

Viele Entwickler und Unternehmen haben mit hoher Latenz und Token-Kosten zu kämpfen, wenn sie große Sprachmodelle wiederholt mit ähnlichen Prompts verwenden. Jede Anfrage zwingt das Modell, dieselben Anweisungen oder Dokumente erneut zu verarbeiten, was Rechenleistung und Zeit verschwendet.
Dieser Artikel erklärt, wie Prompt-Caching dieses Problem löst, indem es vorberechnete Prompt-Präfixe zur Wiederverwendung über Anfragen hinweg speichert. Er klärt den Unterschied zwischen Prompt-Cache und KV-Cache, zeigt, wie Systeme wie Novita AI effizientes Caching implementieren, und gibt praktische Hinweise zur Strukturierung von Prompts, zur Überwachung der Cache-Leistung sowie zur Vermeidung von Missbrauch und Sicherheitsrisiken.
Was ist Prompt-Caching?
Prompt-Caching bezeichnet die Speicherung vorberechneter Teile eines Prompts (z. B. Systemanweisungen, wiederholter Kontext oder Dokumente), sodass das Modell bei Wiederverwendung desselben oder eines ähnlichen Prompts eine erneute Berechnung von Grund auf vermeidet.
For prompt cache to hit successfully, the following token sequences must be identical:
System: [system_instructions] # Fixed prefix, reusable
Document: [retrieved_context] # Changes will break cache reuse
User: [query] # Changes will break cache reuse
| Schritt | Beschreibung |
|---|---|
| 1. Prompt-Übermittlung | Eine Anfrage mit einem langen oder wiederholten Prompt wird an das Modell gesendet. |
| 2. Codierung & Caching | Das System codiert den Prompt-Präfix in interne Einbettungen oder versteckte Zustände und speichert sie dann in einem Cache. |
| 3. Cache-Trefferprüfung | Wenn eine spätere Anfrage denselben Präfix enthält, erkennt das System eine Übereinstimmung und lädt die zwischengespeicherte Darstellung. |
| 4. Wiederverwendung & Fortsetzung | Das Modell überspringt die erneute Verarbeitung dieses Präfix und setzt die Generierung aus dem zwischengespeicherten Zustand fort. |
| 5. Ablauf | Zwischengespeicherte Einträge laufen nach einer definierten TTL ab (z. B. 5 Minuten Inaktivität bei Amazon Bedrock). Die TTL wird bei jeder Wiederverwendung zurückgesetzt. |
https://www.youtube.com/watch?v=RDjaUJz-uWo
Wie unterscheidet sich der Prompt-Cache vom KV-Cache?
| Aspekt | KV-Cache | Prompt-Cache |
|---|---|---|
| Geltungsbereich | Innerhalb einer einzelnen Generierung oder Sitzung | Über mehrere Anfragen oder Sitzungen hinweg |
| Zweck | Vermeidet die erneute Berechnung der Aufmerksamkeit für vorherige Token | Vermeidet die erneute Verarbeitung wiederholter Prompt-Präfixe |
| Gespeicherte Daten | Transformer-Aufmerksamkeitsschlüssel und -werte | Codierte Prompt-Präfixe oder Module |
| Vorteil | Reduziert die Latenz pro Token | Reduziert die Eingabe-Token-Kosten und die gesamte Prompt-Verarbeitungszeit |
| Typische Verwendung | Autoregressive Dekodierung (z. B. LLM-Generierung) | Wiederverwendung gängiger Prompts in Anwendungen oder APIs |
Wie reduziert Prompt-Caching Latenz und Rechenkosten?
Prompt-Caching funktioniert auf Systemebene, nicht innerhalb des Modells. Das Modell selbst verarbeitet alle Token gleich und unterscheidet nicht zwischen „Prompt“ und „Referenzinhalt“. Wenn ein wiederholter Token-Präfix erkannt wird, speichert das System seine berechneten Darstellungen – wie Einbettungen und Transformatorenzustände – zwischen. Bei nachfolgenden Anfragen mit demselben Präfix überspringt das Modell die erneute Berechnung dieses Teils und verarbeitet nur die neuen Token. Dadurch werden redundante Berechnungen reduziert, die Latenz gesenkt und tokenbezogene Kosten verringert.
