

Kimi K2가 지금 엄청난 인기를 끌고 있습니다. 많은 사람들이 이 모델이 얼마나 똑똑하고 다재다능한지, 특히 뛰어난 에이전트 기능에 매료되어 있습니다. 새로운 기능들이 모두의 입에 오르내리고 있으며, 솔직히 말해 우리 중 많은 사람들이 Kimi K2를 집에서 실행할 수 있을지, 그리고 실제로 얼마나 많은 VRAM이 필요한지 궁금해하고 있습니다.
Kimi K2 VRAM 요구 사항 살펴보기
Kimi K2는 Moonshot AI가 개발한 최신 모델로, 고급 에이전트 기능으로 유명합니다. 이 모델의 성능은 고급 불안정성 해결 기술을 통합한 MuonClip Optimizer를 기반으로 합니다. 에이전트는 수백 개의 도메인과 수천 개의 도구에 걸친 시뮬레이션된 다중 턴 도구 사용 시나리오를 통해 훈련되며, 데이터는 작업별 루브릭을 따르는 LLM 기반 평가자에 의해 필터링됩니다. 강화 학습의 경우 Kimi K2는 수학 및 코딩과 같은 검증 가능한 작업에는 표준 보상 신호를 사용하고, 보고서 작성과 같은 검증 불가능한 작업에는 루브릭 기반 자기 평가에 의존합니다. 지속적인 정책 학습(On-policy learning)을 통해 지속적인 개선과 향상된 판단력을 보장합니다.
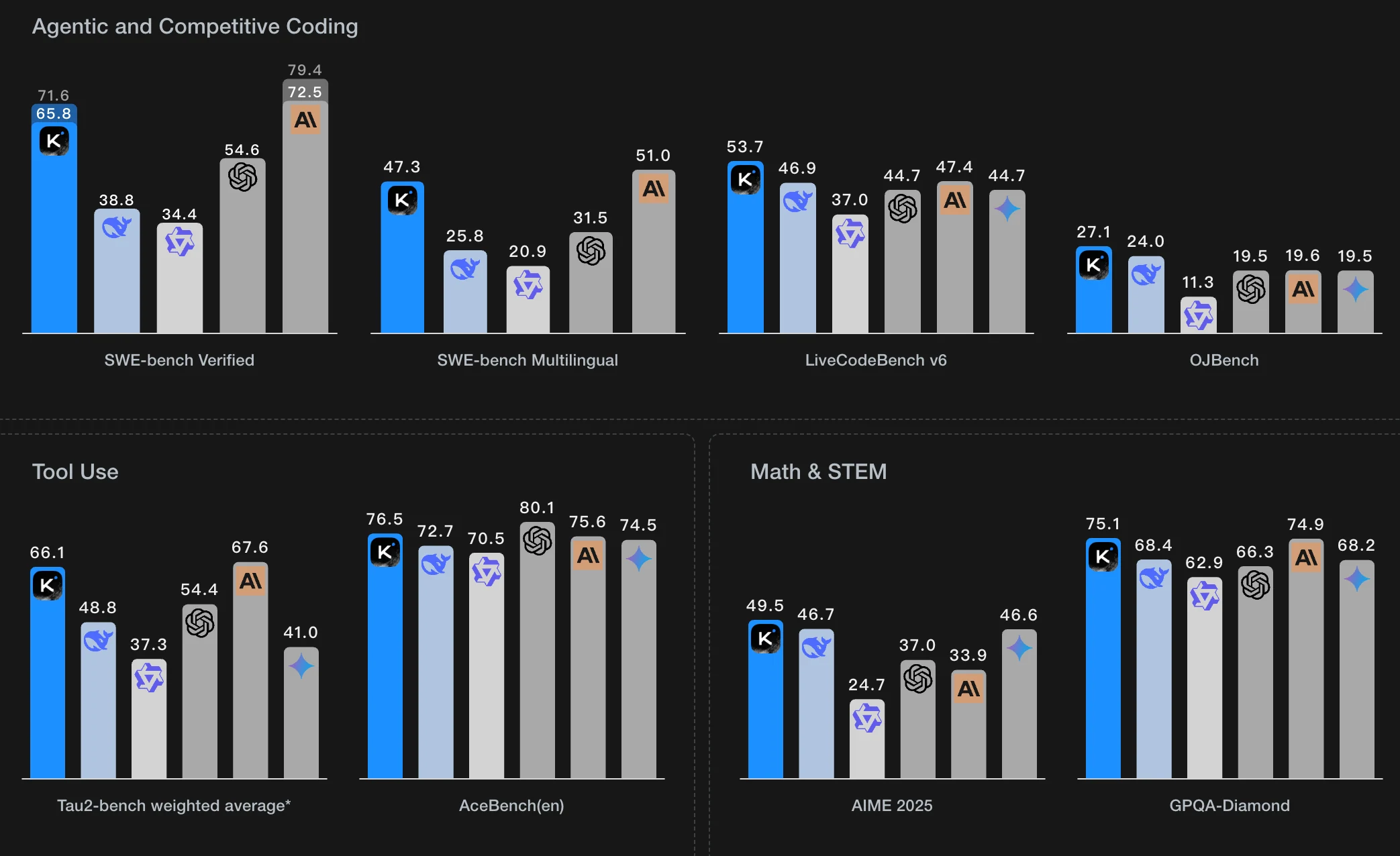
출처: Moonshot AI
상세 하드웨어 요구 사항
가장 큰 오픈소스 모델인 Kimi K2는 총 1조 개의 파라미터를 보유하며, 언제든지 320억 개의 파라미터가 활성화됩니다. 이 방대한 규모는 로컬에서 실행하기 위해 상당한 GPU 리소스를 필요로 합니다. 자세한 내용은 아래 표에서 확인할 수 있습니다(출처: Apx.).
