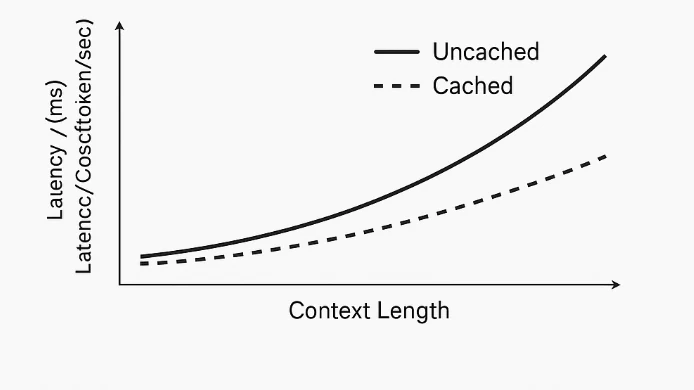
El caché de prompts funciona a nivel del sistema, no dentro del modelo. El modelo procesa todos los tokens por igual y no distingue entre “prompt” y “contenido de referencia”. Cuando se detecta un prefijo repetido de tokens, el sistema almacena en caché sus representaciones computadas —como embeddings y estados del transformer. En solicitudes posteriores con el mismo prefijo, el modelo omite recomputar esa parte y solo procesa los nuevos tokens. Esto reduce el cómputo redundante, disminuye la latencia y reduce los costos relacionados con los tokens.
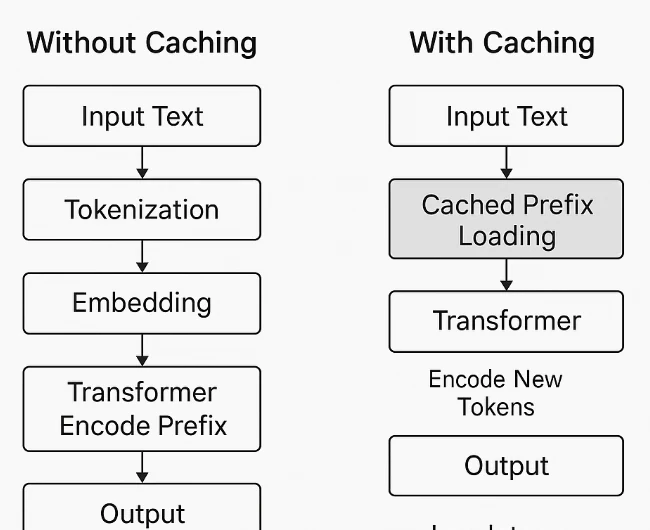
Caché de Prompts en Novita AI
Novita AI ha ampliado su línea de modelos para incluir soporte de Caché de Prompts en varios modelos de alto contexto, permitiendo a los desarrolladores reducir significativamente costos y mejorar la latencia en tareas largas o repetitivas. El caché de prompts almacena prompts o embeddings utilizados previamente, de modo que las llamadas API posteriores que hagan referencia al mismo contenido se puedan procesar a una tasa de Lectura de Caché mucho más baja.
Esta función es ideal para conversaciones de múltiples turnos, sistemas de generación aumentada por recuperación (RAG) o pipelines de trabajo que reutilizan prompts grandes del sistema. Al aprovechar las lecturas almacenadas en caché, los equipos pueden lograr respuestas más rápidas y menores costos, manteniendo la precisión del modelo y la integridad del contexto.
Modelos Soportados y Precios
| Modelo | Ventana de Contexto | Precio de Entrada (por 1M tokens) | Lectura de Caché (por 1M tokens) | Precio de Salida (por 1M tokens) |
|---|---|---|---|---|
| deepseek/deepseek-v3-0324 | 163,840 | $0.27 / Mt | $0.135 / Mt | $1.12 / Mt |
| deepseek/deepseek-r1-0528 | 163,840 | $0.70 / Mt | $0.35 / Mt | $2.50 / Mt |
| zai-org/glm-4.6 | 204,800 | $0.60 / Mt | $0.11 / Mt | $2.20 / Mt |
| zai-org/glm-4.5 | 131,072 | $0.60 / Mt | $0.11 / Mt | $2.20 / Mt |
| zai-org/glm-4.5v | 65,536 | $0.60 / Mt | $0.11 / Mt | $1.80 / Mt |
💡 Por Qué es Importante
Con longitudes de contexto de hasta 204k tokens, estos modelos pueden manejar entradas extremadamente largas, como documentos completos, transcripciones o bases de código. La adición del caché de prompts garantiza que los usuarios puedan reutilizar prompts pesados sin pagar el costo total de entrada cada vez, reduciendo el gasto total y mejorando el tiempo de respuesta en consultas repetidas.
