

多くの開発者や企業は、大規模言語モデルを類似したプロンプトで繰り返し使用する際に、高レイテンシとトークンコストに悩まされています。リクエストのたびにモデルが同じ指示やドキュメントを再処理するため、計算リソースと時間が無駄になります。
本記事では、プロンプトキャッシングがどのようにこの問題を解決するかを解説します。事前に計算されたプロンプトの先頭部分を保存し、複数のリクエスト間で再利用することで、レイテンシとトークンコストを削減します。プロンプトキャッシュとKVキャッシュの違いを明確にし、Novita AI のようなシステムが効率的なキャッシングを実装する方法を示します。さらに、プロンプトの構造化、キャッシュパフォーマンスの監視、誤用やセキュリティリスクの回避に関する実践的なガイダンスも提供します。
プロンプトキャッシングとは?
プロンプトキャッシングとは、プロンプトの事前に計算された部分(たとえば、システム指示、繰り返されるコンテキストやドキュメント)を保存しておくことです。同じまたは類似したプロンプトを再利用する際に、モデルがゼロから再計算するのを回避できます。
プロンプトキャッシュが正常にヒットするには、次のトークンシーケンスが同一である必要があります:
System: [system_instructions] # 固定の先頭部分、再利用可能
Document: [retrieved_context] # 変更があるとキャッシュ再利用が失敗
User: [query] # 変更があるとキャッシュ再利用が失敗
| ステップ | 説明 |
|---|---|
| 1. プロンプト送信 | 長いまたは繰り返しのプロンプトを含むリクエストがモデルに送信されます。 |
| 2. エンコードとキャッシュ | システムがプロンプトの先頭部分を内部の埋め込みや隠れ状態にエンコードし、キャッシュに保存します。 |
| 3. キャッシュヒット確認 | 後のリクエストで同じ先頭部分が含まれている場合、システムは一致を検出し、キャッシュされた表現をロードします。 |
| 4. 再利用と継続 | モデルはその先頭部分の再処理をスキップし、キャッシュされた状態から生成を続行します。 |
| 5. 有効期限 | キャッシュエントリは定義された TTL(例:Amazon Bedrock では非アクティブ状態が5分)後に期限切れとなります。再利用のたびに TTL はリセットされます。 |
https://www.youtube.com/watch?v=RDjaUJz-uWo
プロンプトキャッシュと KV キャッシュの違いは?
| 側面 | KV キャッシュ | プロンプトキャッシュ |
|---|---|---|
| 範囲 | 単一の生成またはセッション内 | 複数のリクエストまたはセッション間 |
| 目的 | 前のトークンのアテンション再計算を回避 | 繰り返されるプロンプト先頭部分の再処理を回避 |
| 保存データ | Transformer のアテンションキーとバリュー | エンコードされたプロンプト先頭部分またはモジュール |
| 利点 | トークンあたりのレイテンシ削減 | 入力トークンコストとプロンプト全体の処理時間削減 |
| 典型的な用途 | 自己回帰的デコード(例:LLM生成) | アプリケーションやAPIでの共通プロンプト再利用 |
プロンプトキャッシングはどのようにレイテンシと計算コストを削減するのか?
