

Many developers and enterprises struggle with high latency and token costs when using large language models repeatedly on similar prompts. Each request forces the model to reprocess the same instructions or documents, wasting compute and time.
This article explains how Prompt Caching solves that problem by storing pre-computed prompt prefixes for reuse across requests. It clarifies the difference between Prompt Cache and KV Cache, shows how systems like Novita AI implement efficient caching and provides practical guidance on how to structure prompts, monitor cache performance, and avoid misuse or security risks.
What is Prompt Caching?
Prompt caching refers to storing pre-computed parts of a prompt (for example, system instructions, repeated context or documents) so that when you reuse the same or similar prompt, the model avoids recomputing from scratch.
For prompt cache to hit successfully, the following token sequences must be identical:
System: [system_instructions] # Fixed prefix, reusable
Document: [retrieved_context] # Changes will break cache reuse
User: [query] # Changes will break cache reuse| Step | Description |
|---|---|
| 1. Prompt submission | A request with a long or repeated prompt is sent to the model. |
| 2. Encoding & caching | The system encodes the prompt prefix into internal embeddings or hidden states, then stores them in a cache. |
| 3. Cache hit check | When a later request includes the same prefix, the system detects a match and loads the cached representation. |
| 4. Reuse & continuation | The model skips reprocessing that prefix and continues generation from the cached state. |
| 5. Expiry | Cached entries expire after a defined TTL (e.g., 5 minutes of inactivity on Amazon Bedrock). TTL resets on each reuse). |
https://www.youtube.com/watch?v=RDjaUJz-uWo
How is Prompt Cache Different From KV Cache?
| Aspect | KV Cache | Prompt Cache |
|---|---|---|
| Scope | Within a single generation or session | Across multiple requests or sessions |
| Purpose | Avoids re-computing attention for previous tokens | Avoids re-processing repeated prompt prefixes |
| Stored Data | Transformer attention keys and values | Encoded prompt prefixes or modules |
| Benefit | Reduces per-token latency | Reduces input-token cost and full prompt processing time |
| Typical Use | Autoregressive decoding (e.g., LLM generation) | Reusing common prompts in applications or APIs |
How Does Prompt Caching Reduce Latency and Compute Cost?
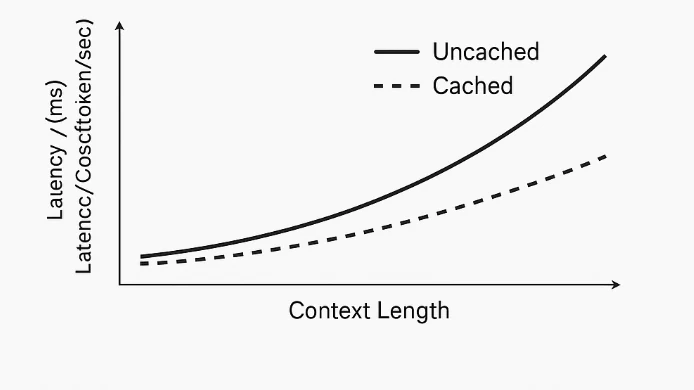
Prompt caching works at the system level, not inside the model. The model itself processes all tokens equally and does not distinguish between “prompt” and “reference content.” When a repeated prefix of tokens is detected, the system caches its computed representations—such as embeddings and transformer states. On subsequent requests with the same prefix, the model skips recomputing that portion and only processes the new tokens. This reduces redundant computation, lowers latency, and decreases token-related costs.
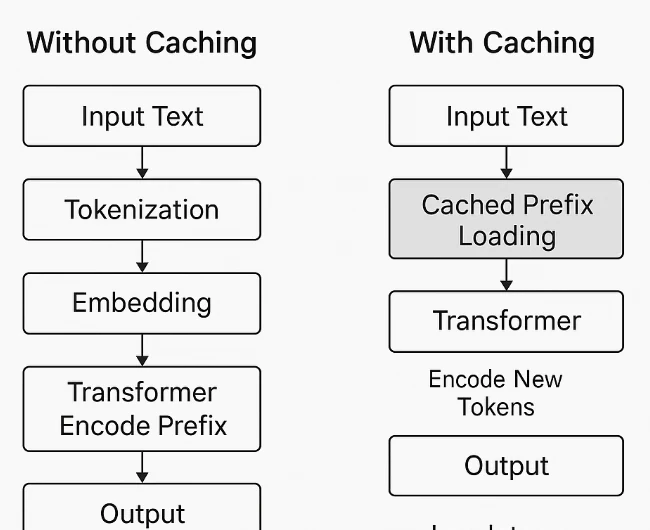
Prompt Caching on Novita AI
Novita AI has expanded its model lineup to include Prompt Cache support across several high-context models, allowing developers to significantly cut costs and improve latency for long or repeated tasks. Prompt caching stores previously used prompts or embeddings so subsequent API calls referencing the same content can be processed at a much lower Cache Read rate.
