

Kimi K2 est partout en ce moment : les gens adorent son intelligence et sa polyvalence, surtout ses capacités d’agent exceptionnelles. Toutes ces nouvelles fonctionnalités font parler tout le monde, et soyons honnêtes : beaucoup d’entre nous se demandent s’ils peuvent exécuter Kimi K2 à la maison, et de combien de VRAM vous auriez réellement besoin pour y parvenir.
Exploration des besoins en VRAM de Kimi K2
Kimi K2 est le dernier modèle développé par Moonshot AI, réputé pour ses capacités d’agent avancées. Ses capacités sont alimentées par l’optimiseur MuonClip, qui intègre des techniques avancées de résolution d’instabilité. L’agent est entraîné via des scénarios simulés d’utilisation d’outils multi-tours couvrant des centaines de domaines et des milliers d’outils, filtrés par des évaluateurs basés sur des LLM suivant des grilles d’évaluation spécifiques aux tâches. Pour l’apprentissage par renforcement, Kimi K2 utilise des signaux de récompense standard pour les tâches vérifiables comme les mathématiques et le codage, tandis qu’il s’appuie sur des auto-évaluations basées sur des grilles pour les tâches non vérifiables comme la rédaction de rapports. L’apprentissage continu sur politique garantit une amélioration continue et un jugement renforcé.
De Moonshot AI
Exigences matérielles détaillées
En tant que plus grand modèle open-source, Kimi K2 possède 1 billion de paramètres totaux, dont 32 milliards activés à tout moment. Cette échelle immense nécessite des ressources GPU substantielles pour fonctionner localement. Vous trouverez plus de détails dans les tableaux suivants, issus de Apx.
Modèles en pleine précision
| Variante du modèle | VRAM requise (Go) | Configuration GPU minimale |
|---|---|---|
| Kimi K2-Base | 2 401,52 | H100/A100 80 Go (x32) |
| Kimi K2-Instruct | 2 401,52 | H100/A100 80 Go (x32) |
| Kimi-VL-A3B | 51,87 | A100/H100 80 Go (x1) |
| Kimi-Dev-72B | 177,27 | A100/H100 80 Go (x3) |
Modèles quantifiés Q4 (VRAM réduite, accessibilité élargie)
| Variante du modèle | VRAM requise (Go) | Configuration GPU minimale |
|---|---|---|
| Kimi K2-Base (Q4) | 632,61 | A100/H100 80 Go (x8) |
| Kimi K2-Instruct (Q4) | 632,61 | A100/H100 80 Go (x8) |
| Kimi-VL-A3B (Q4) | 15,56 | RTX 4080 (16 Go) ou RTX 3090/4090 (24 Go) |
| Kimi-Dev-72B (Q4) | 50 | RTX 6000 Ada (48 Go) (x2) ou A100 80 Go (x1) |
Comparaison des besoins en VRAM avec d’autres modèles
| Nom du modèle | Précision / Contexte | VRAM requise | Configuration GPU minimale |
|---|---|---|---|
| DeepSeek R1 671B | FP16 | 1 421,82 Go | 24 × H100 (80 Go) 8 × H200 SXM (141 Go) |
| DeepSeek V3 0324 | FP16 | 1 425,02 Go | 24 × H100 (80 Go) |
| Llama 4 Maverick | FP16 / contexte 128K | 938,1 Go | 12 × H100 (80 Go) |
Cependant, malgré ces améliorations, les coûts de déploiement globaux restent élevés en raison du besoin de matériel avancé, des dépenses d’électricité continues et du personnel spécialisé pour la maintenance et l’optimisation.
Comment sélectionner un GPU répondant aux besoins en VRAM de Kimi K2
| Attribut | Impacts |
|---|---|
| Architecture | Fonctionnalités, efficacité, compatibilité |
| Cœurs CUDA/Tensor/RT | Vitesse d’entraînement/inférence du modèle, graphiques |
| VRAM / Bande passante mémoire | Taille de modèle prise en charge, vitesse pour les grands volumes de données |
| FP8/FP16/FP32/FP64 | Précision, puissance et vitesse pour l’IA/la science |
| Puissance (TDP) | Électricité, refroidissement, planification de baie |
| NVLink/MIG/ECC | Évolutivité, fiabilité, utilisation multi-modèles |
| Meilleur pour | Pour quelles charges de travail le GPU excelle |
| Coût / Déploiement | Planification budgétaire, facilité d’accès |
Pour un modèle de 1 000 milliards de paramètres, concentrez-vous sur une VRAM maximale, une prise en charge NVLink solide et une utilisation efficace de l’énergie par performance. Cela minimise à la fois le coût et le temps d’inférence/d’entraînement.
