

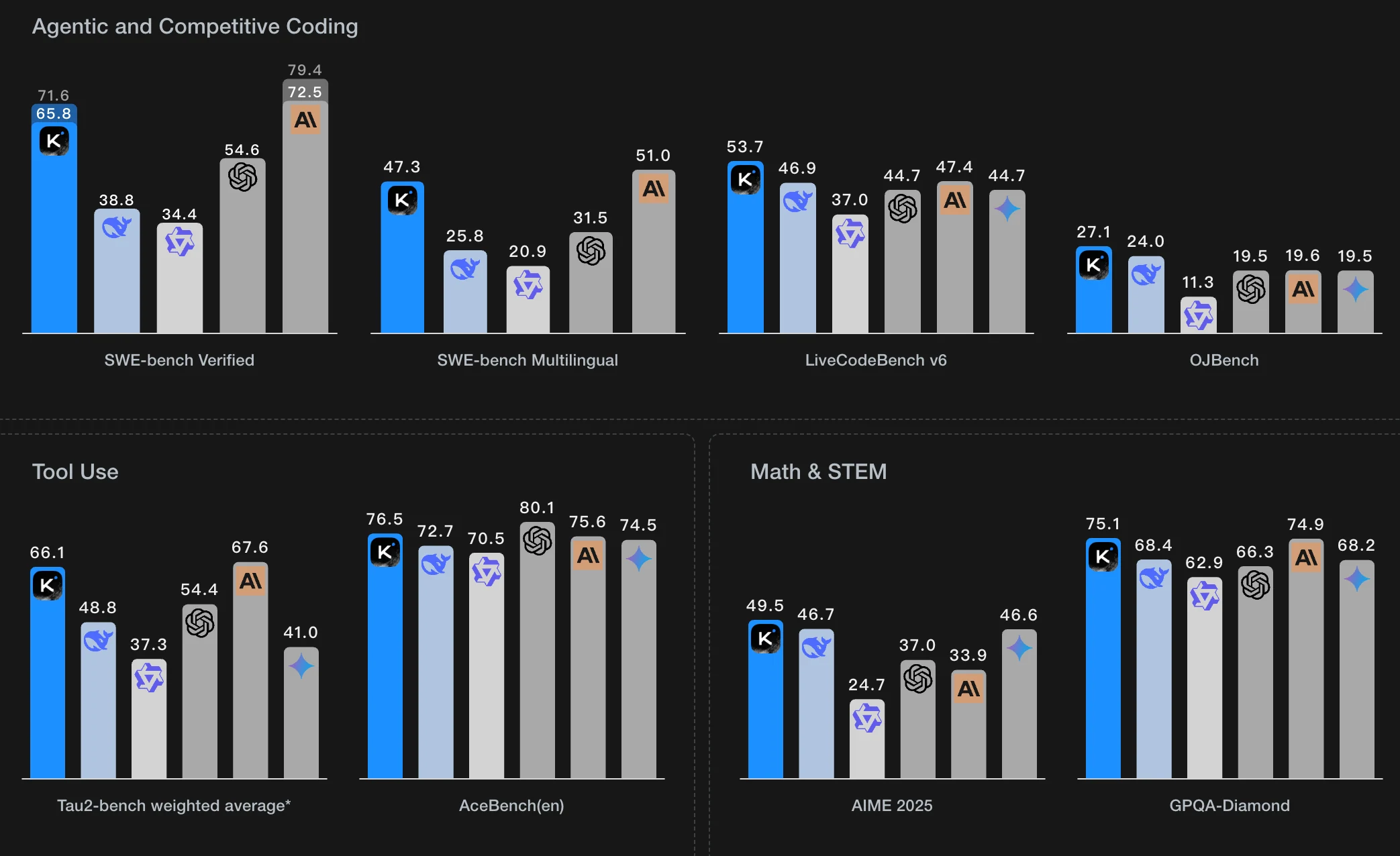
Kimi K2 現在隨處可見——大家都很喜歡它的聰明和多功能,尤其是它出色的智能代理能力。所有這些新功能都讓人津津樂道,老實說:很多人都好奇自己能不能在家裡跑 Kimi K2,以及實際需要多少 VRAM 才能做到。
探索 Kimi K2 的 VRAM 需求
Kimi K2 是 Moonshot AI 開發的最新模型,以其先進的智能代理能力聞名。它的能力由 MuonClip Optimizer 驅動,該最佳化器採用了先進的不穩定性解決技術。該代理透過模擬的多回合工具使用場景進行訓練,涵蓋數百個領域和數千種工具,並由基於 LLM 的評估器根據任務特定的評分標準過濾資料。在強化學習方面,Kimi K2 針對可驗證任務(如數學和程式碼)使用標準獎勵訊號,而對於不可驗證任務(如報告撰寫)則依賴基於評分標準的自我評估。持續的 on-policy 學習確保了持續改進和增強的判斷力。
來自 Moonshot AI
詳細硬體需求
作為最大的開源模型,Kimi K2 擁有 1 兆個總參數,其中 320 億個參數隨時處於啟動狀態。如此龐大的規模需要大量的 GPU 資源才能在本地運行。更多詳細資訊請參閱下表,資料來源為 Apx.