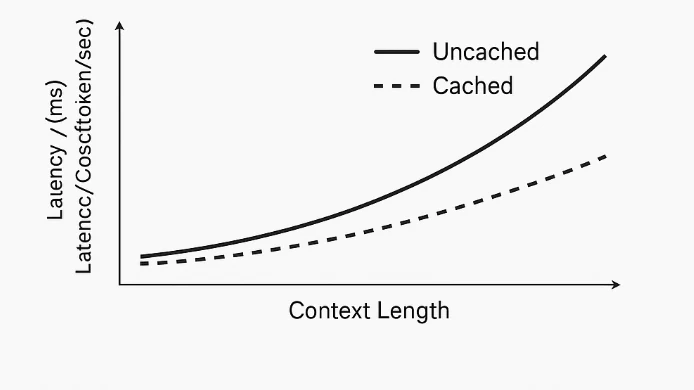
プロンプトキャッシングは、モデル内部ではなくシステムレベルで機能します。モデル自体はすべてのトークンを均等に処理し、「プロンプト」と「参照コンテンツ」を区別しません。トークンの繰り返される先頭部分が検出されると、システムはその計算済み表現(埋め込みやTransformer状態など)をキャッシュします。後続のリクエストで同じ先頭部分がある場合、モデルはその部分の再計算をスキップし、新しいトークンのみを処理します。これにより、冗長な計算が削減され、レイテンシが低下し、トークン関連のコストが減少します。
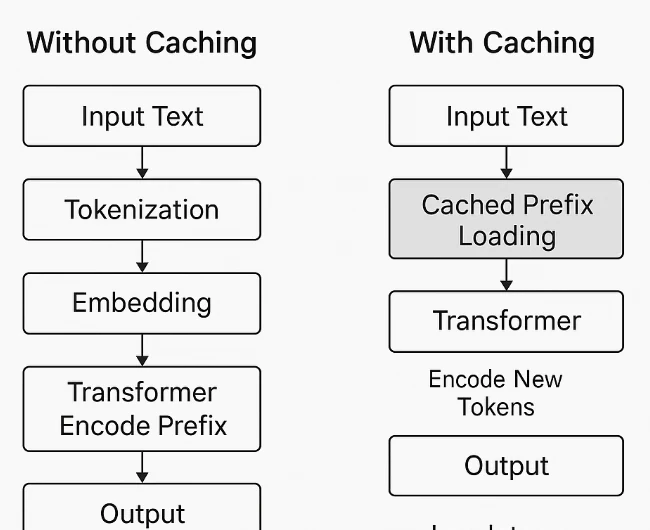
Novita AI におけるプロンプトキャッシング
Novita AI は、複数のハイコンテキストモデルにわたってプロンプトキャッシュサポートを拡充しました。これにより、開発者は長いタスクや繰り返しタスクにおいてコストを大幅に削減し、レイテンシを改善できます。プロンプトキャッシングは、以前に使用したプロンプトや埋め込みを保存するため、同じコンテンツを参照する後続のAPI呼び出しを、はるかに低いキャッシュ読み取りレートで処理できます。
この機能は、マルチターンの会話、検索拡張生成(RAG)システム、または大規模なシステムプロンプトを再利用するワークフローパイプラインに最適です。キャッシュ読み取りを活用することで、モデルの精度とコンテキストの整合性を維持しながら、より高速な応答と低コストを実現できます。
サポートされるモデルと料金
| モデル | コンテキストウィンドウ | 入力価格(1Mトークンあたり) | キャッシュ読み取り(1Mトークンあたり) | 出力価格(1Mトークンあたり) |
|---|---|---|---|---|
| deepseek/deepseek-v3-0324 | 163,840 | $0.27 / Mt | $0.135 / Mt | $1.12 / Mt |
| deepseek/deepseek-r1-0528 | 163,840 | $0.70 / Mt | $0.35 / Mt | $2.50 / Mt |
| zai-org/glm-4.6 | 204,800 | $0.60 / Mt | $0.11 / Mt | $2.20 / Mt |
| zai-org/glm-4.5 | 131,072 | $0.60 / Mt | $0.11 / Mt | $2.20 / Mt |
| zai-org/glm-4.5v | 65,536 | $0.60 / Mt | $0.11 / Mt | $1.80 / Mt |
💡 なぜこれが重要なのか
最大204kトークンものコンテキスト長により、これらのモデルは文書全体、トランスクリプト、コードベースなどの非常に長い入力も処理できます。プロンプトキャッシングを追加することで、ユーザーは毎回全額の入力コストを支払うことなく、重いプロンプトを再利用できるようになります。これにより、繰り返しのクエリに対しても総支出が削減され、応答時間が向上します。
開発者は、Novita AI のインフラ上で、スケーラブルでコスト効率が高く、コンテキスト豊富なAIアプリケーションを直接構築できるようになりました。
プロンプトキャッシングをより効果的に使用するには?
