

Kimi K2 ist derzeit überall zu sehen – die Leute lieben seine Intelligenz und Vielseitigkeit, besonders seine herausragenden Agentenfähigkeiten. All die neuen Funktionen sind in aller Munde, und seien wir ehrlich: Viele von uns fragen sich, ob wir Kimi K2 zu Hause ausführen können und wie viel VRAM dafür eigentlich nötig wäre.
Die VRAM-Anforderungen von Kimi K2 erkunden
Kimi K2 ist das neueste Modell von Moonshot AI, bekannt für seine fortschrittlichen Agentenfähigkeiten. Diese Fähigkeiten werden durch den MuonClip-Optimizer ermöglicht, der fortgeschrittene Techniken zur Instabilitätsbehebung integriert. Der Agent wird durch simulierte Multi-Turn-Tool-Nutzungsszenarien trainiert, die Hunderte von Bereichen und Tausende von Tools abdecken, wobei die Daten von LLM-basierten Bewertern gemäß aufgabenspezifischer Rubriken gefiltert werden. Für das Reinforcement Learning verwendet Kimi K2 standardmäßige Belohnungssignale für überprüfbare Aufgaben wie Mathematik und Programmierung, während für nicht überprüfbare Aufgaben wie das Verfassen von Berichten auf rubrikenbasierte Selbsteinschätzungen zurückgegriffen wird. Kontinuierliches On-Policy-Learning gewährleistet ständige Verbesserung und verbesserte Urteilsfähigkeit.
Von Moonshot AI
Detaillierte Hardware-Anforderungen
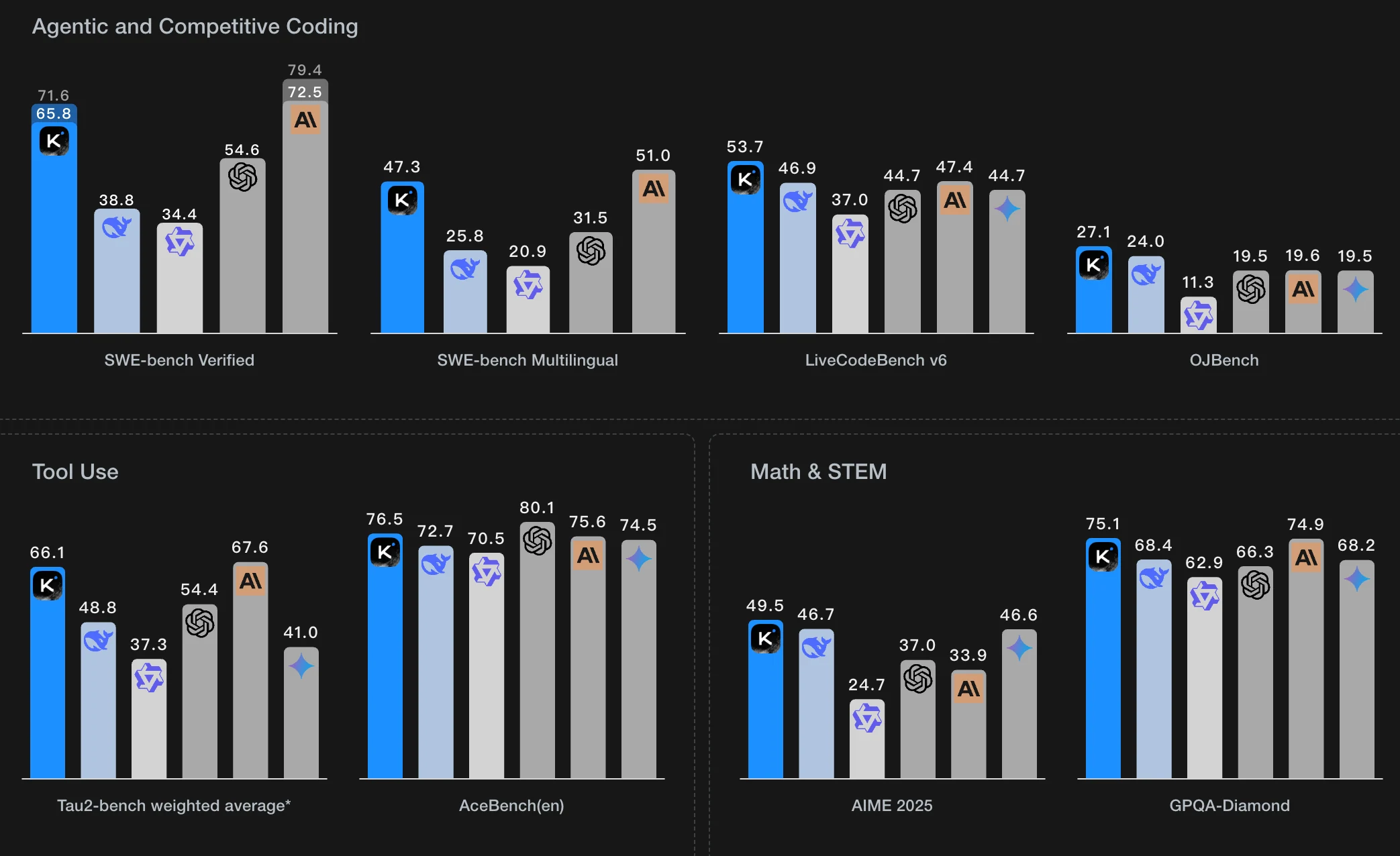
Als größtes Open-Source-Modell verfügt Kimi K2 über insgesamt 1 Billion Parameter, von denen zu jeder Zeit 32 Milliarden aktiviert sind. Diese enorme Größe erfordert erhebliche GPU-Ressourcen, um das Modell lokal auszuführen. Weitere Details finden Sie in den folgenden Tabellen, die von Apx. stammen.
