

Kimi K2 は今、あらゆる場所で注目されています。特にその際立ったエージェント機能により、その賢さと汎用性の高さが人気を集めています。新しい機能が話題を呼び、正直なところ、多くの人が自宅でKimi K2を実行できるのか、そして実際にどれだけのVRAMが必要なのか気になっているでしょう。
Kimi K2のVRAM要件を探る
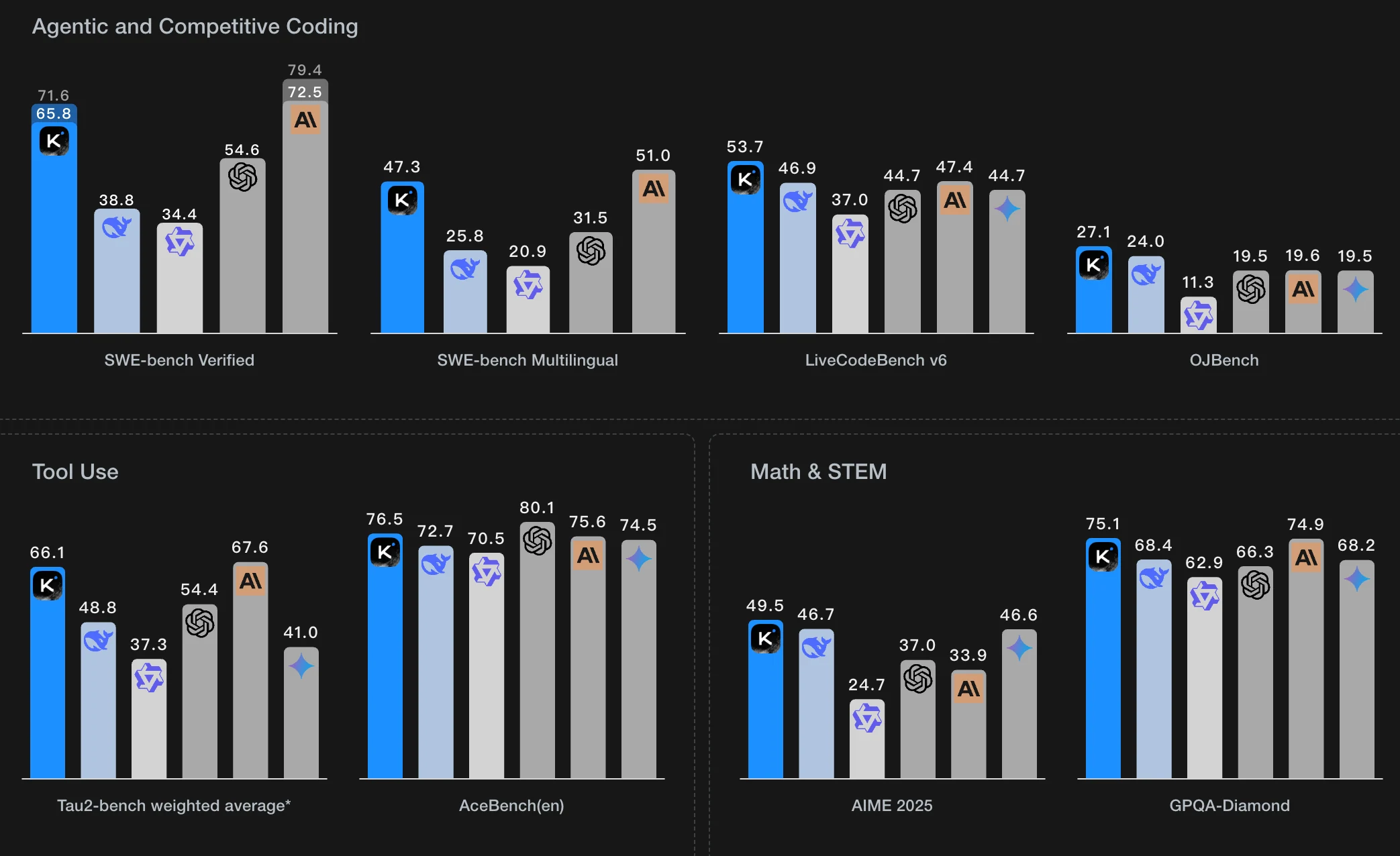
Kimi K2はMoonshot AIが開発した最新モデルで、高度なエージェント機能で知られています。その能力は、高度な不安定性解決技術を組み込んだMuonClip Optimizerによって支えられています。エージェントは、何百ものドメインと何千ものツールにわたるシミュレーションされたマルチターンツール使用シナリオを通じてトレーニングされ、データはタスク固有のルーブリックに従ったLLMベースの評価者によってフィルタリングされます。強化学習では、Kimi K2は数学やコーディングなどの検証可能なタスクには標準的な報酬信号を使用し、レポート作成などの検証不可能なタスクにはルーブリックベースの自己評価に依存します。継続的なオンポリシー学習により、継続的な改善と判断力の向上が保証されます。
Moonshot AI より
詳細なハードウェア要件
最大のオープンソースモデルとして、Kimi K2は合計1兆のパラメータを持ち、常時320億が活性化されています。この巨大な規模には、ローカルで実行するための相当なGPUリソースが必要です。詳細は以下の表から確認できます(出典:Apx.)。
フルプレシジョンモデル
| モデルバリアント | 必要なVRAM(GB) | 最小GPU構成 |
|---|---|---|
| Kimi K2-Base | 2,401.52 | H100/A100 80GB (x32) |
| Kimi K2-Instruct | 2,401.52 | H100/A100 80GB (x32) |
| Kimi-VL-A3B | 51.87 | A100/H100 80GB (x1) |
| Kimi-Dev-72B | 177.27 | A100/H100 80GB (x3) |
Q4量子化モデル(VRAM削減、アクセス性向上)
| モデルバリアント | 必要なVRAM(GB) | 最小GPU構成 |
|---|---|---|
| Kimi K2-Base (Q4) | 632.61 | A100/H100 80GB (x8) |
| Kimi K2-Instruct (Q4) | 632.61 | A100/H100 80GB (x8) |
| Kimi-VL-A3B (Q4) | 15.56 | RTX 4080 (16GB) または RTX 3090/4090 (24GB) |
| Kimi-Dev-72B (Q4) | 50 | RTX 6000 Ada (48GB) (x2) または A100 80GB (x1) |
他のモデルとのVRAM要件比較