Los desarrolladores ahora pueden construir aplicaciones de IA escalables, rentables y ricas en contexto directamente sobre la infraestructura de Novita AI.
¿Cómo Puedes Usar el Caché de Prompts de Manera Más Efectiva?
¿Cómo se debe estructurar el prompt para aumentar la tasa de aciertos?
Separa el prefijo estático (instrucciones, documentos, plantillas) de la consulta variable.
Mantén el texto del prefijo idéntico entre solicitudes.
Define los límites de los puntos de control del caché claramente.
Usa plantillas modulares como “System: [rol]… Document: [contexto]… User: [consulta].”
¿Cuánto tiempo hasta que expire el caché?
La implementación y la caducidad varían según el proveedor, la carga de trabajo y la configuración. Algunos sistemas hacen expirar los cachés después de minutos u horas; otros los mantienen hasta que se alcanzan los límites de memoria.
Si cambias el prompt ligeramente, ¿seguirás obteniendo aciertos de caché?
No hay garantía. Los aciertos de caché dependen de la coincidencia exacta del prefijo o la reutilización estructural. Incluso pequeñas diferencias en el texto o el formato pueden provocar fallos.
¿Se puede almacenar contenido dinámico en caché?
Solo la parte estática de un prompt se puede almacenar en caché de manera efectiva. Los elementos dinámicos como datos de usuario, marcas de tiempo o valores en tiempo real deben permanecer fuera del prefijo almacenado.
¿Pueden diferentes versiones del modelo reutilizar el mismo caché?
Generalmente no. Los cachés están vinculados a arquitecturas de modelo, tokenizadores y espacios de embedding específicos. Actualizar o cambiar de modelo normalmente invalida los cachés antiguos.
¿Qué pasa con textos largos o escenarios de RAG (generación aumentada por recuperación)?
El caché de prompts funciona mejor cuando un documento estático grande o un prefijo se repite, como en preguntas y respuestas basadas en documentos. En RAG, donde el contexto recuperado cambia por consulta, solo una parte del prefijo se puede reutilizar, por lo que las tasas de aciertos de caché son más bajas.
¿Qué Riesgos Debes Tener en Cuenta con el Caché de Prompts?
Aciertos Desactualizados o Incorrectos
Los prefijos almacenados pueden volverse obsoletos si el contexto cambia, por ejemplo cuando los documentos se actualizan.
Los errores de límite o el contenido dinámico no coincidente pueden provocar desviaciones semánticas.
Riesgos de Privacidad y Seguridad
Los cachés KV o de prompts compartidos en sistemas multiinquilino pueden filtrar datos entre usuarios.
El ataque “PROMPTPEEK” demostró la reconstrucción de prompts a través de canales laterales de caché compartidos.
No incluyas datos dinámicos o específicos del usuario en prefijos de caché compartidos.
Monitoreo de la Efectividad
Rastrea las tasas de aciertos y fallos, los tokens leídos desde el caché frente al total de tokens, la reducción de latencia y el ahorro de costos.
Evitando el Mal Uso
Almacena en caché solo contenido estático.
Invalida los cachés cuando los datos fuente cambien.
Aísla los cachés por usuario o inquilino para mantener la privacidad.
Direcciones Futuras
Mejorar la identificación del caché y admitir la coincidencia semántica de prefijos.
Construir sistemas de caché unificados y seguros entre modelos y sesiones.
Usar compresión y descarga entre GPU, CPU y disco.
El caché de prompts reduce el cómputo redundante, disminuye la latencia y reduce los costos de tokens al reutilizar embeddings de prefijos idénticos entre solicitudes. Su efectividad depende de una estructura de prompt estable, una separación cuidadosa del contenido estático y dinámico, y una gestión responsable del caché. Proveedores como Novita AI demuestran cómo un almacenamiento en caché de bajo costo y estable puede mejorar la eficiencia general, manteniendo la seguridad y la precisión.
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA usando nuestra API simple, además de proporcionar una nube de GPU asequible y confiable para construir y escalar.



