

Kimi K2 ينتشر في كل مكان الآن—يحب الناس مدى ذكائه وتعدد استخداماته، خاصة مع قدراته البارزة كعامل ذكي. جميع الميزات الجديدة جعلت الجميع يتحدثون عنه، ولنكن صريحين: الكثير منا يتساءل عما إذا كان بإمكانه تشغيل Kimi K2 في المنزل، وكم VRAM نحتاج حقًا لتحقيق ذلك.
استكشاف متطلبات VRAM لنموذج Kimi K2
Kimi K2 هو أحدث نموذج طورته Moonshot AI، المشهورة بقدراتها المتقدمة كعامل ذكي. قدراتها مدعومة بـ MuonClip Optimizer، الذي يدمج تقنيات متقدمة لحل عدم الاستقرار. يتم تدريب العامل الذكي من خلال محاكاة سيناريوهات استخدام أدوات متعددة الأدوار عبر مئات المجالات وآلاف الأدوات، مع تصفية البيانات بواسطة مقيمين يعتمدون على LLM وفقًا لمعايير محددة لكل مهمة. للتعلم التعزيزي، يستخدم Kimi K2 إشارات مكافأة قياسية للمهام القابلة للتحقق مثل الرياضيات والبرمجة، بينما يعتمد على التقييمات الذاتية القائمة على المعايير للمهام غير القابلة للتحقق مثل كتابة التقارير. يضمن التعلم المستمر على السياسة التحسين المستمر وتعزيز الحكم.
من Moonshot AI
متطلبات الأجهزة التفصيلية
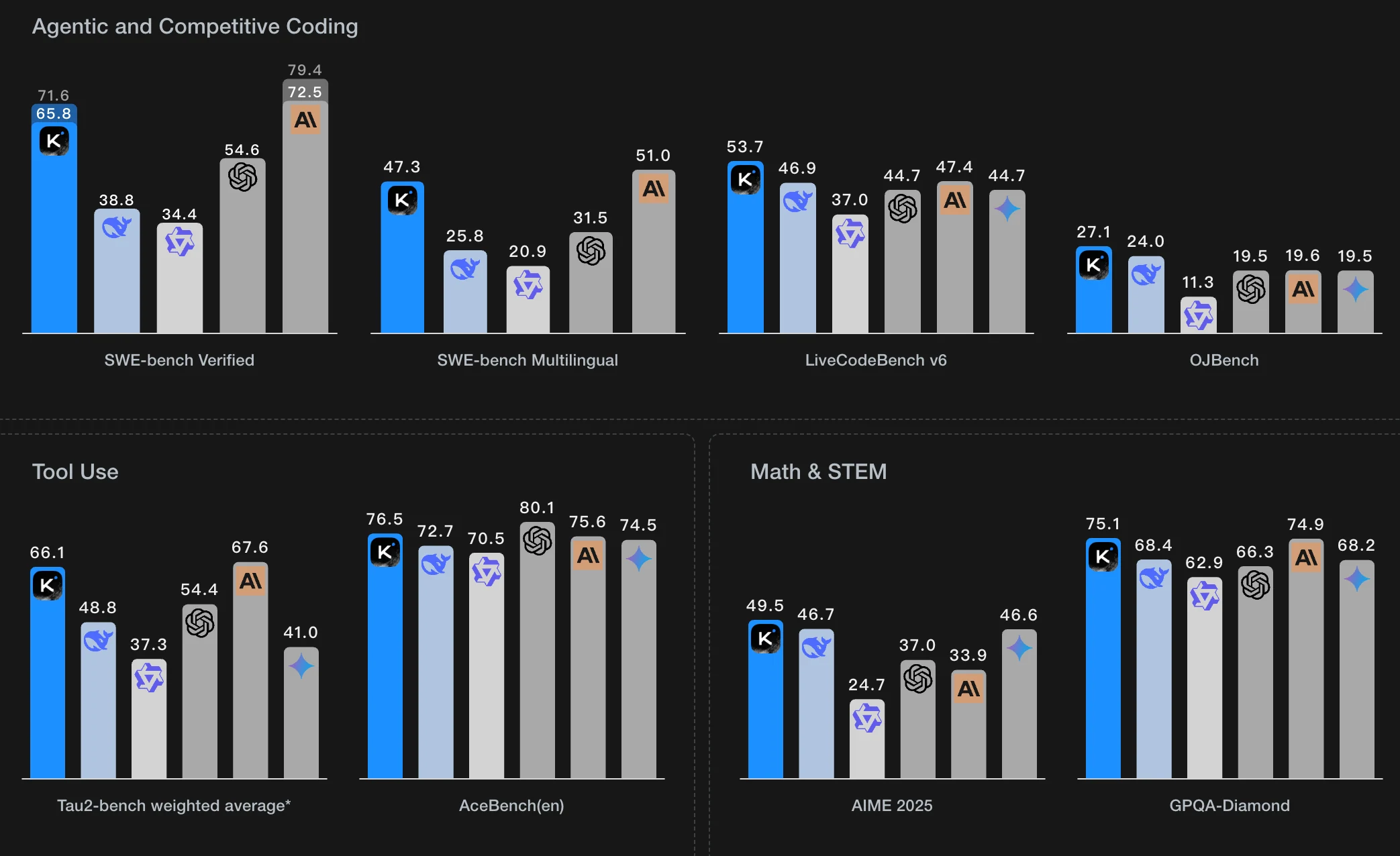
بصفته أكبر نموذج مفتوح المصدر، يتميز Kimi K2 بـ 1 تريليون معامل إجمالي، مع تنشيط 32 مليار معامل في أي وقت. هذا الحجم الهائل يتطلب موارد GPU كبيرة لتشغيله محليًا. يمكنك العثور على مزيد من التفاصيل في الجداول التالية، المستمدة من Apx.