| モデル名 | 精度 / コンテキスト | 必要なVRAM | 最小GPU構成 |
|---|---|---|---|
| DeepSeek R1 671B | FP16 | 1,421.82 GB | 24 × H100 (80GB) 8 × H200 SXM (141GB) |
| DeepSeek V3 0324 | FP16 | 1,425.02 GB | 24 × H100 (80GB) |
| Llama 4 Maverick | FP16 / 128Kコンテキスト | 938.1 GB | 12 × H100 (80GB) |
ただし、これらの改善にもかかわらず、高度なハードウェア、継続的な電気代、メンテナンスと最適化のための専門人員の必要性などにより、全体のデプロイコストは依然として高いままです。
Kimi K2のVRAM要件を満たすGPUの選び方
| **属性 ** | ** 影響** |
|---|---|
| アーキテクチャ | 機能、効率、互換性 |
| CUDA / Tensor / RTコア | モデルのトレーニング/推論速度、グラフィックス |
| VRAM / メモリ帯域幅 | サポートするモデルサイズ、ビッグデータの速度 |
| FP8 / FP16 / FP32 / FP64 | AI/科学のための精度、電力、速度 |
| 消費電力(TDP) | 電気代、冷却、ラック計画 |
| NVLink / MIG / ECC | 拡張性、信頼性、マルチモデル使用 |
| 最適な用途 | GPUが得意とするワークロード |
| コスト / 導入 | 予算計画、アクセスのしやすさ |
1兆パラメータモデルの場合、最大VRAM、強力なNVLinkサポート、およびパフォーマンスあたりの効率的な電力使用 に焦点を当ててください。これにより、コストと推論/トレーニング時間の両方を最小限に抑えられます。
Kimi K2実行におすすめのGPU
| 属性 | H100 (SXM) | B200 |
|---|---|---|
| VRAM | 80GB / 98GB HBM3 | 180 GB HBM3e |
| メモリ帯域幅 | 3.9 TB/s | 8 TB/s per GPU |
| NVLink | あり (NVLink 4.0/NVSwitch) | あり (NVLink / NVSwitch 第5世代) |
| FP8性能 | 3.958 PFLOPS (dense) | 9 PFLOPS |
| PCIeサポート | SXMはNVLinkを使用、PCIe非対応 | NVLinkのみ (NVL72) |
| 消費電力(TDP) | 700W (SXM) | 1,000W |
| ECC | あり | あり |
| MIG | あり | あり |
Kimi K2実行におすすめのGPU価格

しかし、自前のハードウェアでKimi K2を実行するには大きな経済的負担が伴います。では、Kimi K2の能力をより費用対効果の高い方法で活用する方法はあるのでしょうか?
