

為你的特定應用程式找到最佳模型並將其投入生產是困難的。與 OpenAI 或 Claude 的閉源選項不同,開源模型很少直接託管。你往往需要自行配置運算、延遲和吞吐量需求。這種複雜性導致許多開發者和公司預設使用熟悉的通用模型(如 GPT-4 或 Claude),即使開源替代方案(包括輕量級專家和強大的通用模型)能提供更好的性能、更快的回應和更低的成本。這就是 Novita 登場的地方。Novita 託管開源模型,並在必要時根據你的特定需求進行配置,讓你無需麻煩即可使用這些模型。
為什麼每個人都用 GPT-4?
AI 模型領域正在快速成長,包含數百個模型,每個都有其獨特的優勢和劣勢。然而,儘管開源模型的性能持續提升,GPT-4x 系列、Claude 3x 系列和其他閉源模型仍然是許多團隊的預設選擇。在這篇文章中,我們將分析何時該使用閉源模型、何時不該使用,以及 Novita 如何讓部署開源 LLM 變得與使用閉源模型一樣簡單。
這些流行的閉源模型是託管式的且易於使用,因此無需擔心基礎設施、設定或部署。你只需呼叫 API 即可獲得推理結果。這些模型也具有廣泛的能力,在寫作、推理和編碼等各種通用任務上表現良好。而且由於它們被廣泛採用,因此被認為是低風險的選擇。
…但代價是什麼?
預設使用封閉的通用模型可能感覺是最安全的選擇,但這往往會帶來隱藏成本。僅依賴閉源模型可能會讓你無法使用強大的開源替代方案(如 Qwen 和 DeepSeek),這些方案能提供相當或更好的結果,同時具有更高的控制性、透明度和長期成本效益。事實上,許多團隊最終為他們實際上不需要的規模和功能支付了過高的費用,在不需要龐大 100B+ 參數模型的任務上浪費了運算資源和能源,並帶來相應的環境影響。此外,在較小和/或更專業的模型表現出色的利基任務上,通用性能可能會受到影響。
許多開源模型現在在關鍵任務上能與頂級閉源模型匹敵或超越:
- Kimi K2、DeepSeek R1 和 Qwen 3 235B A22B 在編碼和數學推理任務上以更低的成本超越 GPT-4x 系列 (來源:Huggingface、GeeksforGeeks、Artificial Analysis)
- Qwen 2.5 7B Instruct 在 GPQA、HumanEval 和 MATH 基準測試上超越 GPT-4,同時僅使用極少的資源 (來源:LLM Stats)
- Qwen3-Coder-480B-A35B-Instruct 與 Claude 4 Sonnet 相當 (來源:Huggingface、Venture Beat)
- DeepSeek V3 支援比 GPT-4o 更多代表性不足的語言 (來源:Machine Translation)