نماذج الدقة الكاملة
| نوع النموذج | VRAM المطلوب (GB) | الحد الأدنى لإعداد GPU |
|---|---|---|
| Kimi K2-Base | 2,401.52 | H100/A100 80GB (x32) |
| Kimi K2-Instruct | 2,401.52 | H100/A100 80GB (x32) |
| Kimi-VL-A3B | 51.87 | A100/H100 80GB (x1) |
| Kimi-Dev-72B | 177.27 | A100/H100 80GB (x3) |
نماذج التكميم Q4 (VRAM أقل، قابلية وصول أوسع)
| نوع النموذج | VRAM المطلوب (GB) | الحد الأدنى لإعداد GPU |
|---|---|---|
| Kimi K2-Base (Q4) | 632.61 | A100/H100 80GB (x8) |
| Kimi K2-Instruct (Q4) | 632.61 | A100/H100 80GB (x8) |
| Kimi-VL-A3B (Q4) | 15.56 | RTX 4080 (16GB) أو RTX 3090/4090 (24GB) |
| Kimi-Dev-72B (Q4) | 50 | RTX 6000 Ada (48GB) (x2) أو A100 80GB (x1) |
مقارنة متطلبات VRAM مع النماذج الأخرى
| اسم النموذج | الدقة / السياق | VRAM المطلوب | الحد الأدنى لإعداد GPU |
|---|---|---|---|
| DeepSeek R1 671B | FP16 | 1,421.82 GB | 24 × H100 (80GB) 8 × H200 SXM (141GB) |
| DeepSeek V3 0324 | FP16 | 1,425.02 GB | 24 × H100 (80GB) |
| Llama 4 Maverick | FP16 / سياق 128K | 938.1 GB | 12 × H100 (80GB) |
ومع ذلك، على الرغم من هذه التحسينات، تظل تكاليف النشر الإجمالية مرتفعة بسبب الحاجة إلى أجهزة متطورة، ونفقات الكهرباء المستمرة، والموظفين المتخصصين للصيانة والتحسين.