This feature is ideal for multi-turn conversations, retrieval-augmented generation (RAG) systems, or workflow pipelines that reuse large system prompts. By leveraging cached reads, teams can achieve faster responses and lower costs while maintaining model accuracy and context integrity.
Supported Models and Pricing
| Model | Context Window | Input Price (per 1M tokens) | Cache Read (per 1M tokens) | Output Price (per 1M tokens) |
|---|---|---|---|---|
| deepseek/deepseek-v3-0324 | 163,840 | $0.27 / Mt | $0.135 / Mt | $1.12 / Mt |
| deepseek/deepseek-r1-0528 | 163,840 | $0.70 / Mt | $0.35 / Mt | $2.50 / Mt |
| zai-org/glm-4.6 | 204,800 | $0.60 / Mt | $0.11 / Mt | $2.20 / Mt |
| zai-org/glm-4.5 | 131,072 | $0.60 / Mt | $0.11 / Mt | $2.20 / Mt |
| zai-org/glm-4.5v | 65,536 | $0.60 / Mt | $0.11 / Mt | $1.80 / Mt |
💡 Why It Matters
With context lengths reaching up to 204k tokens, these models can handle extremely long inputs such as entire documents, transcripts, or codebases. The addition of prompt caching ensures that users can reuse heavy prompts without paying full input costs each time — reducing total spend and improving response time across repeated queries.
Developers can now build scalable, cost-efficient, and context-rich AI applications directly on Novita AI’s infrastructure.
How Can You Use Prompt Caching More Effectively?
How should prompt structure be written to increase hit rate?
Separate static prefix (instructions, documents, templates) from variable query.
Keep the prefix text identical across requests.
Define cache-checkpoint boundaries clearly.
Use modular templates such as “System: [role]… Document: [context]… User: [query].”
How long until the cache expires?
Implementation and expiry vary by provider, workload, and configuration. Some systems expire caches after minutes or hours; others keep them until memory limits are reached.
If you change the prompt slightly, will you still hit the cache?
No guarantee. Cache hits depend on exact prefix matching or structural reuse. Even small text or formatting differences can cause a miss.
Can dynamic content be cached?
Only the static portion of a prompt can be cached effectively. Dynamic elements such as user data, timestamps, or real-time values should remain outside the cached prefix.
Can different model versions reuse the same cache?
Usually not. Caches tie to specific model architectures, tokenizers, and embedding spaces. Upgrading or switching models typically invalidates old caches.
What about long texts or RAG (retrieval-augmented generation) scenarios?
Prompt caching works best when a large static document or prefix repeats, as in document-based Q&A. In RAG, where retrieved context changes per query, only part of the prefix can be reused, so cache hit rates are lower.
What Risks Should You Watch Out for Prompt Caching?
Stale or Wrong Hits
Cached prefixes may become outdated if the context changes, such as when documents are updated.
Boundary errors or mismatched dynamic content can lead to semantic drift.
Privacy and Security Risks
Shared KV or prompt caches in multi-tenant systems can leak data between users.
The “PROMPTPEEK” attack demonstrated prompt reconstruction through shared cache side-channels.
Do not include dynamic or user-specific data in shared cached prefixes.
Monitoring Effectiveness
Track hit and miss rates, tokens read from cache versus total tokens, latency reduction, and cost savings.
Avoiding Misuse
Cache only static content.
Invalidate caches when source data changes.
Isolate caches per user or tenant to maintain privacy.
Future Directions
Enhance cache identification and support semantic prefix matching.
Build unified, secure cache systems across models and sessions.
Use compression and offloading across GPU, CPU, and disk.
Prompt caching reduces redundant computation, lowers latency, and cuts token costs by reusing identical prefix embeddings across requests. Its effectiveness depends on stable prompt structure, careful separation of static and dynamic content, and responsible cache management. Providers like Novita AI demonstrate how low-cost and stable caching can enhance overall efficiency while maintaining security and accuracy.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing an affordable and reliable GPU cloud for building and scaling.