Modelle in voller Präzision
| Modellvariante | Erforderlicher VRAM (GB) | Minimale GPU-Konfiguration |
|---|---|---|
| Kimi K2-Base | 2.401,52 | H100/A100 80GB (x32) |
| Kimi K2-Instruct | 2.401,52 | H100/A100 80GB (x32) |
| Kimi-VL-A3B | 51,87 | A100/H100 80GB (x1) |
| Kimi-Dev-72B | 177,27 | A100/H100 80GB (x3) |
Q4-quantisierte Modelle (Reduzierter VRAM, breitere Zugänglichkeit)
| Modellvariante | Erforderlicher VRAM (GB) | Minimale GPU-Konfiguration |
|---|---|---|
| Kimi K2-Base (Q4) | 632,61 | A100/H100 80GB (x8) |
| Kimi K2-Instruct (Q4) | 632,61 | A100/H100 80GB (x8) |
| Kimi-VL-A3B (Q4) | 15,56 | RTX 4080 (16GB) oder RTX 3090/4090 (24GB) |
| Kimi-Dev-72B (Q4) | 50 | RTX 6000 Ada (48GB) (x2) oder A100 80GB (x1) |
Vergleich der VRAM-Anforderungen mit anderen Modellen
| Modellname | Präzision / Kontext | Erforderlicher VRAM | Minimale GPU-Konfiguration |
|---|---|---|---|
| DeepSeek R1 671B | FP16 | 1.421,82 GB | 24 × H100 (80GB) 8 × H200 SXM (141GB) |
| DeepSeek V3 0324 | FP16 | 1.425,02 GB | 24 × H100 (80GB) |
| Llama 4 Maverick | FP16 / 128K Kontext | 938,1 GB | 12 × H100 (80GB) |
Trotz dieser Verbesserungen bleiben die Gesamtbereitstellungskosten aufgrund der Notwendigkeit fortschrittlicher Hardware, laufender Stromkosten und spezialisierter Fachkräfte für Wartung und Optimierung hoch.
So wählen Sie eine GPU aus, die die VRAM-Anforderungen von Kimi K2 erfüllt
| Attribut | Auswirkungen |
|---|---|
| Architektur | Funktionen, Effizienz, Kompatibilität |
| CUDA-/Tensor-/RT-Kerne | Modelltraining/-inferenzgeschwindigkeit, Grafik |
| VRAM/Speicherbandbreite | Unterstützte Modellgröße, Geschwindigkeit für große Datenmengen |
| FP8/FP16/FP32/FP64 | Präzision, Leistung und Geschwindigkeit für KI/Wissenschaft |
| Leistung (TDP) | Stromverbrauch, Kühlung, Rackplanung |
| NVLink/MIG/ECC | Skalierbarkeit, Zuverlässigkeit, Multi-Modell-Nutzung |
| Am besten geeignet für | Für welche Arbeitslasten die GPU optimiert ist |
| Kosten/Bereitstellung | Budgetplanung, einfacher Zugang |
Für ein Modell mit 1 Billion Parametern sollten Sie sich auf maximalen VRAM, starke NVLink-Unterstützung und effiziente Stromnutzung pro Leistung konzentrieren. Dies minimiert sowohl Kosten als auch Inferenz-/Trainingszeit.
