

Muitos desenvolvedores e empresas enfrentam problemas com alta latência e custos de tokens ao usar modelos de linguagem grandes repetidamente com prompts semelhantes. Cada solicitação força o modelo a reprocessar as mesmas instruções ou documentos, desperdiçando computação e tempo.
Este artigo explica como o Cache de Prompts resolve esse problema armazenando prefixos de prompts pré-computados para reutilização em várias solicitações. Ele esclarece a diferença entre Cache de Prompts e KV Cache, mostra como sistemas como a Novita AI implementam cache eficiente e fornece orientações práticas sobre como estruturar prompts, monitorar o desempenho do cache e evitar uso indevido ou riscos de segurança.
O que é o Cache de Prompts?
O cache de prompts refere-se ao armazenamento de partes pré-computadas de um prompt (por exemplo, instruções do sistema, contexto repetido ou documentos) para que, quando você reutilizar o mesmo ou um prompt semelhante, o modelo evite recomputar tudo do zero.
For prompt cache to hit successfully, the following token sequences must be identical:
System: [system_instructions] # Fixed prefix, reusable
Document: [retrieved_context] # Changes will break cache reuse
User: [query] # Changes will break cache reuse
| Etapa | Descrição |
|---|---|
| 1. Envio de prompt | Uma solicitação com um prompt longo ou repetido é enviada para o modelo. |
| 2. Codificação e armazenamento em cache | O sistema codifica o prefixo do prompt em embeddings internos ou estados ocultos, depois os armazena em um cache. |
| 3. Verificação de acerto no cache | Quando uma solicitação posterior inclui o mesmo prefixo, o sistema detecta uma correspondência e carrega a representação armazenada no cache. |
| 4. Reutilização e continuação | O modelo pula o reprocessamento desse prefixo e continua a geração a partir do estado armazenado no cache. |
| 5. Expiração | As entradas do cache expiram após um TTL definido (por exemplo, 5 minutos de inatividade no Amazon Bedrock). O TTL é redefinido a cada reutilização). |
https://www.youtube.com/watch?v=RDjaUJz-uWo
Como o Cache de Prompts é Diferente do KV Cache?
| Aspecto | KV Cache | Cache de Prompts |
|---|---|---|
| Escopo | Dentro de uma única geração ou sessão | Em várias solicitações ou sessões |
| Finalidade | Evita a recomputação da atenção para tokens anteriores | Evita o reprocessamento de prefixos de prompt repetidos |
| Dados Armazenados | Chaves e valores de atenção do transformer | Prefixos de prompt codificados ou módulos |
| Benefício | Reduz a latência por token | Reduz o custo de tokens de entrada e o tempo total de processamento do prompt |
| Uso Típico | Decodificação autoregressiva (ex: geração de LLM) | Reutilização de prompts comuns em aplicativos ou APIs |
Como o Cache de Prompts Reduz a Latência e o Custo de Computação?
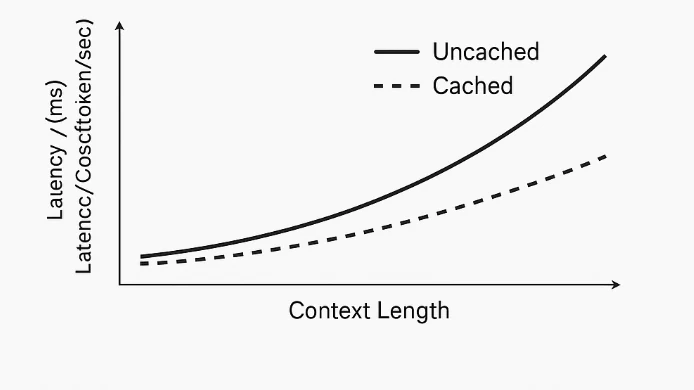
O cache de prompts funciona no nível do sistema, não dentro do modelo. O próprio modelo processa todos os tokens igualmente e não distingue entre “prompt” e “conteúdo de referência”. Quando um prefixo de tokens repetido é detectado, o sistema armazena em cache suas representações computadas — como embeddings e estados do transformer. Em solicitações subsequentes com o mesmo prefixo, o modelo pula a recomputação dessa parte e processa apenas os novos tokens. Isso reduz a computação redundante, diminui a latência e diminui os custos relacionados a tokens.
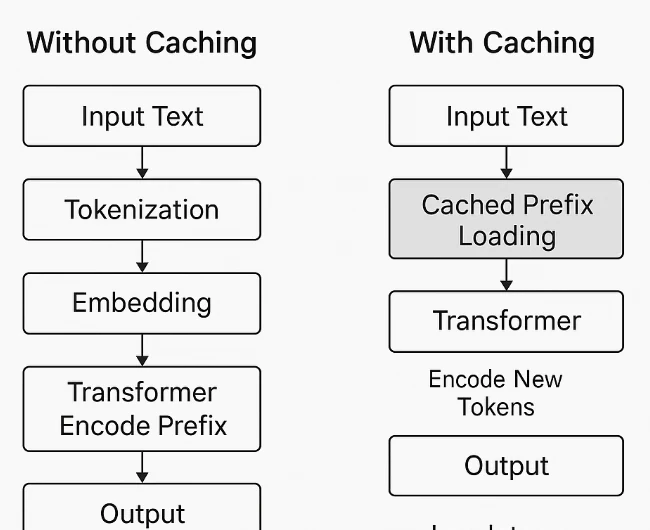
Cache de Prompts na Novita AI
A Novita AI expandiu sua linha de modelos para incluir suporte a Cache de Prompts em vários modelos de alto contexto, permitindo que desenvolvedores reduzam significativamente os custos e melhorem a latência para tarefas longas ou repetitivas. O cache de prompts armazena prompts ou embeddings usados anteriormente para que chamadas de API subsequentes que referenciem o mesmo conteúdo possam ser processadas com uma taxa de Leitura de Cache muito menor.
