

许多开发者和企业在反复使用相似提示的大型语言模型时,面临着高延迟和令牌成本的问题。每次请求都会迫使模型重新处理相同的指令或文档,浪费计算资源和时间。
本文介绍 提示缓存 如何通过存储预计算的提示前缀供跨请求重用来解决这一问题。它阐明了提示缓存与 KV 缓存的区别,展示了像 Novita AI 这样的系统如何实现高效的缓存,并提供了关于如何构建提示、监控缓存性能以及避免误用或安全风险的实用指导。
什么是提示缓存?
提示缓存指的是存储提示中预先计算的部分(例如系统指令、重复的上下文或文档),以便当你重用相同或类似的提示时,模型避免从头开始重新计算。
为了使提示缓存成功命中,以下令牌序列必须完全相同:
System: [system_instructions] # 固定前缀,可重用
Document: [retrieved_context] # 改动会打破缓存重用
User: [query] # 改动会打破缓存重用
| 步骤 | 描述 |
|---|---|
| 1. 提交提示 | 向模型发送一个包含长提示或重复提示的请求。 |
| 2. 编码与缓存 | 系统将提示前缀编码为内部嵌入或隐藏状态,然后存储在缓存中。 |
| 3. 缓存命中检查 | 当后续请求包含相同前缀时,系统检测到匹配并加载缓存的表示。 |
| 4. 重用与继续 | 模型跳过对该前缀的重新处理,从缓存状态继续生成。 |
| 5. 过期 | 缓存条目在定义的 TTL 后过期(例如,Amazon Bedrock 上 5 分钟无活动)。每次重用时 TTL 重置。 |
https://www.youtube.com/watch?v=RDjaUJz-uWo
提示缓存与 KV 缓存有何不同?
| 方面 | KV 缓存 | 提示缓存 |
|---|---|---|
| 范围 | 仅在单个生成或会话内 | 跨多个请求或会话 |
| 目的 | 避免重新计算之前令牌的注意力 | 避免重新处理重复的提示前缀 |
| 存储数据 | Transformer 注意力机制的键和值 | 编码后的提示前缀或模块 |
| 优势 | 降低每个令牌的延迟 | 降低输入令牌成本和完整提示处理时间 |
| 典型用途 | 自回归解码(例如 LLM 生成) | 在应用程序或 API 中重用常见提示 |
提示缓存如何降低延迟和计算成本?
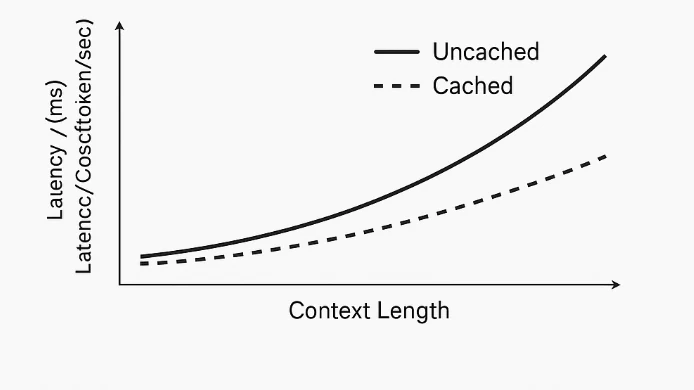
提示缓存在系统层面工作,而不是模型内部。模型本身平等处理所有令牌,并不区分“提示”和“参考内容”。当检测到重复的令牌前缀时,系统缓存其计算出来的表示——例如嵌入和 Transformer 状态。在后续具有相同前缀的请求中,模型跳过重新计算该部分,只处理新的令牌。这减少了冗余计算,降低了延迟,并减少了与令牌相关的成本。
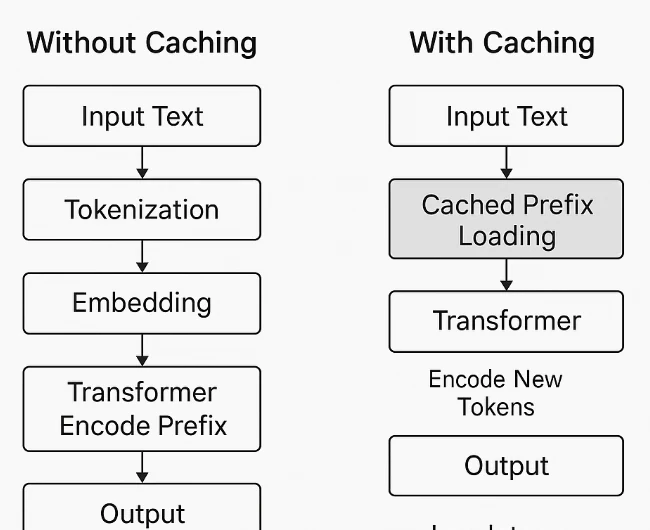
Novita AI 上的提示缓存
Novita AI 已扩展其模型阵容,在多个高上下文模型中支持提示缓存,使开发者能够显著降低长任务或重复任务的成本和延迟。提示缓存存储以前使用过的提示或嵌入,这样后续引用相同内容的 API 调用可以以低得多的缓存读取速率进行处理。
此功能非常适合多轮对话、检索增强生成(RAG)系统或重用大型系统提示的工作流管道。通过利用缓存读取,团队可以在保持模型准确性和上下文完整性的同时,实现更快的响应和更低的成本。
支持的模型和定价
| 模型 | 上下文窗口 | 输入价格(每百万令牌) | 缓存读取(每百万令牌) | 输出价格(每百万令牌) |
|---|---|---|---|---|