Empfohlene GPUs für den Betrieb von Kimi K2
| Attribut | H100 (SXM) | B200 |
|---|---|---|
| VRAM | 80GB / 98GB HBM3 | 180 GB HBM3e |
| Speicherbandbreite | 3,9 TB/s | 8 TB/s pro GPU |
| NVLink | Ja (NVLink 4.0/NVSwitch) | Ja (NVLink / NVSwitch 5. Generation) |
| FP8-Leistung | 3,958 PFLOPS (dicht) | 9 PFLOPS |
| PCIe-Unterstützung | SXM nutzt NVLink, nicht PCIe | NVLink only (NVL72) |
| Leistung (TDP) | 700W (SXM) | 1.000W |
| ECC | Ja | Ja |
| MIG | Ja | Ja |
Preis der empfohlenen GPUs für den Betrieb von Kimi K2

Weitere Cloud-GPU-Preise ansehen
Allerdings ist der Betrieb von Kimi K2 auf eigener Hardware mit erheblichen finanziellen Belastungen verbunden. Gibt es also eine kostengünstigere Möglichkeit, die Fähigkeiten von Kimi K2 zu nutzen?
Für kleine Entwickler kann das Mieten von GPUs in der Cloud kosteneffizienter sein
Im Wesentlichen bieten Cloud-GPU-Lösungen wie Novita AI eine kosteneffiziente, flexible und problemlose Möglichkeit, auf erstklassige Rechenleistung zuzugreifen – und ermöglichen es Ihnen, schneller zu innovieren, den Betriebsaufwand zu reduzieren und in der sich schnell bewegenden KI-Welt die Nase vorn zu behalten.
Die günstigsten Preise – Novita AI
| Anbieter | GPU-Typ | Preis (USD/Std.) |
|---|---|---|
| Novita AI | H100 SXM 80GB | $2,56 |
| Lambda | H100 SXM 80GB | $3,29 |
| RunPod | H100 SXM 80GB | $3,20 |
Technische Herausforderungen für Heimserver
- Hohe anfängliche Hardwarekosten und laufende Wartung
- Schwierigkeiten bei der Skalierung von Ressourcen für schwankende Arbeitslasten
- Zeitaufwändige Hardwareeinrichtung und -konfiguration
- Eingeschränkter Zugang zur neuesten GPU-Technologie
Wie Cloud-GPU das Problem lösen kann
- Kosteneffizienz und keine Vorabinvestition
Der Kauf leistungsstarker GPUs für den lokalen Einsatz kann zehntausende Dollar an Anfangsinvestitionen erfordern, plus laufende Infrastrukturkosten für Strom, Kühlung und physische Räumlichkeiten. Mit Cloud-GPU-Diensten vermeiden Sie diese großen Investitionen vollständig. Das Pay-as-you-go-Modell bedeutet, dass Sie nur für die GPU-Stunden zahlen, die Sie tatsächlich nutzen. - Skalierbarkeit und On-Demand-Zugriff
Lokale GPU-Setups haben in der Regel eine feste Kapazität und können nicht einfach Spitzen in der Nachfrage oder neue Projektanforderungen bewältigen. Im Gegensatz dazu können Sie mit Cloud-Plattformen Ihre GPU-Ressourcen sofort skalieren. - Keine Hardwareeinrichtung oder Wartung
Die lokale Verwaltung von GPUs bedeutet oft komplexe Hardwareinstallation, Konfiguration, Treiberaktualisierungen und routinemäßige Wartung. Cloud-GPU-Plattformen übernehmen die gesamte Infrastrukturverwaltung für Sie, einschließlich Hardwarezuverlässigkeit, Kühlung, Stromversorgung und Systemkompatibilität.
Wie Sie auf Kimi K2 in der Cloud-GPU wie Novita AI zugreifen
Schritt 1: Registrieren Sie ein Konto
Wenn Sie neu bei Novita AI sind, erstellen Sie zunächst ein Konto auf unserer Website. Nach der Registrierung gehen Sie zur Registerkarte “GPUs”, um die verfügbaren Ressourcen zu erkunden und Ihre Reise zu beginnen.

Probieren Sie die leistungsstarken GPUs von Novita AI aus
Schritt 2: Vorlagen und GPU-Server erkunden
Wählen Sie zunächst eine Vorlage aus, die Ihren Projektanforderungen entspricht, wie z.B. PyTorch, TensorFlow oder CUDA. Wählen Sie die Version, die Ihren Anforderungen entspricht, z.B. PyTorch 2.2.1 oder CUDA 11.8.0. Wählen Sie dann die A100-GPU-Serverkonfiguration, die leistungsstarke Performance bietet, um anspruchsvolle Arbeitslasten mit ausreichend VRAM, RAM und Speicherkapazität zu bewältigen.

Schritt 3: Passen Sie Ihre Bereitstellung an
Nachdem Sie eine Vorlage und eine GPU ausgewählt haben, passen Sie Ihre Bereitstellungseinstellungen an, indem Sie Parameter wie die Betriebssystemversion (z.B. CUDA 11.8) anpassen. Sie können auch andere Konfigurationen anpassen, um die Umgebung an die spezifischen Anforderungen Ihres Projekts anzupassen.