كيفية اختيار GPU يلبي متطلبات VRAM لنموذج Kimi K2
| السمة | التأثيرات |
|---|---|
| الهيكل | الميزات، الكفاءة، التوافق |
| أنوية CUDA/Tensor/RT | سرعة تدريب/استدلال النموذج، الرسومات |
| VRAM/عرض النطاق الترددي للذاكرة | حجم النموذج المدعوم، السرعة للبيانات الكبيرة |
| FP8/FP16/FP32/FP64 | الدقة، الطاقة، والسرعة للذكاء الاصطناعي/العلوم |
| الطاقة (TDP) | الكهرباء، التبريد، تخطيط الرفوف |
| NVLink/MIG/ECC | قابلية التوسع، الموثوقية، الاستخدام متعدد النماذج |
| الأفضل لـ | أعباء العمل التي يتفوق فيها GPU |
| التكلفة/النشر | تخطيط الميزانية، سهولة الوصول |
لنموذج ذي 1 تريليون معامل، ركز على الحد الأقصى لـ VRAM، ودعم NVLink القوي، واستخدام الطاقة الفعال لكل أداء. هذا يقلل من التكلفة ووقت الاستدلال/التدريب.
GPUs الموصى بها لتشغيل Kimi K2
| السمة | H100 (SXM) | B200 |
|---|---|---|
| VRAM | 80GB / 98GB HBM3 | 180 GB HBM3e |
| عرض النطاق الترددي للذاكرة | 3.9 TB/s | 8 TB/s لكل GPU |
| NVLink | نعم (NVLink 4.0/NVSwitch) | نعم (NVLink / NVSwitch الجيل الخامس) |
| أداء FP8 | 3.958 PFLOPS (كثيف) | 9 PFLOPS |
| دعم PCIe | SXM يستخدم NVLink، وليس PCIe | NVLink فقط (NVL72) |
| الطاقة (TDP) | 700W (SXM) | 1,000W |
| ECC | نعم | نعم |
| MIG | نعم | نعم |
أسعار GPUs الموصى بها لتشغيل Kimi K2

اطلع على المزيد من أسعار GPU السحابية
ومع ذلك، فإن تشغيل Kimi K2 على أجهزتك الخاصة يأتي بعبء مالي كبير. إذن، هل هناك طريقة أكثر فعالية من حيث التكلفة للاستفادة من قدرات Kimi K2؟
بالنسبة للمطورين الصغار، يمكن أن يكون استئجار GPUs في السحابة أكثر فعالية من حيث التكلفة
باختصار، توفر حلول GPU السحابية مثل Novita AI وسيلة فعالة من حيث التكلفة، مرنة، وخالية من المتاعب للوصول إلى طاقة حوسبة من الدرجة الأولى—تمكنك من الابتكار بشكل أسرع، وتقليل الأعباء التشغيلية، والبقاء في المقدمة في عالم الذكاء الاصطناعي سريع الحركة.
