

許多開發者與企業在反覆使用大型語言模型處理相似提示詞時,都苦於高延遲與高 Token 成本。每次請求都會迫使模型重新處理相同的指令或文件,浪費運算資源與時間。
本文將說明提示詞快取(Prompt Caching)如何透過儲存預先計算的提示詞前綴,實現跨請求重複使用,解決上述問題。同時會釐清提示詞快取與 KV 快取的差異、展示 Novita AI 等系統如何實現高效快取,並提供結構化提示詞、監控快取效能、避免誤用與安全風險的實用指南。
什麼是提示詞快取(Prompt Caching)?
提示詞快取是指儲存提示詞的預先計算部分(例如系統指令、重複出現的上下文或文件),當你重複使用相同或相似的提示詞時,模型就能避免從頭重新計算。
若要提示詞快取成功命中,以下 Token 序列必須完全相同:
System: [system_instructions] # 固定前綴,可重複使用
Document: [retrieved_context] # 內容變更會導致快取無法重用
User: [query] # 內容變更會導致快取無法重用
| 步驟 | 說明 |
|---|---|
| 1. 提示詞提交 | 發送包含長提示詞或重複提示詞的請求到模型。 |
| 2. 編碼與快取 | 系統將提示詞前綴編碼為內部嵌入或隱藏狀態,並儲存到快取中。 |
| 3. 快取命中檢查 | 當後續請求包含相同前綴時,系統會偵測到匹配並載入快取的表示。 |
| 4. 重複使用與續接 | 模型跳過重新處理該前綴,從快取狀態繼續生成內容。 |
| 5. 過期 | 快取條目會在設定的存活時間(TTL)後過期(例如 Amazon Bedrock 的 5 分鐘無活動過期,每次重用會重置 TTL)。 |
https://www.youtube.com/watch?v=RDjaUJz-uWo
提示詞快取與 KV 快取有什麼差異?
| 面向 | KV 快取 | 提示詞快取 |
|---|---|---|
| 範圍 | 單次生成或工作階段內 | 跨多個請求或工作階段 |
| 用途 | 避免重新計算先前 Token 的注意力權重 | 避免重新處理重複的提示詞前綴 |
| 儲存資料 | Transformer 的注意力鍵與值 | 編碼後的提示詞前綴或模組 |
| 優點 | 降低單一 Token 的延遲 | 降低輸入 Token 成本與完整提示詞處理時間 |
| 典型用途 | 自回歸解碼(例如 LLM 生成) | 在應用程式或 API 中重複使用通用提示詞 |
提示詞快取如何降低延遲與運算成本?
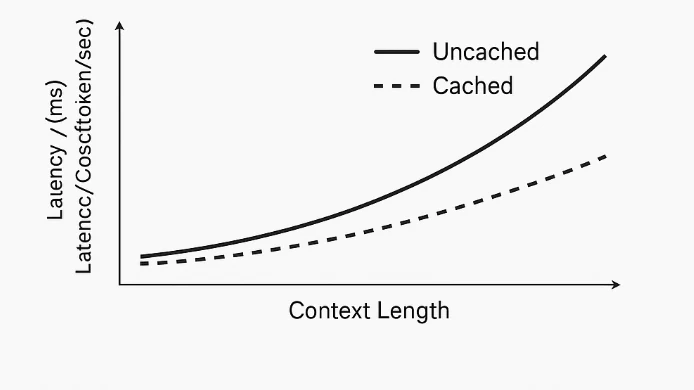
提示詞快取運作於系統層級,而非模型內部。模型本身會平等處理所有 Token,不會區分「提示詞」與「參考內容」。當偵測到重複的 Token 前綴時,系統會快取其計算後的表示(例如嵌入與 Transformer 狀態)。在後續帶有相同前綴的請求中,模型會跳過重新計算該部分,僅處理新的 Token。這樣就能減少冗餘運算、降低延遲,並減少與 Token 相關的成本。
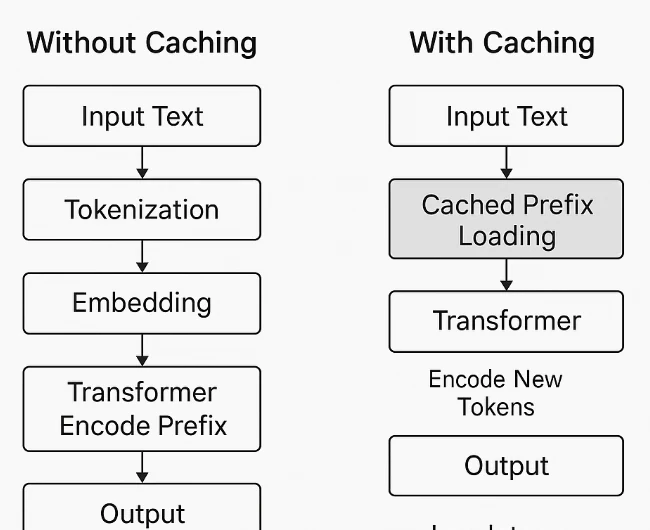
Novita AI 的提示詞快取功能
Novita AI 已擴充模型陣列,為多款高上下文模型加入提示詞快取支援,讓開發者能大幅降低長提示詞或重複任務的成本與延遲。提示詞快取會儲存先前使用過的提示詞或嵌入,後續引用相同內容的 API 呼叫就能以更低的快取讀取費率處理。
此功能非常適合多輪對話、檢索增強生成(RAG)系統,或是會重複使用大型系統提示詞的工作流程管線。透過快取讀取,團隊能在維持模型準確率與上下文完整性的前提下,獲得更快的回應速度與更低的成本。
支援的模型與定價
| 模型 | 上下文長度 | 輸入價格(每百萬 Token) | 快取讀取價格(每百萬 Token) | 輸出價格(每百萬 Token) |
|---|---|---|---|---|