GPU recommandés pour exécuter Kimi K2
| Attribut | H100 (SXM) | B200 |
|---|---|---|
| VRAM | 80 Go / 98 Go HBM3 | 180 Go HBM3e |
| Bande passante mémoire | 3,9 To/s | 8 To/s par GPU |
| NVLink | Oui (NVLink 4.0/NVSwitch) | Oui (NVLink / NVSwitch 5e génération) |
| Perf. FP8 | 3,958 PFLOPS (dense) | 9 PFLOPS |
| Support PCIe | SXM utilise NVLink, pas PCIe | NVLink uniquement (NVL72) |
| Puissance (TDP) | 700 W (SXM) | 1 000 W |
| ECC | Oui | Oui |
| MIG | Oui | Oui |
Prix des GPU recommandés pour exécuter Kimi K2

Découvrez d’autres prix de GPU cloud
Cependant, exécuter Kimi K2 sur votre propre matériel implique une charge financière substantielle. Existe-t-il donc un moyen plus rentable d’exploiter les capacités de Kimi K2 ?
Pour les petits développeurs, louer des GPU dans le cloud peut être plus rentable
En substance, les solutions de GPU cloud comme Novita AI offrent un moyen rentable, flexible et sans tracas d’accéder à une puissance de calcul de premier ordre, vous permettant d’innover plus rapidement, de réduire les frais généraux opérationnels et de rester en tête dans le monde en évolution rapide de l’IA.
Le prix le plus bas - Novita AI
| Fournisseur | Type de GPU | Prix (USD/h) |
|---|---|---|
| Novita AI | H100 SXM 80 Go | 2,56 $ |
| Lambda | H100 SXM 80 Go | 3,29 $ |
| RunPod | H100 SXM 80 Go | 3,20 $ |
Défis techniques pour les serveurs domestiques
- Coûts matériels initiaux élevés et maintenance continue
- Difficulté à adapter les ressources pour des charges de travail fluctuantes
- Configuration et installation matérielles longues
- Accès limité aux dernières technologies GPU
Comment le GPU cloud peut résoudre le problème
- Rentabilité et aucun investissement initial
L’achat de GPU hautes performances pour un usage local peut nécessiter des dizaines de milliers de dollars de dépenses initiales, plus des coûts d’infrastructure continus pour l’électricité, le refroidissement et l’espace physique. Avec les services de GPU cloud, vous évitez complètement ces gros investissements. Le modèle de paiement à l’usage signifie que vous ne payez que pour les heures GPU que vous utilisez réellement. - Évolutivité et accès à la demande
Les configurations GPU locales ont généralement une capacité fixe et ne peuvent pas facilement s’adapter aux pics de demande ou aux nouvelles exigences de projet. En revanche, les plateformes cloud vous permettent d’ajuster instantanément vos ressources GPU. - Aucune configuration ou maintenance matérielle
La gestion locale des GPU implique souvent une installation matérielle complexe, une configuration, des mises à jour de pilotes et une maintenance de routine. Les plateformes GPU cloud gèrent toute l’infrastructure pour vous, y compris la fiabilité du matériel, le refroidissement, l’alimentation électrique et la compatibilité système.
Comment accéder à Kimi K2 sur un GPU cloud comme Novita AI ?
Étape 1 : Créer un compte
Si vous êtes nouveau chez Novita AI, commencez par créer un compte sur notre site Web. Une fois inscrit, rendez-vous dans l’onglet « GPUs » pour explorer les ressources disponibles et commencer votre aventure.