Esse recurso é ideal para conversas de múltiplas turnos, sistemas de geração aumentada por recuperação (RAG) ou pipelines de fluxo de trabalho que reutilizam grandes prompts de sistema. Ao aproveitar as leituras em cache, as equipes podem obter respostas mais rápidas e custos menores, mantendo a precisão do modelo e a integridade do contexto.
Modelos Suportados e Preços
| Modelo | Janela de Contexto | Preço de Entrada (por 1M de tokens) | Leitura de Cache (por 1M de tokens) | Preço de Saída (por 1M de tokens) |
|---|---|---|---|---|
| deepseek/deepseek-v3-0324 | 163,840 | $0.27 / Mt | $0.135 / Mt | $1.12 / Mt |
| deepseek/deepseek-r1-0528 | 163,840 | $0.70 / Mt | $0.35 / Mt | $2.50 / Mt |
| zai-org/glm-4.6 | 204,800 | $0.60 / Mt | $0.11 / Mt | $2.20 / Mt |
| zai-org/glm-4.5 | 131,072 | $0.60 / Mt | $0.11 / Mt | $2.20 / Mt |
| zai-org/glm-4.5v | 65,536 | $0.60 / Mt | $0.11 / Mt | $1.80 / Mt |
💡 Por Que Isso Importa?
Com comprimentos de contexto de até 204k tokens, esses modelos conseguem lidar com entradas extremamente longas, como documentos inteiros, transcrições ou bases de código. A adição do cache de prompts garante que os usuários possam reutilizar prompts pesados sem pagar os custos de entrada completos toda vez — reduzindo o gasto total e melhorando o tempo de resposta em consultas repetidas.
Os desenvolvedores agora podem construir aplicativos de IA escaláveis, econômicos e ricos em contexto diretamente na infraestrutura da Novita AI.
Como Você Pode Usar o Cache de Prompts de Forma Mais Eficaz?
Como a estrutura do prompt deve ser escrita para aumentar a taxa de acerto?
Separe o prefixo estático (instruções, documentos, modelos) da consulta variável.
Mantenha o texto do prefixo idêntico em todas as solicitações.
Defina claramente os limites de pontos de verificação do cache.
Use modelos modulares como “Sistema: [função]… Documento: [contexto]… Usuário: [consulta].”
Quanto tempo até que o cache expire? A implementação e a expiração variam de acordo com o provedor, a carga de trabalho e a configuração. Alguns sistemas expiram os caches após minutos ou horas; outros os mantêm até que os limites de memória sejam atingidos.
Se você alterar o prompt ligeiramente, ainda conseguirá acertar o cache? Não há garantia. Os acertos no cache dependem de correspondência exata de prefixos ou reutilização estrutural. Mesmo pequenas diferenças de texto ou formatação podem causar uma falha no acerto.
O conteúdo dinâmico pode ser armazenado em cache? Apenas a parte estática de um prompt pode ser armazenada em cache de forma eficaz. Elementos dinâmicos, como dados de usuário, carimbos de data/hora ou valores em tempo real, devem permanecer fora do prefixo armazenado em cache.
Diferentes versões de modelo podem reutilizar o mesmo cache? Geralmente não. Os caches estão vinculados a arquiteturas de modelo, tokenizadores e espaços de embedding específicos. Atualizar ou trocar de modelo geralmente invalida os caches antigos.
E sobre textos longos ou cenários de RAG (geração aumentada por recuperação)? O cache de prompts funciona melhor quando um documento grande ou prefixo estático se repete, como em perguntas e respostas baseadas em documentos. No RAG, onde o contexto recuperado muda por consulta, apenas parte do prefixo pode ser reutilizada, então as taxas de acerto no cache são menores.
Quais Riscos Você Deve Observar com o Cache de Prompts?
Acertos Desatualizados ou Incorretos
Os prefixos armazenados em cache podem ficar desatualizados se o contexto mudar, como quando documentos são atualizados.
Erros de limite ou conteúdo dinâmico incompatível podem levar a desvio semântico.
Riscos de Privacidade e Segurança
Caches KV ou de prompts compartilhados em sistemas multitenant podem vazar dados entre usuários.
O ataque “PROMPTPEEK” demonstrou a reconstrução de prompts por meio de canais laterais de cache compartilhado.
Não inclua dados dinâmicos ou específicos de usuário em prefixos de cache compartilhados.
Monitoramento de Eficácia
Acompanhe as taxas de acerto e falha, os tokens lidos do cache em comparação com o total de tokens, a redução de latência e a economia de custos.
Evitando Uso Indevido
Armazene em cache apenas conteúdo estático.
Invalide os caches quando os dados de origem mudarem.
Isole os caches por usuário ou tenant para manter a privacidade.
Direções Futuras
Aprimore a identificação de cache e suporte a correspondência semântica de prefixos.
Construa sistemas de cache unificados e seguros entre modelos e sessões.
Use compactação e offloading entre GPU, CPU e disco.
O cache de prompts reduz a computação redundante, diminui a latência e corta os custos de tokens reutilizando embeddings de prefixo idênticos em várias solicitações. Sua eficácia depende de uma estrutura de prompt estável, separação cuidadosa de conteúdo estático e dinâmico e gerenciamento responsável do cache. Provedores como a Novita AI demonstram como um cache de baixo custo e estável pode melhorar a eficiência geral, mantendo a segurança e a precisão.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construir e escalar.