ヒット率を上げるためには、どのようにプロンプト構造を記述すべきですか?
静的プレフィックス(指示、ドキュメント、テンプレート)と可変クエリを分けてください。 プレフィックスのテキストはリクエスト間で同一に保ってください。 キャッシュのチェックポイント境界を明確に定義してください。 「System: [role]… Document: [context]… User: [query]」のようなモジュラーテンプレートを使用してください。
キャッシュの有効期限はどのくらいですか?
実装と有効期限はプロバイダー、ワークロード、設定によって異なります。一部のシステムではキャッシュを数分または数時間で期限切れにし、他のシステムではメモリ制限に達するまで保持します。
プロンプトを少し変更してもキャッシュはヒットしますか?
保証はありません。キャッシュヒットは完全なプレフィックス一致または構造的な再利用に依存します。小さなテキストやフォーマットの違いでもミスが発生する可能性があります。
動的コンテンツはキャッシュできますか?
プロンプトの静的部分のみ効果的にキャッシュできます。ユーザーデータ、タイムスタンプ、リアルタイム値などの動的要素は、キャッシュされたプレフィックスの外側に置く必要があります。
異なるモデルバージョンで同じキャッシュを再利用できますか?
通常はできません。キャッシュは特定のモデルアーキテクチャ、トークナイザー、埋め込み空間に結びついています。モデルのアップグレードや切り替えは、通常、古いキャッシュを無効にします。
長いテキストやRAG(検索拡張生成)のシナリオではどうですか?
プロンプトキャッシングは、ドキュメントベースのQ&Aのように、大きな静的ドキュメントやプレフィックスが繰り返される場合に最も効果的です。RAGでは、取得されるコンテキストがクエリごとに変わるため、プレフィックスの一部のみ再利用可能で、キャッシュヒット率は低くなります。
プロンプトキャッシングに関して注意すべきリスクは?
古いデータや誤ったヒット ドキュメントが更新された場合など、コンテキストが変更されると、キャッシュされたプレフィックスが古くなる可能性があります。 境界エラーや動的コンテンツの不一致は、意味のずれを引き起こす可能性があります。
プライバシーとセキュリティのリスク マルチテナントシステムで共有されたKVキャッシュやプロンプトキャッシュは、ユーザー間でデータを漏洩させる可能性があります。 「PROMPTPEEK」攻撃は、共有キャッシュのサイドチャネルを介したプロンプト再構築を示しました。 動的データやユーザー固有のデータを共有キャッシュプレフィックスに含めないでください。
効果の監視 ヒット率とミス率、キャッシュから読み取られたトークンと総トークンの割合、レイテンシ削減、コスト削減を追跡してください。
誤用の回避 静的コンテンツのみをキャッシュしてください。 ソースデータが変更された場合はキャッシュを無効にしてください。 プライバシーを維持するために、ユーザーまたはテナントごとにキャッシュを分離してください。
今後の方向性 キャッシュ識別を強化し、意味的なプレフィックス一致をサポートします。 モデルやセッションをまたいだ、統一された安全なキャッシュシステムを構築します。 GPU、CPU、ディスクにわたる圧縮とオフロードを活用します。
プロンプトキャッシングは、要求間で同一のプレフィックス埋め込みを再利用することにより、冗長な計算を削減し、レイテンシを低下させ、トークンコストを削減します。その効果は、安定したプロンプト構造、静的コンテンツと動的コンテンツの注意深い分離、責任あるキャッシュ管理に依存します。Novita AI のようなプロバイダーは、低コストで安定したキャッシングが、セキュリティと精度を維持しながら全体の効率をどのように向上させるかを示しています。
Novita AI は、開発者がシンプルなAPIを使用してAIモデルを簡単にデプロイできるAIクラウドプラットフォームであり、同時に手頃で信頼性の高いGPUクラウドを構築とスケーリングのために提供しています。