- Llama 3.1 在數學和長上下文方面優於 GPT-4 和 Claude 3.5 Sonnet (來源:OpenAI Developer Community)
這些結果突顯了一個日益明顯的現實:如果你了解自己的任務和限制條件,通常可以用更低的成本透過開源模型獲得更好的結果。
預設使用 GPT-4 而非根據你的需求來選擇,會有以下後果:
- 依賴專業推理的產品,只能從通用模型中獲得勉強可接受的輸出,而更專業(且通常更小)的模型能提供更好的性能
- 當較小模型就能勝任時使用大型模型,會增加能源使用並對環境造成顯著的負面影響
- 新創公司和小型團隊常常將預算燒在昂貴的 API 上,而開源模型可以輕鬆達到相同(或更好)的結果
- 大規模企業在高吞吐量推理上累積巨額成本,卻不知開源替代方案可以將費用削減一半或更多
使用開源模型的理由
像 GPT-4x 和 Claude 3 系列這樣的模型是強大的通才,在從編碼到創意寫作的廣泛任務中具有廣泛能力。但它們的水平能力往往意味著它們並非針對特定工作負載或受限環境的最有效或最具成本效益的選擇。許多開源模型,包括緊湊型專家和大型通用替代方案,都能夠匹敵或超越它們,提供更好的速度、控制性和成本效益。
但為你的特定應用程式找到最佳模型並將其投入生產是困難的。與 OpenAI 或 Claude 的閉源選項不同,開源模型很少直接託管。你往往需要自行配置運算、延遲和吞吐量需求。這種複雜性導致許多開發者和公司預設使用熟悉的通用模型(如 GPT-4 或 Claude),即使開源替代方案(包括輕量級專家和強大的通用模型)能提供更好的性能、更快的回應和更低的成本。這就是 Novita 登場的地方。Novita 託管開源模型,並在必要時根據你的特定需求進行配置,讓你無需麻煩即可使用這些模型。
Moonshot AI 的 Kimi K2 是一個出色的開源 LLM 範例,其性能超越 GPT-4.1。在編碼和數學推理方面,Kimi-K2 達到了 53.7% 的準確率,而 GPT-4.1 為 44.7%(來源:Huggingface)。
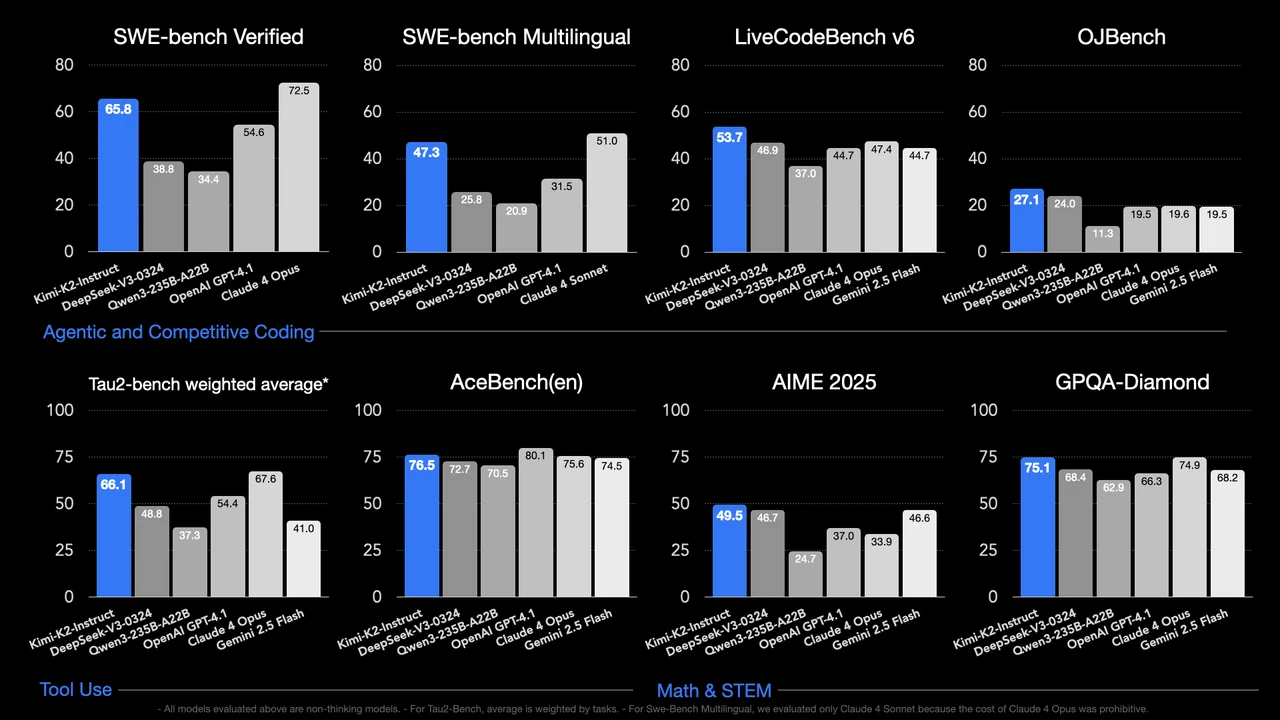
標題:Kimi K2 與 GPT-4.1 及其他業界領導者的性能比較
來源:Huggingface
何時該使用通用模型
像 GPT-4、Claude 和 Gemini 這樣的閉源模型仍有其用武之地,尤其是在快速原型設計且需要強通用性能基準的情況下。當你的工作負載涵蓋廣泛任務且沒有明確專業化時,或者當你進行低流量推理且成本還不是主要考量時,它們也是不錯的選擇。在這些情況下,通用模型的便利性、廣泛能力和開箱即用的性能可以勝過其取捨。
隨著使用量的成長,為你的應用程式找到合適的模型是值得的。這個模型應根據你的特定任務、限制條件和規模進行最佳化,而不是根據流行或方便與否。這就引出了下一個問題:如何為你的應用程式選擇合適的模型?
