

为你的特定应用找到最优模型并将其投入生产是件难事。与 OpenAI 或 Claude 的闭源选项不同,开源模型很少被托管。你需要自己配置计算、延迟和吞吐量要求。这种复杂性导致许多开发者和公司默认选择熟悉的通用模型(如 GPT-4 或 Claude),即使开源替代方案(包括轻量级专家模型和强大的通用模型)能提供更好的性能、更快的响应和更低的成本。这正是 Novita 的用武之地。Novita 托管开源模型,并在必要时根据你的特定要求进行配置,让你无需费心即可使用这些模型。
为什么大家都在用 GPT-4?
AI 模型领域正在快速增长,包含数百个模型,每个模型都有其独特的优势和劣势。然而,尽管开源模型的性能不断提升,GPT-4x 系列、Claude 3x 系列以及其他闭源模型仍然是许多团队的默认选择。本文将分析何时该用闭源模型、何时不该用,以及 Novita 如何让部署开源 LLM 变得像使用闭源模型一样简单。
这些流行的闭源模型已经托管且易于使用,因此无需担心基础设施、设置或部署。只需调用 API 即可获得推理结果。这些模型也具有广泛的能力,在写作、推理和编程等通用任务上表现出色。而且由于它们被广泛采用,被视为低风险选项。
……但代价是什么?
默认使用闭源通用模型可能感觉是最安全的选择,但往往会导致隐性成本。完全依赖闭源模型可能会让你无法使用强大的开源替代方案,如 Qwen 和 DeepSeek,它们在提供更大控制权、透明度和长期成本效益的同时,还能提供相当或更好的结果。事实上,许多团队最终为并不需要的规模和功能支付了超额费用,将计算和能源浪费在不需要 100B+ 参数大模型的任务上,还会带来相应的环境后果。此外,在小而专的模型擅长的特定任务上,通用性能也可能表现不佳。
现在,许多开源模型在关键任务上已经达到或超越了顶级闭源模型:
- Kimi K2、DeepSeek R1 和 Qwen 3 235B A22B 在编程和数学推理任务上以更低成本超越了 GPT-4x 系列 (来源:Huggingface、GeeksforGeeks、Artificial Analysis)
- Qwen 2.5 7B Instruct 在 GPQA、HumanEval 和 MATH 基准测试中超越 GPT-4,而资源消耗仅为其一小部分 (来源:LLM Stats)
- Qwen3-Coder-480B-A35B-Instruct 与 Claude 4 Sonnet 相当 (来源:Huggingface、Venture Beat)
- DeepSeek V3 支持的低资源语言比 GPT-4o 更多 (来源:Machine Translation)
- Llama 3.1 在数学和长上下文方面优于 GPT-4 和 Claude 3.5 Sonnet (来源:OpenAI Developer Community)
这些结果揭示了一个日益增长的现实:如果你了解自己的任务和约束,通常可以用开源模型以更低成本获得更好的结果。
默认使用 GPT-4 而非根据自身需求进行选择会带来以下后果:
- 依赖专用推理的产品不得不接受通用模型的及格水平输出,而更专业(且通常更小)的模型能提供更好的性能
- 在一个小模型就能胜任的任务上使用大模型,会增加能源使用并带来显著的负面环境影响
- 初创公司和小团队往往在昂贵的 API 上烧掉预算,而开源模型能轻松提供相同(或更好)的结果
- 大规模运营的企业在高吞吐量推理上积累巨额成本,却不知开源替代方案可以将这些费用削减一半或更多
使用开源模型的理由
GPT-4x 和 Claude 3 系列模型是强大的通用模型,在编程到创意写作等广泛任务上能力全面。但它们的横向能力往往意味着对于目标工作负载或受限环境,它们并非最高效或最经济的选择。许多开源模型,包括紧凑型专家和大型通用替代方案,都能与之匹敌甚至超越,提供更好的速度、控制力和成本效益。