| deepseek/deepseek-v3-0324 | 163,840 | $0.27 / Mt | $0.135 / Mt | $1.12 / Mt |
| deepseek/deepseek-r1-0528 | 163,840 | $0.70 / Mt | $0.35 / Mt | $2.50 / Mt |
| zai-org/glm-4.6 | 204,800 | $0.60 / Mt | $0.11 / Mt | $2.20 / Mt |
| zai-org/glm-4.5 | 131,072 | $0.60 / Mt | $0.11 / Mt | $2.20 / Mt |
| zai-org/glm-4.5v | 65,536 | $0.60 / Mt | $0.11 / Mt | $1.80 / Mt |
💡 为什么这很重要
由于上下文长度可达 204k 令牌,这些模型可以处理极长的输入,例如整个文档、转录稿或代码库。提示缓存的加入确保用户可以重用大型提示,而无需每次都支付完整的输入成本——从而降低总支出,并改善重复查询的响应时间。
开发者现在可以直接在 Novita AI 的基础设施上构建可扩展、成本效益高且上下文丰富的 AI 应用程序。
如何更有效地使用提示缓存?
如何编写提示结构以提高命中率?
将静态前缀(指令、文档、模板)与变量查询分开。 保持前缀文本在不同请求中完全相同。 明确定义缓存检查点的边界。 使用模块化模板,例如“System: [角色]… Document: [上下文]… User: [查询]。”
缓存多久过期?
实现方式和过期时间因提供商、工作负载和配置而异。某些系统在几分钟或几小时后使缓存过期;其他系统则一直保留直到达到内存限制。
如果稍微修改提示,是否仍然能命中缓存?
无法保证。缓存命中依赖于精确的前缀匹配或结构重用。即使是微小的文本或格式差异也可能导致未命中。
动态内容可以缓存吗?
只有提示的静态部分可以有效缓存。动态元素(例如用户数据、时间戳或实时值)应保留在缓存前缀之外。
不同模型版本可以重用同一个缓存吗?
通常不行。缓存与特定的模型架构、分词器和嵌入空间绑定。升级或切换模型通常会使旧缓存失效。
长文本或 RAG(检索增强生成)场景怎么办?
当大型静态文档或前缀重复出现时(例如基于文档的问答),提示缓存效果最佳。在 RAG 中,由于每次查询检索的上下文都在变化,只有部分前缀可以被重用,因此缓存命中率较低。
提示缓存需要注意哪些风险?
过时或错误的命中
如果上下文发生变化,例如文档更新,缓存的前缀可能会过时。
边界错误或动态内容不匹配可能导致语义漂移。
隐私与安全风险
在多租户系统中,共享的 KV 或提示缓存可能导致用户之间的数据泄露。
“PROMPTPEEK”攻击已证明了通过共享缓存侧信道重建提示的可能性。
不要在共享的缓存前缀中包含动态或用户特定数据。
监控效果
跟踪命中率和未命中率、从缓存读取的令牌与总令牌的对比、延迟减少以及成本节省。
避免误用
仅缓存静态内容。
当源数据变更时使缓存失效。
按用户或租户隔离缓存以维护隐私。
未来方向
增强缓存识别并支持语义前缀匹配。
构建跨模型和会话的统一、安全的缓存系统。
使用压缩和卸载技术,在 GPU、CPU 和磁盘之间平衡。
提示缓存通过跨请求重用相同的前缀嵌入,减少冗余计算、降低延迟并削减令牌成本。其有效性取决于稳定的提示结构、静态和动态内容的仔细分离以及负责任的缓存管理。像 Novita AI 这样的提供商展示了低成本且稳定的缓存如何在保持安全性和准确性的同时提高整体效率。
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,同时也提供负担得起且可靠的 GPU 云用于构建和扩展。