Schritt 4: Starten Sie eine Instanz
Sobald Sie die Vorlage und die Bereitstellungseinstellungen festgelegt haben, klicken Sie auf “Launch Instance”, um Ihre GPU-Instanz einzurichten. Dies startet die Umgebungseinrichtung, sodass Sie die GPU-Ressourcen für Ihre KI-Aufgaben nutzen können.
Für Effizienz und Benutzerfreundlichkeit wählen Sie die API!
| Vorteil von Cloud-GPU | Verbleibende Herausforderung | Wie die API sie löst |
|---|---|---|
| Kosteneffizienz & keine Vorabinvestition | Manuelle Einrichtung und Ressourcenverwaltung können für Benutzer zeitaufwändig sein. | APIs automatisieren die Ressourcenbereitstellung und die Auftragseinreichung, reduzieren menschlichen Aufwand und Fehler. |
| Skalierbarkeit und On-Demand-Zugriff | Die Skalierung von Ressourcen erfordert oft manuelles Eingreifen oder fortgeschrittene Konfiguration. | APIs ermöglichen programmatische, sofortige Skalierung und Integration in Ihre bestehenden Arbeitsabläufe. |
| Keine Hardwareeinrichtung oder Wartung | Benutzer müssen möglicherweise Umgebungen konfigurieren oder Abhängigkeiten verwalten. | APIs bieten vorkonfigurierte Umgebungen und einfache Bereitstellung, wodurch die meisten Einrichtungsschritte entfallen. |
Bereitstellungs-API-Anleitung
Novita AI integriert die Anthropic API, um kimi k2 in Claude Code zu verwenden und übertrifft damit viele Branchenanbieter.
Es bietet auch APIs mit 131K Kontext, 131K maximaler Ausgabe, 2,01s Latenz, 11,06 TPS Durchsatz und Kosten von $0,57/Eingabe und $2,30/Ausgabe, was eine starke Unterstützung für die Maximierung des Code-Agent-Potenzials von Kimi K2 bietet.Novita AI
Schritt 1: Einloggen und auf die Modellbibliothek zugreifen
Loggen Sie sich in Ihr Konto ein und klicken Sie auf die Schaltfläche Model Library.

Probieren Sie jetzt Kimi K2 Instruct aus!
Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell aus, das Ihren Anforderungen entspricht.
Schritt 3: Starten Sie Ihre kostenlose Testphase
Beginnen Sie Ihre kostenlose Testphase, um die Fähigkeiten des ausgewählten Modells zu erkunden.
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung mit der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Rufen Sie die Seite „Settings“ auf und kopieren Sie den API-Schlüssel wie im Bild gezeigt.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.
Importieren Sie nach der Installation die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit der Interaktion mit Novita AI LLM zu beginnen. Dies ist ein Beispiel für die Verwendung der Chat-Completions-API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_1g0vYAKH0Oir6vI6y4PZIGyFLVvuJiJDx0jZiEeYivQFmDr15mi83mWi-_bdrs0C-Q2hk281SCn1f4oUB49loQ==",
)
model = "moonshotai/kimi-k2-instruct"
stream = True # or False
max_tokens = 65536
system_content = "Sei ein hilfreicher Assistent"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hallo!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Fazit: Kimi K2 ist ein Game-Changer, aber der lokale Betrieb ist schwierig, es sei denn, Sie haben verrückte Hardware. Cloud-GPU-Dienste wie Novita AI machen den Einstieg viel einfacher (und günstiger), um zu sehen, worum es bei der ganzen Aufregung geht.
Häufig gestellte Fragen
Warum ist Kimi K2 bei KI-Agenten so beliebt?
Die fortschrittlichen Agentenfähigkeiten von Kimi K2, das umfangreiche domänenübergreifende Training und die ständigen Verbesserungen haben es zu einer herausragenden Wahl für Entwickler gemacht, die intelligente, anpassungsfähige Werkzeuge benötigen. Sein Open-Source-Charakter und die starke Community-Unterstützung haben seine Beliebtheit nur noch gesteigert.
Kann ich Kimi K2 auf meinem Heimserver ausführen?
Obwohl technisch möglich, erfordert der lokale Betrieb von Kimi K2 extrem leistungsstarke GPUs mit großen VRAM-Mengen – Ressourcen, die für die meisten Heim-Setups normalerweise unerreichbar sind. Die meisten Benutzer finden Cloud-GPU-Plattformen als weitaus zugänglichere und kostengünstigere Alternative.
Was macht Cloud-GPU-Dienste wie Novita AI zu einer guten Option für Kimi K2?
Cloud-GPU-Dienste eliminieren die Notwendigkeit teurer Hardware-Investitionen, laufender Wartung und Energiekosten. Mit der Pay-as-you-go-Flexibilität und sofortigen Skalierbarkeit können Sie mit Kimi K2 zu einem Bruchteil der Kosten und Komplexität einer lokalen Bereitstellung experimentieren.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für den Aufbau und die Skalierung bietet.