小規模開発者にとっては、クラウドでGPUをレンタルする方が費用対効果が高い
要するに、Novita AIのようなクラウドGPUソリューションは、コスト効率が高く、柔軟で、手間のかからない方法で最上位のコンピューティングパワーへのアクセスを提供します。これにより、より迅速に革新し、運用オーバーヘッドを削減し、急速に進化するAIの世界で一歩先を行くことができます。
最安価格 — Novita AI
| プロバイダー | GPUタイプ | 価格(USD/時間) |
|---|---|---|
| Novita AI | H100 SXM 80GB | $2.56 |
| Lambda | H100 SXM 80GB | $3.29 |
| RunPod | H100 SXM 80GB | $3.20 |
ホームサーバーでの技術的課題
- 高い初期ハードウェアコストと継続的なメンテナンス
- 変動するワークロードに合わせたリソースの拡張が困難
- 時間のかかるハードウェアのセットアップと構成
- 最新GPU技術へのアクセス制限
クラウドGPUがどのように問題を解決するか
- コスト効率と初期投資ゼロ
高性能GPUをローカルで購入するには、数万ドルの初期費用に加え、電力、冷却、物理スペースのための継続的なインフラコストがかかります。クラウドGPUサービスでは、これらの大きな投資を完全に回避できます。従量課金制の料金モデルにより、実際に使用したGPU時間分だけを支払います。 - 拡張性とオンデマンドアクセス
ローカルGPUのセットアップは通常、容量が固定されており、需要の急増や新しいプロジェクト要件に容易に対応できません。対照的に、クラウドプラットフォームではGPUリソースを即座に拡張できます。 - ハードウェアのセットアップやメンテナンス不要
ローカルでGPUを管理する場合、複雑なハードウェアのインストール、構成、ドライバの更新、定期的なメンテナンスが必要になることがよくあります。クラウドGPUプラットフォームは、ハードウェアの信頼性、冷却、電源供給、システムの互換性など、すべてのインフラ管理を代行します。
Novita AIのようなクラウドGPUでKimi K2にアクセスする方法
ステップ1:アカウント登録
Novita AIが初めての場合は、ウェブサイトでアカウントを作成してください。登録後、「GPUs」タブに移動して、利用可能なリソースを確認し、旅を始めましょう。

ステップ2:テンプレートとGPUサーバーを探索