أقل سعر - Novita AI
| المزود | نوع GPU | السعر (دولار/ساعة) |
|---|---|---|
| Novita AI | H100 SXM 80GB | $2.56 |
| Lambda | H100 SXM 80GB | $3.29 |
| RunPod | H100 SXM 80GB | $3.20 |
التحديات التقنية للخوادم المنزلية
- تكاليف الأجهزة الأولية المرتفعة والصيانة المستمرة
- صعوبة توسيع الموارد لأعباء العمل المتقلبة
- إعداد وتكوين الأجهزة المستهلك للوقت
- الوصول المحدود إلى أحدث تقنيات GPU
كيف يمكن لـ GPU السحابي حل المشكلة
- الفعالية من حيث التكلفة وعدم الاستثمار المسبق
قد يتطلب شراء GPUs عالية الأداء للاستخدام المحلي عشرات الآلاف من الدولارات كإنفاق أولي، بالإضافة إلى تكاليف البنية التحتية المستمرة للطاقة والتبريد والمساحة المادية. مع خدمات GPU السحابية، تتجنب هذه الاستثمارات الكبيرة تمامًا. يعني نموذج الدفع حسب الاستخدام أنك تدفع فقط مقابل ساعات GPU التي تستخدمها فعليًا. - قابلية التوسع والوصول حسب الطلب
عادة ما تكون إعدادات GPU المحلية ذات سعة ثابتة ولا يمكنها استيعاب الزيادات في الطلب أو متطلبات المشاريع الجديدة بسهولة. في المقابل، تسمح لك المنصات السحابية بتوسيع موارد GPU الخاصة بك على الفور. - لا حاجة لإعداد الأجهزة أو الصيانة
غالبًا ما تعني إدارة GPUs محليًا التعامل مع تثبيت الأجهزة المعقدة والتكوين وتحديثات برامج التشغيل والصيانة الروتينية. تتعامل منصات GPU السحابية مع جميع إدارة البنية التحتية نيابة عنك، بما في ذلك موثوقية الأجهزة والتبريد وإمدادات الطاقة وتوافق النظام.
كيفية الوصول إلى Kimi K2 على GPU سحابي مثل Novita AI؟
الخطوة 1: تسجيل حساب
إذا كنت جديدًا على Novita AI، ابدأ بإنشاء حساب على موقعنا. بمجرد التسجيل، انتقل إلى علامة التبويب “GPUs” لاستكشاف الموارد المتاحة وبدء رحلتك.

جرب GPUs عالية الأداء من Novita AI
الخطوة 2: استكشاف القوالب وخوادم GPU
ابدأ باختيار قالب يتناسب مع احتياجات مشروعك، مثل PyTorch أو TensorFlow أو CUDA. اختر الإصدار الذي يناسب متطلباتك، مثل PyTorch 2.2.1 أو CUDA 11.8.0. ثم حدد تكوين خادم GPU A100، الذي يوفر أداءً قويًا للتعامل مع أعباء العمل الصعبة مع سعة VRAM وRAM وقرص كافية.

الخطوة 3: تخصيص النشر الخاص بك
بعد اختيار قالب وGPU، قم بتخصيص إعدادات النشر الخاصة بك عن طريق ضبط المعاملات مثل إصدار نظام التشغيل (مثل CUDA 11.8). يمكنك أيضًا تعديل التكوينات الأخرى لتكييف البيئة مع متطلبات مشروعك المحددة.
الخطوة 4: تشغيل مثيل
بمجرد الانتهاء من القالب وإعدادات النشر، انقر على “Launch Instance” لإعداد مثيل GPU الخاص بك. سيؤدي ذلك إلى بدء إعداد البيئة، مما يتيح لك البدء في استخدام موارد GPU لمهام الذكاء الاصطناعي الخاصة بك.
للكفاءة وسهولة الاستخدام، اختر API!
| فائدة GPU السحابي | التحدي المتبقي | كيف يحلها API |
|---|---|---|
| الفعالية من حيث التكلفة وعدم الاستثمار المسبق | لا يزال الإعداد اليدوي وإدارة الموارد يستغرقان وقتًا للمستخدمين. | يقوم APIs بأتمتة توفير الموارد وتقديم الوظائف، مما يقلل من الجهد البشري والأخطاء. |
| قابلية التوسع والوصول حسب الطلب | غالبًا ما يتطلب توسيع الموارد تدخلاً يدويًا أو تكوينًا متقدمًا. | تمكن APIs التوسع البرمجي الفوري والتكامل مع سير العمل الحالي. |
| لا حاجة لإعداد الأجهزة أو الصيانة | قد لا يزال المستخدمون بحاجة إلى تكوين البيئات أو إدارة التبعيات. | تقدم APIs بيئات مهيأة مسبقًا ونشرًا سهلاً، مما يلغي معظم خطوات الإعداد. |
دليل API للنشر
تدمج Novita AI API الخاص بـ Anthropic لاستخدام kimi k2 في Claude Code
متفوقة على العديد من مقدمي الخدمات في الصناعة.