但为你的特定应用找到最优模型并将其投入生产是件难事。与 OpenAI 或 Claude 的闭源选项不同,开源模型很少被托管。你需要自己配置计算、延迟和吞吐量要求。这种复杂性导致许多开发者和公司默认选择熟悉的通用模型(如 GPT-4 或 Claude),即使开源替代方案(包括轻量级专家模型和强大的通用模型)能提供更好的性能、更快的响应和更低的成本。这正是 Novita 的用武之地。Novita 托管开源模型,并在必要时根据你的特定要求进行配置,让你无需费心即可使用这些模型。
Moonshot AI 的 Kimi K2 是一个突出的开源 LLM 例子,其性能超越了 GPT-4.1。在编程和数学推理方面,Kimi K2 达到 53.7% 的准确率,而 GPT-4.1 为 44.7% (来源:Huggingface)。
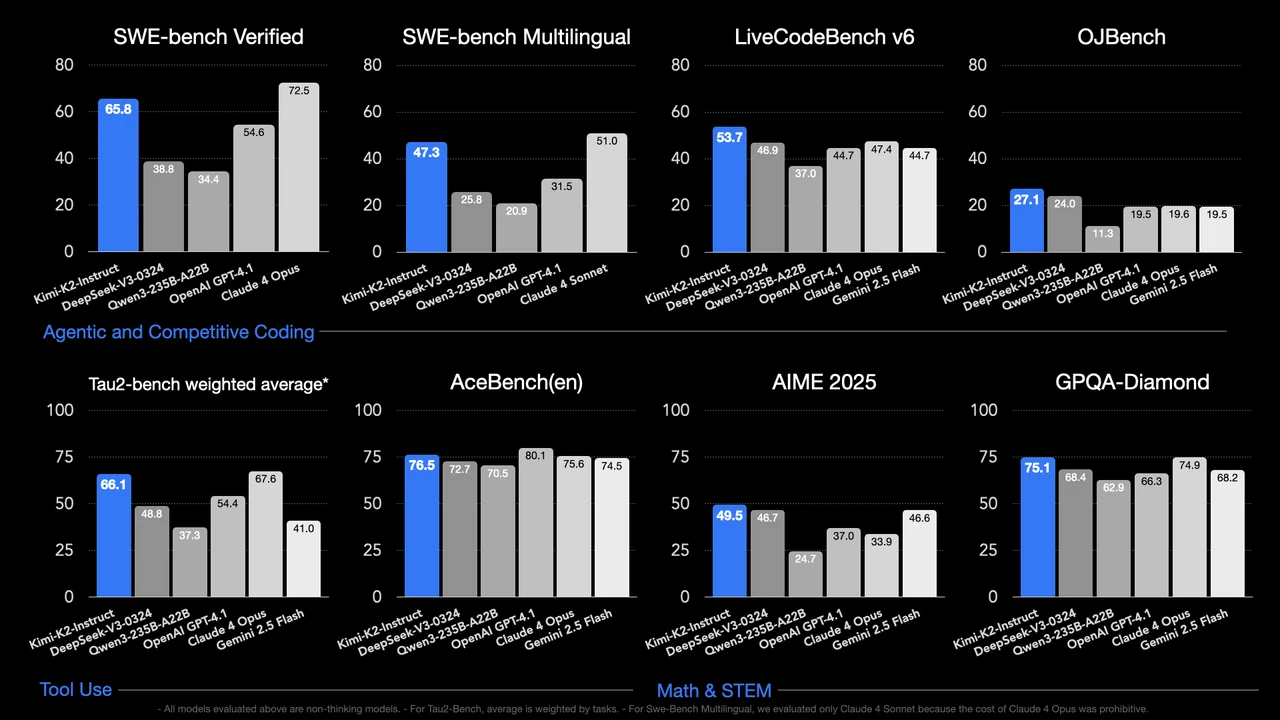
标题:Kimi K2 与 GPT-4.1 及其他行业领导者的性能对比
来源:Huggingface
何时使用通用模型
GPT-4、Claude 和 Gemini 等闭源模型仍有其用武之地,尤其是在快速原型开发并需要一个强大的通用性能基准时。当你的工作负载涵盖多种任务且没有明确的专业化需求,或者你运行低吞吐量推理且成本还不是主要问题时,它们也是不错的选择。在这些情况下,通用模型的便利性、广泛能力和开箱即用的性能可以胜过其权衡。
随着使用量增长,值得为你的应用找到合适的模型。这个模型应该针对你的特定任务、约束和规模进行优化,而不是根据流行度或便利性来选择。这就引出了下一个问题: 如何为你的应用选择合适的模型?
如何为你的应用选择合适的模型
选择最佳模型不仅关乎在特定任务上的基准性能。这是一个优化问题,需要你在专业化、延迟、吞吐量和成本之间进行权衡。
以下是需要考虑的关键维度:
- 用例特异性: 你需要一个通用助手,还是像摘要或逻辑推理这样的专家任务?专业化用例通常受益于针对该任务微调的较小模型,而通用模型覆盖更广,但成本和延迟更高。
- 性能与延迟: 你的应用需要多快的响应?聊天机器人可能更青睐像 DeepSeek-V3 这样的轻量级或低延迟模型,它们能提供近乎即时的响应和强大的任务特定性能。较慢的模型可能损害用户体验,即使它们在理论上更强大。
- 成本与规模: *你预期的使用量是多少?每个请求只需几分钱早期可能微不足道。*但在规模化运行时,这些成本就会累积。在自己的基础设施上运行的开源模型(或使用像 Novita 这样的托管平台)可以在规模上大幅降低成本。
- 灵活性和控制: 你是否需要将模型调整到你的领域、语气或任务结构?开源模型让你可以微调并围绕你的需求优化模型,而不是围绕他人的需求。对于这种情况,Novita 为你自定义或微调的模型提供模型托管支持。
- 基础设施权衡: 你有什么基础设施,或者你想避免管理什么?如果你想避免启动 GPU 或管理基础设施,很容易认为 GPT-4 这样的闭源模型是唯一选择。然而,像 Novita 这样的平台为开源模型提供同样无缝、完全托管的体验,费用低至 闭源模型的 50%。
这并不是抽象地挑选“最佳模型”。实际上,你是在竞争性约束(如任务匹配、延迟和成本)之间进行优化。合适的模型取决于你的目标,而一个好的平台可以让你轻松测试、切换和迭代,直到找到最优解。像 Artificial Analysis 这样的资源有助于厘清这些权衡,帮助你做出明智的决策。
超越一刀切方案
像 GPT-4 这样的模型之所以主导市场,并不一定意味着它们更好,只是它们更方便。但这种权衡已不再必要。像 Novita AI 这样的平台正在缩小开源权重与生产就绪之间的差距,让开发者无需处理基础设施即可访问数百个开源模型。所以不要默认使用 GPT-4。你的模型应该适应你的应用,而不是反过来。
在 Novita AI,我们的专家提供实操支持,包括自定义模型推荐和基础设施调优。我们将根据关键维度*(如专业化、延迟、吞吐量和成本效率)帮助你配置适合你特定用例的开源模型。我们提供* 你所期望的顶级 API 的速度、可靠性和易用性,同时兼具开源模型的灵活性和成本优势。 联系我们了解更多信息。*