まず、プロジェクトのニーズに合ったテンプレート(PyTorch、TensorFlow、CUDAなど)を選択します。要件に合ったバージョン(PyTorch 2.2.1やCUDA 11.8.0など)を選びます。次に、十分なVRAM、RAM、ディスク容量を備えた高性能なワークロードを処理するために、A100 GPUサーバー構成を選択します。

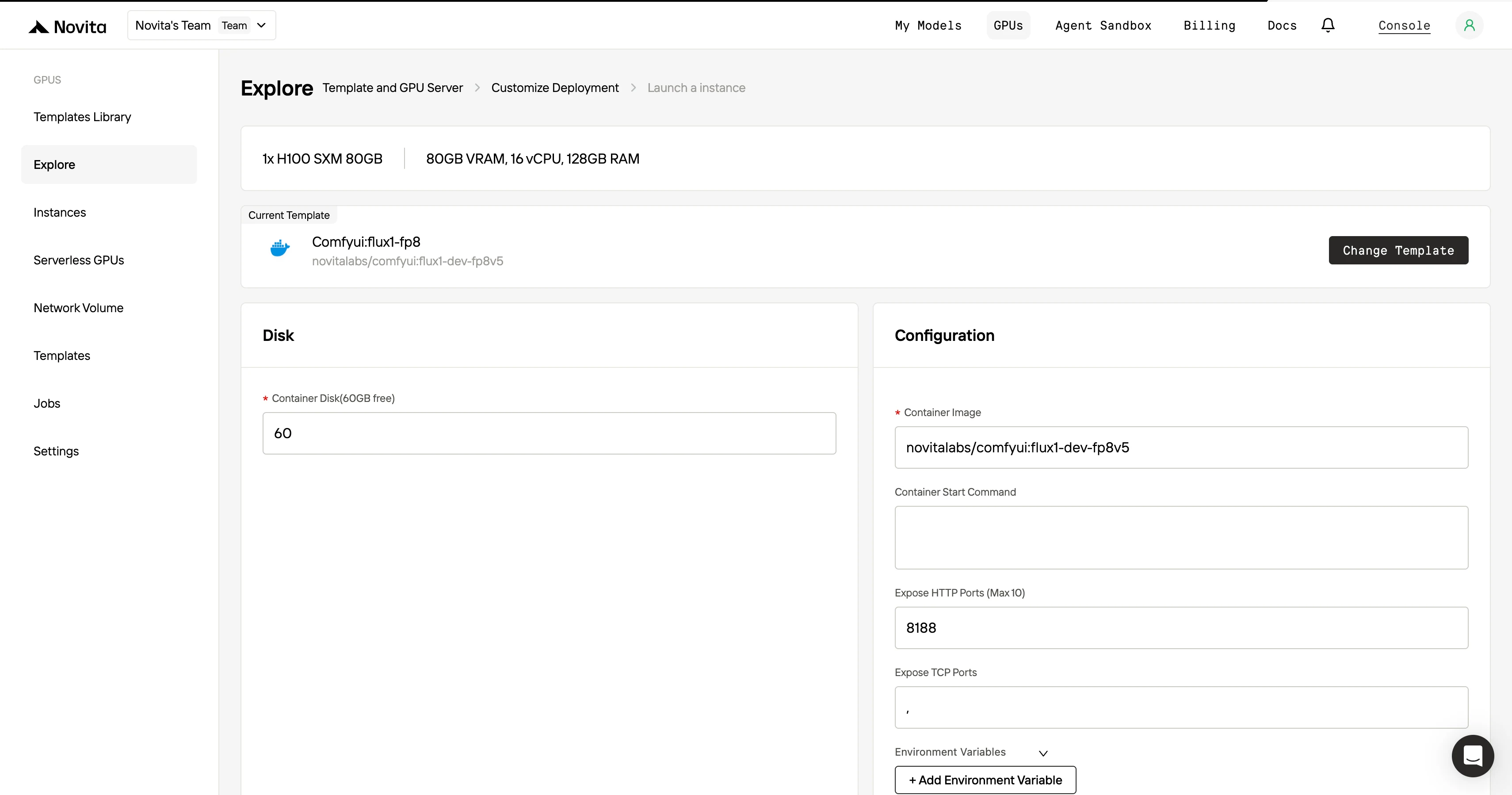
ステップ3:デプロイをカスタマイズ
テンプレートとGPUを選択した後、オペレーティングシステムのバージョン(CUDA 11.8など)などのパラメータを調整してデプロイ設定をカスタマイズします。その他の構成も調整して、プロジェクトの特定の要件に環境を適合させることができます。
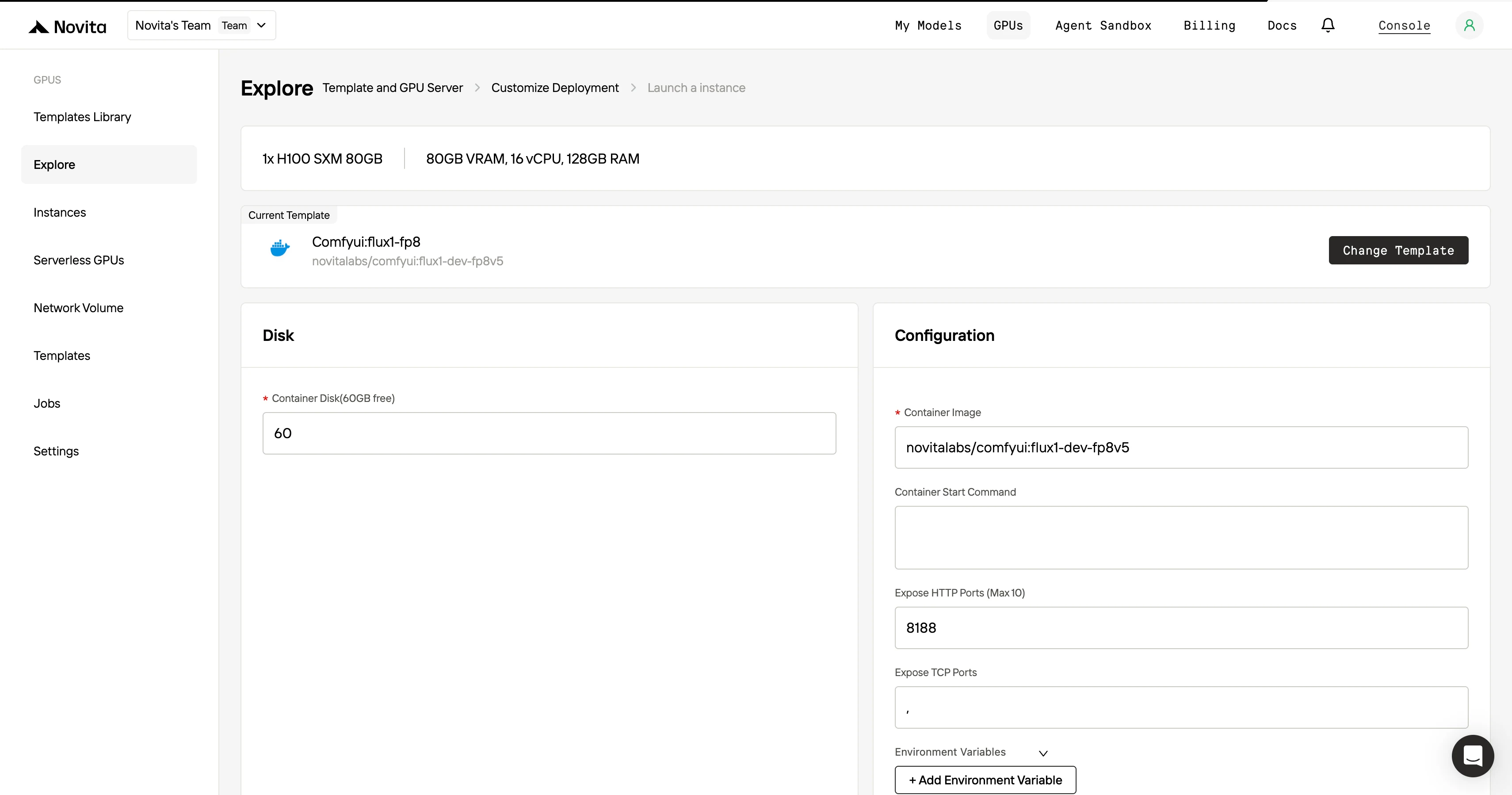
ステップ4:インスタンスを起動
テンプレートとデプロイ設定を確定したら、「Launch Instance」をクリックしてGPUインスタンスをセットアップします。これにより環境のセットアップが開始され、AIタスクにGPUリソースを使用できるようになります。
効率性と使いやすさを重視するなら、APIを選びましょう!