كما توفر APIs مع سياق 131K، خرج أقصى 131K، وقت استجابة 2.01s، إنتاجية 11.06 TPS، وتكاليف $0.57/الإدخال و $2.30/الإخراج، مما يوفر دعمًا قويًا لتعظيم إمكانات وكيل التعليمات البرمجية لـ Kimi K2.Novita AI
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر Model Library.

الخطوة 2: اختر نموذجك
تصفح الخيارات المتاحة وحدد النموذج الذي يناسب احتياجاتك.
الخطوة 3: ابدأ نسختك التجريبية المجانية
ابدأ نسختك التجريبية المجانية لاستكشاف قدرات النموذج المحدد.
الخطوة 4: احصل على مفتاح API الخاص بك
للمصادقة مع API، سنقدم لك مفتاح API جديد. بالذهاب إلى صفحة “Settings”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 5: تثبيت API
قم بتثبيت API باستخدام مدير الحزم الخاص بلغة البرمجة التي تستخدمها.
بعد التثبيت، قم باستيراد المكتبات الضرورية إلى بيئة التطوير الخاصة بك. قم بتهيئة API باستخدام مفتاح API الخاص بك لبدء التفاعل مع Novita AI LLM. هذا مثال على استخدام API لإكمال الدردشة لمستخدمي بايثون.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_1g0vYAKH0Oir6vI6y4PZIGyFLVvuJiJDx0jZiEeYivQFmDr15mi83mWi-_bdrs0C-Q2hk281SCn1f4oUB49loQ==",
)
model = "moonshotai/kimi-k2-instruct"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
الخلاصة: Kimi K2 هو تغيير قواعد اللعبة، لكن تشغيله محليًا صعب ما لم يكن لديك أجهزة خارقة. خدمات GPU السحابية مثل Novita AI تجعل البدء أسهل (وأرخص) لرؤية كل هذه الضجة.
الأسئلة الشائعة
لماذا يحظى Kimi K2 بشعبية كبيرة بين وكلاء الذكاء الاصطناعي؟
قدرات Kimi K2 المتقدمة كعامل ذكي، وتدريبه متعدد المجالات الواسع، والتحسينات المستمرة جعلته خيارًا بارزًا للمطورين الذين يحتاجون إلى أدوات ذكية وقابلة للتكيف. كما أن طبيعته مفتوحة المصدر ودعم المجتمع القوي زادا من شعبيته.
هل يمكنني تشغيل Kimi K2 على خادمي المنزلي؟
على الرغم من أنه ممكن تقنيًا، إلا أن تشغيل Kimi K2 محليًا يتطلب GPUs قوية جدًا بكميات كبيرة من VRAM—موارد عادة ما تكون بعيدة عن متناول معظم الإعدادات المنزلية. يجد معظم المستخدمين أن منصات GPU السحابية بديلاً أكثر سهولة وفعالية من حيث التكلفة.
ما الذي يجعل خدمات GPU السحابية مثل Novita AI خيارًا جيدًا لـ Kimi K2؟
تلغي خدمات GPU السحابية الحاجة إلى استثمارات الأجهزة المكلفة والصيانة المستمرة ونفقات الطاقة. مع مرونة الدفع حسب الاستخدام وقابلية التوسع الفورية، يمكنك تجربة Kimi K2 بجزء بسيط من التكلفة والتعقيد مقارنة بالنشر المحلي.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام API البسيط، مع توفير GPU سحابي ميسور التكلفة وموثوق للبناء والتوسع.