Essayez les GPU haute performance de Novita AI
Étape 2 : Explorer les modèles et les serveurs GPU
Commencez par sélectionner un modèle qui correspond à vos besoins de projet, comme PyTorch, TensorFlow ou CUDA. Choisissez la version qui répond à vos exigences, par exemple PyTorch 2.2.1 ou CUDA 11.8.0. Ensuite, sélectionnez la configuration du serveur GPU A100, qui offre des performances puissantes pour gérer des charges de travail exigeantes avec une VRAM, une RAM et une capacité de disque importantes.

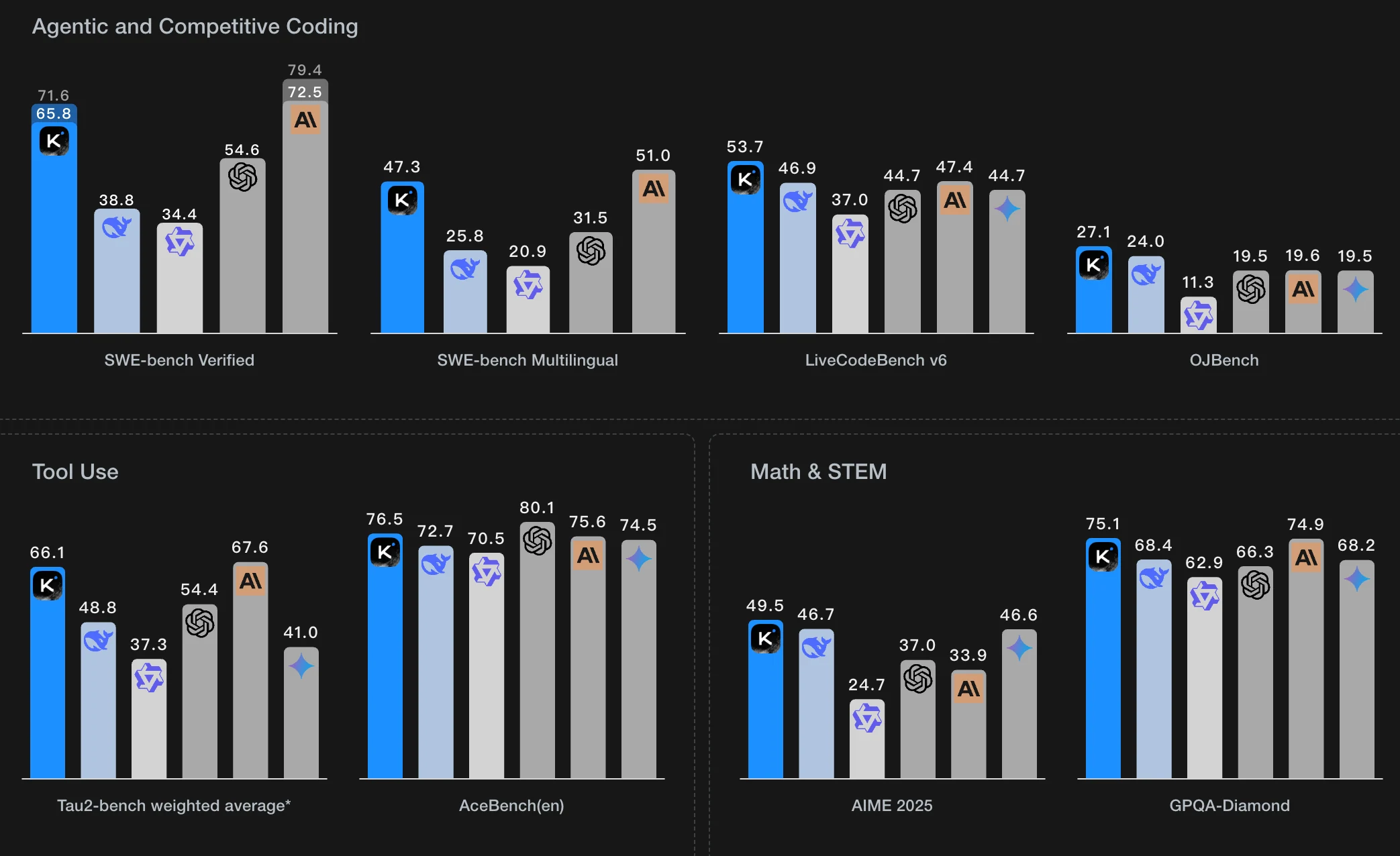
Étape 3 : Personnaliser votre déploiement
Après avoir sélectionné un modèle et un GPU, personnalisez les paramètres de déploiement en ajustant des paramètres comme la version du système d’exploitation (par exemple CUDA 11.8). Vous pouvez également modifier d’autres configurations pour adapter l’environnement aux exigences spécifiques de votre projet.