| **クラウドGPUの利点 ** | ** 残る課題 ** | APIがどのように解決するか |
|---|---|---|
| コスト効率と初期投資ゼロ | 手動でのセットアップとリソース管理は依然としてユーザーにとって時間がかかる可能性がある。 | APIはリソースプロビジョニングとジョブ送信を自動化し、人的労力とミスを削減する。 |
| 拡張性とオンデマンドアクセス | リソースの拡張には多くの場合、手動による介入や高度な設定が必要。 | APIはプログラムによる即時スケーリングと既存ワークフローとの統合を可能にする。 |
| ハードウェアのセットアップやメンテナンス不要 | ユーザーは依然として環境の構成や依存関係の管理が必要な場合がある。 | APIは事前構成された環境と簡単なデプロイを提供し、ほとんどのセットアップ手順を排除する。 |
デプロイAPIガイド
Novita AIはAnthropic APIを統合し、Claude Code でkimi k2を使用可能にし、多くの業界プロバイダーを凌駕しています。また、**131Kコンテキスト **、**131K最大出力 、2.01秒レイテンシ 、11.06 TPSスループット ** のAPIを提供し、コストは入力$0.57、 出力$2.30で、Kimi K2のコードエージェント可能性を最大限に引き出す強力なサポートを実現しています。
Novita AI
ステップ1:ログインしてモデルライブラリにアクセス
アカウントにログインし、Model Library ボタンをクリックします。

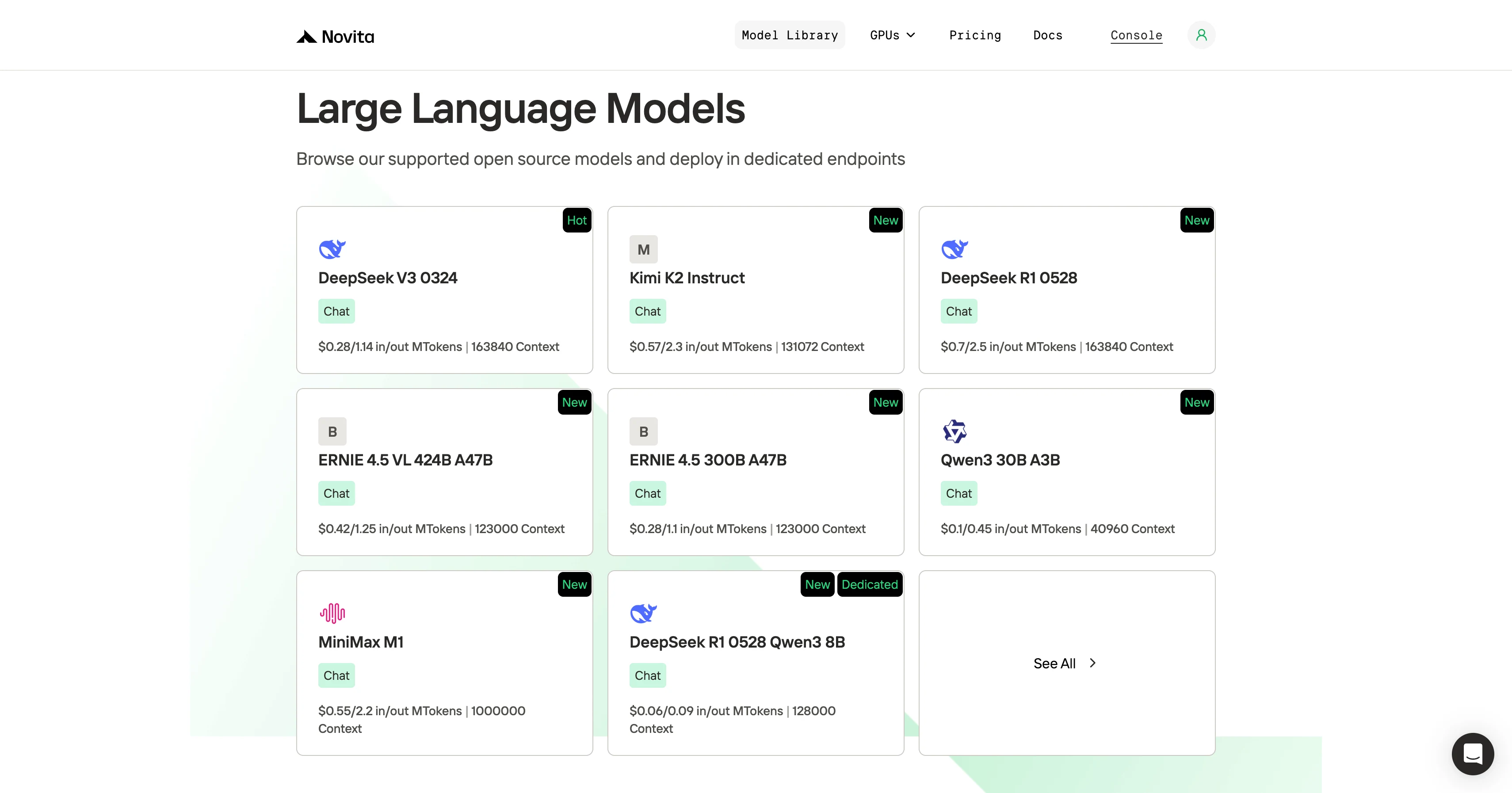
ステップ2:モデルを選択
利用可能なオプションから、ニーズに合ったモデルを選択します。
ステップ3:無料トライアルを開始
無料トライアルを開始して、選択したモデルの機能を試してみましょう。
ステップ4:APIキーを取得
APIで認証するために、新しいAPIキーを提供します。「Settings」ページに移動し、画像の指示に従ってAPIキーをコピーします。

ステップ5:APIをインストール
プログラミング言語に固有のパッケージマネージャーを使用してAPIをインストールします。
インストール後、必要なライブラリを開発環境にインポートします。APIキーを使用してAPIを初期化し、Novita AI LLMとの対話を開始します。以下は、Pythonユーザー向けのチャット補完APIの使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_1g0vYAKH0Oir6vI6y4PZIGyFLVvuJiJDx0jZiEeYivQFmDr15mi83mWi-_bdrs0C-Q2hk281SCn1f4oUB49loQ==",