전체 정밀도(Full-Precision) 모델
| 모델 변형 | 필요 VRAM (GB) | 최소 GPU 구성 |
|---|---|---|
| Kimi K2-Base | 2,401.52 | H100/A100 80GB (x32) |
| Kimi K2-Instruct | 2,401.52 | H100/A100 80GB (x32) |
| Kimi-VL-A3B | 51.87 | A100/H100 80GB (x1) |
| Kimi-Dev-72B | 177.27 | A100/H100 80GB (x3) |
Q4 양자화 모델 (VRAM 감소, 접근성 향상)
| 모델 변형 | 필요 VRAM (GB) | 최소 GPU 구성 |
|---|---|---|
| Kimi K2-Base (Q4) | 632.61 | A100/H100 80GB (x8) |
| Kimi K2-Instruct (Q4) | 632.61 | A100/H100 80GB (x8) |
| Kimi-VL-A3B (Q4) | 15.56 | RTX 4080 (16GB) 또는 RTX 3090/4090 (24GB) |
| Kimi-Dev-72B (Q4) | 50 | RTX 6000 Ada (48GB) (x2) 또는 A100 80GB (x1) |
다른 모델과 VRAM 요구 사항 비교
| 모델 이름 | 정밀도 / 컨텍스트 | 필요 VRAM | 최소 GPU 구성 |
|---|---|---|---|
| DeepSeek R1 671B | FP16 | 1,421.82 GB | 24 × H100 (80GB) 8 × H200 SXM (141GB) |
| DeepSeek V3 0324 | FP16 | 1,425.02 GB | 24 × H100 (80GB) |
| Llama 4 Maverick | FP16 / 128K 컨텍스트 | 938.1 GB | 12 × H100 (80GB) |
하지만 이러한 개선에도 불구하고, 고급 하드웨어, 지속적인 전기 비용, 유지보수 및 최적화를 위한 전문 인력의 필요성 때문에 전체 배포 비용은 여전히 높습니다.
Kimi K2 VRAM 요구 사항을 충족하는 GPU 선택 방법
| **속성 ** | ** 영향** |
|---|---|
| 아키텍처 | 기능, 효율성, 호환성 |
| CUDA/Tensor/RT 코어 | 모델 학습/추론 속도, 그래픽 |
| VRAM/메모리 대역폭 | 지원되는 모델 크기, 대용량 데이터 처리 속도 |
| FP8/FP16/FP32/FP64 | AI/과학을 위한 정밀도, 전력, 속도 |
| 전력(TDP) | 전기, 냉각, 랙 계획 |
| NVLink/MIG/ECC | 확장성, 안정성, 다중 모델 사용 |
| 최적 용도 | GPU가 뛰어난 워크로드 |
| 비용/배포 | 예산 계획, 접근 용이성 |
1조 개 파라미터 모델의 경우 최대 VRAM, 강력한 NVLink 지원, 성능 대비 효율적인 전력 사용 에 집중하세요. 이렇게 하면 비용과 추론/학습 시간을 모두 최소화할 수 있습니다.