| deepseek/deepseek-v3-0324 | 163,840 | $0.27 / Mt | $0.135 / Mt | $1.12 / Mt |
| deepseek/deepseek-r1-0528 | 163,840 | $0.70 / Mt | $0.35 / Mt | $2.50 / Mt |
| zai-org/glm-4.6 | 204,800 | $0.60 / Mt | $0.11 / Mt | $2.20 / Mt |
| zai-org/glm-4.5 | 131,072 | $0.60 / Mt | $0.11 / Mt | $2.20 / Mt |
| zai-org/glm-4.5v | 65,536 | $0.60 / Mt | $0.11 / Mt | $1.80 / Mt |
💡 功能意義
這些模型的上下文長度最高可達 204k Token,能處理極長的輸入內容,例如完整文件、逐字稿或程式碼庫。提示詞快取的加入確保使用者能重複使用大型提示詞,而無需每次都支付完整的輸入成本——既能降低總支出,也能提升重複查詢的回應速度。
開發者現在可以直接在 Novita AI 的基礎設施上,建構可擴展、高成本效益且富含上下文的 AI 應用程式。
如何更有效地使用提示詞快取?
如何撰寫提示詞結構以提高命中率?
- 將靜態前綴(指令、文件、模板)與可變查詢分離。
- 跨請求保持前綴文字完全一致。
- 明確定義快取檢查點邊界。
- 使用模組化模板,例如「System: [role]… Document: [context]… User: [query]。」
快取多久會過期? 實作方式與過期時間因供應商、工作負載與設定而異。部分系統會在數分鐘或數小時後過期快取;部分則會保留到達到記憶體上限為止。
如果稍微修改提示詞,是否仍能命中快取? 無法保證。快取命中取決於前綴的完全匹配或結構重用,即使是很小的文字或格式差異都可能導致快取未命中。
動態內容能否被快取? 只有提示詞的靜態部分能有效被快取。使用者資料、時間戳或即時數值等動態元素應保留在快取前綴之外。
不同模型版本能否重用同一份快取? 通常不行。快取會綁定特定的模型架構、分詞器與嵌入空間,升級或切換模型通常會使舊快取失效。
長文本或 RAG(檢索增強生成)場景的情況如何? 提示詞快取在大型靜態文件或前綴重複出現的場景中效果最好,例如文件問答。而在 RAG 場景中,檢索到的上下文會隨每次查詢改變,只有部分前綴能重用,因此快取命中率較低。
使用提示詞快取時需要注意哪些風險?
過期或錯誤命中
- 如果上下文發生變化(例如文件更新),快取的前綴可能會過時。
- 邊界錯誤或動態內容不匹配可能導致語意漂移。
隱私與安全風險
- 多租戶系統中的共享 KV 或提示詞快取可能導致使用者資料外洩。
- 「PROMPTPEEK」攻擊證明了可透過共享快取側通道重建提示詞。
- 請勿在共享的快取前綴中包含動態或使用者特定的資料。
監控有效性 追蹤命中與未命中率、快取讀取 Token 數與總 Token 數的比值、延遲降低幅度與成本節省情況。
避免誤用
- 僅快取靜態內容。
- 來源資料變更時使快取失效。
- 為每個使用者或租戶隔離快取以維護隱私。
未來發展方向
- 強化快取識別功能,支援語意前綴匹配。
- 建構跨模型與工作階段的統一、安全快取系統。
- 使用跨 GPU、CPU 與磁碟的壓縮與卸載技術。
提示詞快取透過跨請求重用相同的前綴嵌入,減少冗餘運算、降低延遲並節省 Token 成本。其效能取決於穩定的提示詞結構、靜態與動態內容的謹慎分離,以及負責任的快取管理。Novita AI 等供應商證明了低成本、穩定的快取能在維持安全與準確率的同時,提升整體效率。
Novita AI 是一個 AI 雲端平台,為開發者提供簡單的 API 來部署 AI 模型,同時也提供實惠且可靠的 GPU 雲端服務,用於建構與擴展 AI 應用。