)
model = "moonshotai/kimi-k2-instruct"
stream = True # または False
max_tokens = 65536
system_content = "役立つアシスタントになってください。"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "こんにちは!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
結論:Kimi K2はゲームチェンジャーですが、ローカルで実行するのは、よほど強力なハードウェアがない限り難しいです。Novita AIのようなクラウドGPUサービスを使えば、より簡単に(そして安価に)始められ、話題の真価を体験できます。
よくある質問
なぜKimi K2はAIエージェントの間でそんなに人気なのですか?
Kimi K2の高度なエージェント機能、広範なマルチドメイントレーニング、継続的な改善により、インテリジェントで適応性のあるツールを必要とする開発者にとって際立った選択肢となっています。そのオープンソースの性質と強力なコミュニティサポートが人気をさらに後押ししています。
自宅のサーバーでKimi K2を実行できますか?
技術的には可能ですが、Kimi K2をローカルで実行するには、非常に強力なGPUと大容量のVRAMが必要であり、ほとんどのホームセットアップでは手が届かないリソースです。ほとんどのユーザーにとって、クラウドGPUプラットフォームの方がはるかにアクセスしやすく、費用対効果の高い代替手段です。
Novita AI のようなクラウドGPUサービスがKimi K2にとって良い選択肢となる理由は?
クラウドGPUサービスは、高額なハードウェア投資、継続的なメンテナンス、エネルギー費用を排除します。従量課金制の柔軟性と即時の拡張性により、ローカルデプロイに比べてはるかに低いコストと複雑さでKimi K2を試すことができます。
Novita AI は、開発者がシンプルなAPIを使用してAIモデルを簡単にデプロイできるAIクラウドプラットフォームであり、手頃な価格で信頼性の高いGPUクラウドを提供して構築とスケーリングを実現します。