Kimi K2 실행을 위한 권장 GPU
| 속성 | H100 (SXM) | B200 |
|---|---|---|
| VRAM | 80GB / 98GB HBM3 | 180 GB HBM3e |
| 메모리 대역폭 | 3.9 TB/s | GPU당 8 TB/s |
| NVLink | 지원 (NVLink 4.0/NVSwitch) | 지원 (NVLink / NVSwitch 5세대) |
| FP8 성능 | 3.958 PFLOPS (dense) | 9 PFLOPS |
| PCIe 지원 | SXM은 NVLink 사용, PCIe 미지원 | NVLink 전용 (NVL72) |
| 전력(TDP) | 700W (SXM) | 1,000W |
| ECC | 지원 | 지원 |
| MIG | 지원 | 지원 |
Kimi K2 실행을 위한 권장 GPU 가격

하지만 자체 하드웨어에서 Kimi K2를 실행하는 것은 상당한 재정적 부담을 수반합니다. 그렇다면 Kimi K2의 기능을 활용할 수 있는 더 비용 효율적인 방법은 없을까요?
소규모 개발자라면, 클라우드에서 GPU를 임대하는 것이 더 비용 효율적일 수 있습니다.
요컨대, Novita AI와 같은 클라우드 GPU 솔루션은 비용 효율적이고 유연하며 번거로움 없는 방식으로 최고 수준의 컴퓨팅 성능에 액세스할 수 있게 해줍니다. 이를 통해 더 빠르게 혁신하고, 운영 오버헤드를 줄이며, 빠르게 변화하는 AI 세계에서 앞서 나갈 수 있습니다.
최저 가격 - Novita AI
| 제공자 | GPU 유형 | 가격 (USD/시간) |
|---|---|---|
| Novita AI | H100 SXM 80GB | $2.56 |
| Lambda | H100 SXM 80GB | $3.29 |
| RunPod | H100 SXM 80GB | $3.20 |
홈 서버의 기술적 과제
- 높은 초기 하드웨어 비용 및 지속적인 유지보수
- 변동하는 워크로드에 맞춰 리소스를 확장하기 어려움
- 시간 소모적인 하드웨어 설정 및 구성
- 최신 GPU 기술에 대한 제한된 액세스
클라우드 GPU가 문제를 해결하는 방법
- 비용 효율성 및 초기 투자 불필요
로컬에서 사용할 고성능 GPU를 구매하려면 수만 달러의 초기 지출이 필요하고, 전력, 냉각, 물리적 공간에 대한 지속적인 인프라 비용도 발생합니다. 클라우드 GPU 서비스를 이용하면 이러한 큰 투자를 완전히 피할 수 있습니다. 사용한 만큼만 지불하는 종량제 가격 모델을 통해 실제로 사용한 GPU 시간에 대해서만 비용을 지불하면 됩니다. - 확장성 및 온디맨드 액세스
로컬 GPU 설정은 일반적으로 용량이 고정되어 있어 수요 급증이나 새로운 프로젝트 요구 사항을 쉽게 수용할 수 없습니다. 반면 클라우드 플랫폼을 사용하면 GPU 리소스를 즉시 확장할 수 있습니다. - 하드웨어 설정 또는 유지보수 불필요
로컬에서 GPU를 관리하려면 복잡한 하드웨어 설치, 구성, 드라이버 업데이트 및 정기적인 유지보수를 처리해야 하는 경우가 많습니다. 클라우드 GPU 플랫폼은 하드웨어 안정성, 냉각, 전원 공급 및 시스템 호환성을 포함한 모든 인프라 관리를 대신 처리합니다.
Novita AI와 같은 클라우드 GPU에서 Kimi K2에 액세스하는 방법?
1단계: 계정 등록
Novita AI가 처음이신가요? 웹사이트에서 계정을 만드세요. 등록이 완료되면 “GPUs” 탭으로 이동하여 사용 가능한 리소스를 살펴보고 여정을 시작하세요.

2단계: 템플릿 및 GPU 서버 탐색
먼저 프로젝트 요구 사항에 맞는 템플릿(예: PyTorch, TensorFlow, CUDA)을 선택하세요. 필요에 맞는 버전(예: PyTorch 2.2.1 또는 CUDA 11.8.0)을 선택합니다. 그런 다음, 강력한 성능과 충분한 VRAM, RAM, 디스크 용량을 제공하는 A100 GPU 서버 구성을 선택하세요.

3단계: 배포 설정 사용자 지정
템플릿과 GPU를 선택한 후, 운영 체제 버전(예: CUDA 11.8)과 같은 매개변수를 조정하여 배포 설정을 사용자 지정하세요. 프로젝트의 특정 요구 사항에 맞게 환경을 조정하기 위해 다른 구성도 수정할 수 있습니다.
4단계: 인스턴스 시작
템플릿과 배포 설정을 확정했으면 "Launch Instance"를 클릭하여 GPU 인스턴스를 설정하세요. 그러면 환경 설정이 시작되어 AI 작업에 GPU 리소스를 사용할 수 있게 됩니다.