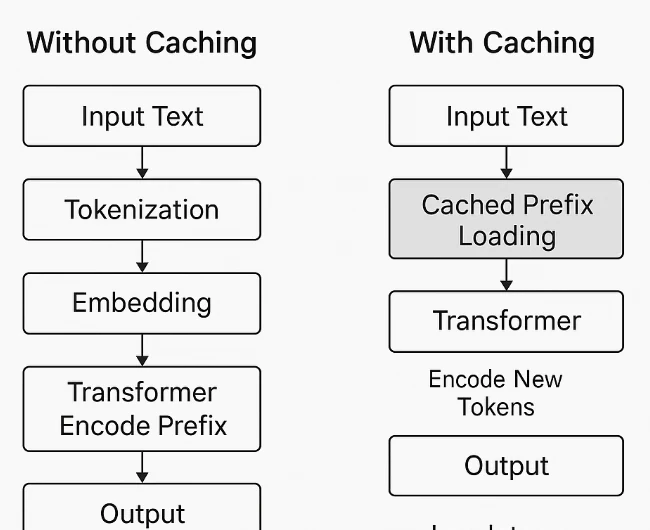
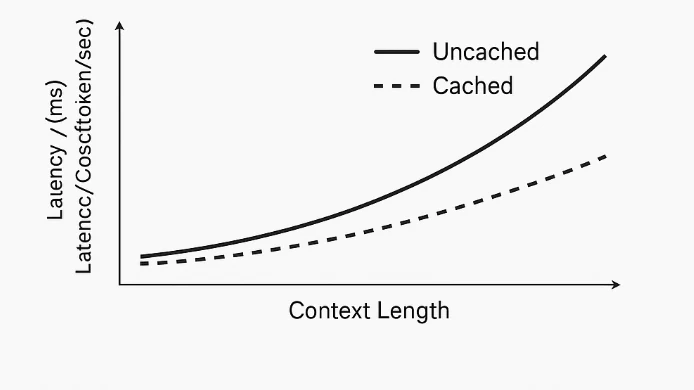
Prompt-Caching bei Novita AI
Novita AI hat sein Modellangebot erweitert und Prompt-Cache-Unterstützung für mehrere Modelle mit großem Kontextfenster hinzugefügt, sodass Entwickler Kosten deutlich senken und die Latenz für lange oder wiederholte Aufgaben verbessern können. Prompt-Caching speichert zuvor verwendete Prompts oder Einbettungen, sodass nachfolgende API-Aufrufe, die auf denselben Inhalt verweisen, zu einem deutlich niedrigeren Cache-Lesepreis verarbeitet werden können.
Diese Funktion eignet sich ideal für mehrturnige Gespräche, Systeme zur abrufgestützten Generierung (RAG) oder Workflow-Pipelines, die große System-Prompts wiederverwenden. Durch die Nutzung von zwischengespeicherten Lesevorgängen können Teams schnellere Antworten und niedrigere Kosten erzielen, während die Modellgenauigkeit und Kontextintegrität erhalten bleiben.
Unterstützte Modelle und Preise
| Modell | Kontextfenster | Eingabepreis (pro 1M Token) | Cache-Lesen (pro 1M Token) | Ausgabepreis (pro 1M Token) |
|---|---|---|---|---|
| deepseek/deepseek-v3-0324 | 163.840 | $0,27 / Mt | $0,135 / Mt | $1,12 / Mt |
| deepseek/deepseek-r1-0528 | 163.840 | $0,70 / Mt | $0,35 / Mt | $2,50 / Mt |
| zai-org/glm-4.6 | 204.800 | $0,60 / Mt | $0,11 / Mt | $2,20 / Mt |
| zai-org/glm-4.5 | 131.072 | $0,60 / Mt | $0,11 / Mt | $2,20 / Mt |
| zai-org/glm-4.5v | 65.536 | $0,60 / Mt | $0,11 / Mt | $1,80 / Mt |
💡 Warum das wichtig ist
Mit Kontextlängen von bis zu 204k Token können diese Modelle extrem lange Eingaben wie gesamte Dokumente, Transkripte oder Codebasen verarbeiten. Die Ergänzung von Prompt-Caching stellt sicher, dass Benutzer umfangreiche Prompts wiederverwenden können, ohne jedes Mal die vollen Eingabekosten zu zahlen – was die Gesamtausgaben senkt und die Antwortzeit bei wiederholten Anfragen verbessert.
Entwickler können jetzt skalierbare, kosteneffiziente und kontextreiche KI-Anwendungen direkt auf der Infrastruktur von Novita AI erstellen.
Wie können Sie Prompt-Caching effektiver nutzen?
Wie sollte die Prompt-Struktur aufgebaut werden, um die Trefferquote zu erhöhen?