如何為你的應用程式選擇合適的模型
選擇最佳模型不僅僅是關於狹義任務的基準性能。這是一個最佳化問題,需要你在專業化、延遲、吞吐量和成本之間取得平衡。
以下是要考慮的關鍵維度:
- 使用案例的特定性:你需要一個通用助理,還是擅長摘要或邏輯推理等任務的專家?專業化使用案例通常受益於針對該任務微調的較小模型,而通用模型則提供更廣泛的覆蓋範圍,但成本和延遲更高。
- 性能與延遲:你的應用程式需要多快的回應速度?聊天機器人會偏好更輕量或低延遲的模型(如 DeepSeek-V3),它們能提供近乎即時的回應並具有強大的任務特定性能。較慢的模型可能會損害用戶體驗,即使它們在理論上更強大。
- 成本與規模:*你預期的使用量是多少?每個請求成本僅為幾分之一美分的模型,在初期可能看起來微不足道。*然而,在大規模運行時,這些成本會累積起來。在你自己的基礎設施上(或使用像 Novita 這樣的託管平台)運行開源模型,可以在大規模時顯著降低成本。
- 靈活性和控制:你需要根據你的領域、語調或任務結構來調整模型嗎?開源模型讓你可以選擇微調和最佳化模型以符合你的需求,而不是圍繞他人的需求進行調整。在這種情況下,Novita 為你的自訂或微調模型提供模型託管支援。
- 基礎設施取捨:*你擁有或希望避免管理哪些基礎設施?如果你希望避免啟動 GPU 或管理基礎設施,很容易假設像 GPT-4 這樣的閉源模型是你唯一的選擇。*然而,像 Novita 這樣的平台為開源模型提供了同樣無縫、完全託管的體驗,成本低至 閉源模型的 50%。
這不是抽象地挑選「最佳模型」。在實務中,你是在相互競爭的限制條件中進行最佳化,例如任務適合度、延遲和成本。正確的模型取決於你的目標,而一個好的平台能讓你輕鬆測試、切換和迭代,直到找到最佳契合點。像 Artificial Analysis 這樣的資源有助於釐清這些取捨,並幫助你做出明智的決策。
超越單一方案
像 GPT-4 這樣的模型的主導地位並不代表它們更好,只是因為它們方便。但這種取捨已不再必要。像 Novita AI 這樣的平台正在縮小開源權重與生產就緒之間的差距,為開發者提供數百個開源模型的使用權限,而無需煩惱基礎設施問題。所以,不要預設使用 GPT-4。你的模型應該適合你的應用程式,而不是反過來。
在 Novita AI,我們的專家提供實作支援,包括自訂模型推薦和基礎設施調校。我們將根據專業化、延遲、吞吐量和成本效益等關鍵維度,幫助你為特定使用案例配置合適的開源模型。我們提供你期望從頂級 API 獲得的速度、可靠性和易用性,同時兼具開源模型的靈活性和成本優勢。 聯絡我們 以獲取更多資訊。