Étape 4 : Lancer une instance
Une fois que vous avez finalisé le modèle et les paramètres de déploiement, cliquez sur « Lancer l’instance » pour configurer votre instance GPU. Cela démarrera la configuration de l’environnement, vous permettant de commencer à utiliser les ressources GPU pour vos tâches d’IA.
Pour l’efficacité et la facilité d’utilisation, choisissez l’API !
| Avantage du GPU cloud | Défi restant | Comment l’API le résout |
|---|---|---|
| Rentabilité et aucun investissement initial | La configuration manuelle et la gestion des ressources peuvent encore prendre du temps pour les utilisateurs. | Les API automatisent le provisionnement des ressources et la soumission des tâches, réduisant l’effort humain et les erreurs. |
| Évolutivité et accès à la demande | L’adaptation des ressources nécessite souvent une intervention manuelle ou une configuration avancée. | Les API permettent une mise à l’échelle programmatique et instantanée ainsi qu’une intégration avec vos workflows existants. |
| Aucune configuration ou maintenance matérielle | Les utilisateurs peuvent encore devoir configurer des environnements ou gérer les dépendances. | Les API offrent des environnements préconfigurés et un déploiement facile, éliminant la plupart des étapes de configuration. |
Guide de déploiement de l’API
Novita AI intègre l’API Anthropic pour utiliser kimi k2 dans Claude Code
surpassant de nombreux fournisseurs du secteur.
Il fournit également des API avec un contexte de 131K, une sortie maximale de 131K, une latence de 2,01 s, un débit de 11,06 TPS, et des coûts de 0,57 $/entrée et 2,30 $/sortie, offrant un support solide pour maximiser le potentiel d’agent de code de Kimi K2.Novita AI
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Essayez Kimi K2 Instruct maintenant !
Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Étape 3 : Commencez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En entrant dans la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation. Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Ceci est un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_1g0vYAKH0Oir6vI6y4PZIGyFLVvuJiJDx0jZiEeYivQFmDr15mi83mWi-_bdrs0C-Q2hk281SCn1f4oUB49loQ==",
)
model = "moonshotai/kimi-k2-instruct"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
En résumé : Kimi K2 est un véritable game-changer, mais l’exécuter localement est difficile à moins d’avoir un matériel de folie. Les services de GPU cloud comme Novita AI facilitent (et rendent moins cher) le démarrage pour voir ce que tout ce battage médiatique signifie.
Foire aux questions
Pourquoi Kimi K2 est-il si populaire parmi les agents IA ?
Les capacités avancées d’agent de Kimi K2, son vaste entraînement multi-domaines et ses améliorations continues en ont fait un choix de premier plan pour les développeurs qui ont besoin d’outils intelligents et adaptables. Sa nature open-source et le soutien solide de la communauté n’ont fait qu’alimenter sa popularité.
Puis-je exécuter Kimi K2 sur mon serveur domestique ?
Bien que techniquement possible, exécuter Kimi K2 localement nécessite des GPU extrêmement puissants avec de grandes quantités de VRAM – des ressources généralement hors de portée pour la plupart des configurations domestiques. La plupart des utilisateurs trouvent que les plateformes de GPU cloud sont une alternative bien plus accessible et rentable.
Qu’est-ce qui fait des services de GPU cloud comme Novita AI une bonne option pour Kimi K2 ?
Les services de GPU cloud éliminent le besoin d’investissements matériels coûteux, de maintenance continue et de dépenses énergétiques. Grâce à la flexibilité du paiement à l’usage et à l’évolutivité instantanée, vous pouvez expérimenter avec Kimi K2 pour une fraction du coût et de la complexité d’un déploiement local.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA en utilisant notre API simple, tout en fournissant un cloud GPU abordable et fiable pour construire et faire évoluer.