- Trennen Sie den statischen Präfix (Anweisungen, Dokumente, Vorlagen) von der variablen Abfrage.
- Halten Sie den Präfix-Text über alle Anfragen hinweg identisch.
- Definieren Sie Cache-Kontrollpunkt-Grenzen klar.
- Verwenden Sie modulare Vorlagen wie „System: [Rolle]… Dokument: [Kontext]… Benutzer: [Abfrage]“.
Wie lange dauert es, bis der Cache abläuft? Implementierung und Ablauf variieren je nach Anbieter, Arbeitslast und Konfiguration. Einige Systeme lassen Caches nach Minuten oder Stunden ablaufen; andere behalten sie, bis Speicherlimits erreicht sind.
Wenn Sie den Prompt geringfügig ändern, erreichen Sie den Cache dann immer noch? Keine Garantie. Cache-Treffer hängen von exakter Präfix-Übereinstimmung oder struktureller Wiederverwendung ab. Selbst kleine Text- oder Formatierungsunterschiede können zu einem Fehlschlag führen.
Kann dynamischer Inhalt zwischengespeichert werden? Nur der statische Teil eines Prompts kann effektiv zwischengespeichert werden. Dynamische Elemente wie Benutzerdaten, Zeitstempel oder Echtzeitwerte sollten außerhalb des zwischengespeicherten Präfix bleiben.
Können verschiedene Modellversionen denselben Cache wiederverwenden? In der Regel nicht. Caches sind an spezifische Modellarchitekturen, Tokenizer und Einbettungsräume gebunden. Ein Upgrade oder Wechsel des Modells macht alte Caches in der Regel ungültig.
Wie verhält es sich mit langen Texten oder Szenarien der abrufgestützten Generierung (RAG)? Prompt-Caching funktioniert am besten, wenn ein großes statisches Dokument oder Präfix wiederholt wird, wie bei dokumentenbasierten Frage-Antwort-Systemen. Bei RAG, bei dem der abgerufene Kontext pro Abfrage ändert, kann nur ein Teil des Präfix wiederverwendet werden, sodass die Cache-Trefferquote niedriger ist.
Welche Risiken sollten Sie bei Prompt-Caching beachten?
Veraltete oder falsche Treffer
- Zwischengespeicherte Präfixe können veraltet werden, wenn sich der Kontext ändert, z. B. wenn Dokumente aktualisiert werden.
- Grenzfehler oder nicht übereinstimmende dynamische Inhalte können zu semantischer Abweichung führen.
Datenschutz- und Sicherheitsrisiken
- Gemeinsam genutzte KV- oder Prompt-Caches in Multi-Tenant-Systemen können Daten zwischen Benutzern lecken.
- Der „PROMPTPEEK“-Angriff hat die Rekonstruktion von Prompts über gemeinsame Cache-Seitenkanäle demonstriert.
- Fügen Sie keine dynamischen oder benutzerspezifischen Daten in gemeinsam genutzte zwischengespeicherte Präfixe ein.
Überwachung der Effektivität Verfolgen Sie Treffer- und Fehlschlagsraten, aus dem Cache gelesene Token im Vergleich zu Gesamt-Token, Latenzreduzierung und Kosteneinsparungen.
Vermeidung von Missbrauch
- Speichern Sie nur statische Inhalte zwischen.
- Machen Sie Caches ungültig, wenn sich Quelldaten ändern.
- Isolieren Sie Caches pro Benutzer oder Mandant, um die Privatsphäre zu wahren.
Zukünftige Entwicklungen
- Verbessern Sie die Cache-Identifizierung und unterstützen Sie semantische Präfix-Übereinstimmung.
- Erstellen Sie einheitliche, sichere Cache-Systeme über Modelle und Sitzungen hinweg.
- Nutzen Sie Komprimierung und Auslagerung über GPU, CPU und Festplatte.
Prompt-Caching reduziert redundante Berechnungen, senkt die Latenz und spart Token-Kosten, indem es identische Präfix-Einbettungen über Anfragen hinweg wiederverwendet. Seine Effektivität hängt von einer stabilen Prompt-Struktur, der sorgfältigen Trennung von statischen und dynamischen Inhalten sowie einem verantwortungsvollen Cache-Management ab. Anbieter wie Novita AI zeigen, wie kostengünstiges und stabiles Caching die Gesamteffizienz verbessern kann, während Sicherheit und Genauigkeit gewahrt bleiben.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Erstellen und Skalieren von Anwendungen bereitstellt.