효율성과 사용 편의성을 위해 API를 선택하세요!
| **클라우드 GPU 장점 ** | ** 남은 과제 ** | API가 해결하는 방법 |
|---|---|---|
| 비용 효율성 및 초기 투자 불필요 | 수동 설정 및 리소스 관리는 여전히 사용자에게 시간 소모적일 수 있음. | API는 리소스 프로비저닝과 작업 제출을 자동화하여 인적 노력과 실수를 줄입니다. |
| 확장성 및 온디맨드 액세스 | 리소스 확장에는 종종 수동 개입이나 고급 구성이 필요함. | API는 프로그래밍 방식의 즉각적인 확장을 가능하게 하며 기존 워크플로우와 통합됩니다. |
| 하드웨어 설정 또는 유지보수 불필요 | 사용자는 여전히 환경을 구성하거나 종속성을 관리해야 할 수 있음. | API는 사전 구성된 환경과 손쉬운 배포를 제공하여 대부분의 설정 단계를 제거합니다. |
배포 API 가이드
Novita AI는 Anthropic API를 통합하여 Claude Code에서 Kimi K2를 사용할 수 있게 하며,
많은 업계 제공업체를 능가합니다.
또한 **131K 컨텍스트 **, **131K 최대 출력 **, **2.01s 지연 시간 **, **11.06 TPS 처리량 ** 을 제공하는 API를 제공하며, 비용은 입력 $0.57/출력 $2.30 으로 Kimi K2의 코드 에이전트 잠재력을 최대한 활용할 수 있도록 강력하게 지원합니다.Novita AI
1단계: 로그인 및 모델 라이브러리 액세스
계정에 로그인하고 Model Library 버튼을 클릭하세요.

2단계: 모델 선택
사용 가능한 옵션을 살펴보고 필요에 맞는 모델을 선택하세요.
3단계: 무료 체험 시작
선택한 모델의 기능을 살펴보기 위해 무료 체험을 시작하세요.
4단계: API 키 받기
API 인증을 위해 새로운 API 키를 제공합니다. “Settings” 페이지로 이동하여 이미지에 표시된 대로 API 키를 복사하세요.

5단계: API 설치
프로그래밍 언어에 맞는 패키지 관리자를 사용하여 API를 설치하세요.
설치 후, 필요한 라이브러리를 개발 환경으로 가져옵니다. API 키로 API를 초기화하여 Novita AI LLM과 상호 작용을 시작하세요. 다음은 Python 사용자를 위한 채팅 완성 API 사용 예시입니다.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_1g0vYAKH0Oir6vI6y4PZIGyFLVvuJiJDx0jZiEeYivQFmDr15mi83mWi-_bdrs0C-Q2hk281SCn1f4oUB49loQ==",
)
model = "moonshotai/kimi-k2-instruct"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
결론: Kimi K2는 게임 체인저이지만, 엄청난 하드웨어가 없다면 로컬에서 실행하기가 어렵습니다. Novita AI와 같은 클라우드 GPU 서비스를 사용하면 훨씬 더 쉽게(그리고 저렴하게) 시작할 수 있으며, 모든 관심의 이유를 직접 경험할 수 있습니다.
자주 묻는 질문 (FAQ)
왜 Kimi K2가 AI 에이전트들 사이에서 그렇게 인기가 있나요?
Kimi K2의 고급 에이전트 기능, 방대한 다중 도메인 훈련, 지속적인 개선 덕분에 지능적이고 적응력이 뛰어난 도구가 필요한 개발자들에게 탁월한 선택이 되었습니다. 오픈소스 특성과 강력한 커뮤니티 지원이 그 인기를 더욱 높였습니다.
홈 서버에서 Kimi K2를 실행할 수 있나요?
기술적으로는 가능하지만, Kimi K2를 로컬에서 실행하려면 대용량 VRAM을 갖춘 매우 강력한 GPU가 필요하며, 이는 대부분의 홈 환경에서는 접근하기 어려운 리소스입니다. 대부분의 사용자는 클라우드 GPU 플랫폼이 훨씬 더 접근하기 쉽고 비용 효율적인 대안임을 알게 됩니다.
Novita AI와 같은 클라우드 GPU 서비스가 Kimi K2에 좋은 선택인 이유는 무엇인가요?
클라우드 GPU 서비스는 값비싼 하드웨어 투자, 지속적인 유지보수 및 에너지 비용을 없애줍니다. 종량제 유연성과 즉각적인 확장성을 통해 로컬 배포의 비용과 복잡성의 일부만으로 Kimi K2를 실험할 수 있습니다.
Novita AI는 개발자가 간단한 API를 사용하여 AI 모델을 쉽게 배포할 수 있도록 지원하는 AI 클라우드 플랫폼이며, 구축 및 확장을 위한 저렴하고 안정적인 GPU 클라우드도 제공합니다.