全精度模型
| 模型變體 | 所需 VRAM (GB) | 最低 GPU 配置 |
|---|---|---|
| Kimi K2-Base | 2,401.52 | H100/A100 80GB (x32) |
| Kimi K2-Instruct | 2,401.52 | H100/A100 80GB (x32) |
| Kimi-VL-A3B | 51.87 | A100/H100 80GB (x1) |
| Kimi-Dev-72B | 177.27 | A100/H100 80GB (x3) |
Q4 量化模型(降低 VRAM,更廣泛的可及性)
| 模型變體 | 所需 VRAM (GB) | 最低 GPU 配置 |
|---|---|---|
| Kimi K2-Base (Q4) | 632.61 | A100/H100 80GB (x8) |
| Kimi K2-Instruct (Q4) | 632.61 | A100/H100 80GB (x8) |
| Kimi-VL-A3B (Q4) | 15.56 | RTX 4080 (16GB) 或 RTX 3090/4090 (24GB) |
| Kimi-Dev-72B (Q4) | 50 | RTX 6000 Ada (48GB) (x2) 或 A100 80GB (x1) |
與其他模型的 VRAM 需求比較
| 模型名稱 | 精度 / 上下文 | 所需 VRAM | 最低 GPU 配置 |
|---|---|---|---|
| DeepSeek R1 671B | FP16 | 1,421.82 GB | 24 × H100 (80GB) 8 × H200 SXM (141GB) |
| DeepSeek V3 0324 | FP16 | 1,425.02 GB | 24 × H100 (80GB) |
| Llama 4 Maverick | FP16 / 128K 上下文 | 938.1 GB | 12 × H100 (80GB) |
然而,儘管有這些改進,由於需要先進的硬體、持續的電費以及專門的維護和最佳化人員,整體部署成本仍然很高。
如何選擇滿足 Kimi K2 VRAM 需求的 GPU
| **屬性 ** | ** 影響** |
|---|---|
| 架構 | 功能、效率、相容性 |
| CUDA/Tensor/RT 核心 | 模型訓練/推理速度、圖形處理 |
| VRAM/記憶體頻寬 | 支援的模型大小、大資料處理速度 |
| FP8/FP16/FP32/FP64 | AI/科學計算的精度、功耗與速度 |
| 功耗 (TDP) | 電力、散熱、機架規劃 |
| NVLink/MIG/ECC | 可擴展性、可靠性、多模型使用 |
| 最適合 | 該 GPU 擅長的工作負載 |
| 成本/部署 | 預算規劃、易於取得性 |
對於一個 1 兆參數的模型,重點關注最大 VRAM、強大的 NVLink 支援以及每個性能的能效。這可以最大程度地降低成本和推理/訓練時間。
推薦用於運行 Kimi K2 的 GPU
| 屬性 | H100 (SXM) | B200 |
|---|---|---|
| VRAM | 80GB / 98GB HBM3 | 180 GB HBM3e |
| 記憶體頻寬 | 3.9 TB/s | 8 TB/s 每 GPU |
| NVLink | 有 (NVLink 4.0/NVSwitch) | 有 (NVLink / NVSwitch 第 5 代) |
| FP8 性能 | 3.958 PFLOPS (密集) | 9 PFLOPS |
| PCIe 支援 | SXM 使用 NVLink,非 PCIe | 僅 NVLink (NVL72) |
| 功耗 (TDP) | 700W (SXM) | 1,000W |
| ECC | 有 | 有 |
| MIG | 有 | 有 |
推薦用於運行 Kimi K2 的 GPU 價格

然而,在自己的硬體上運行 Kimi K2 會帶來巨大的財務負擔。那麼,有沒有更具成本效益的方式來利用 Kimi K2 的能力呢?
對於小型開發者來說,在雲端租用 GPU 可能更具成本效益
本質上,像 Novita AI 這樣的雲端 GPU 解決方案提供了一種經濟高效、靈活且無憂的方式來獲取頂級計算能力——讓您能夠更快地創新、減少營運開支,並在快速發展的 AI 領域保持領先。
最低價格 - Novita AI
| 供應商 | GPU 類型 | 價格 (美金/小時) |
|---|---|---|
| Novita AI | H100 SXM 80GB | $2.56 |
| Lambda | H100 SXM 80GB | $3.29 |
| RunPod | H100 SXM 80GB | $3.20 |
家庭伺服器的技術挑戰
- 高昂的初始硬體成本和持續維護費用
- 難以根據波動的工作負載進行資源擴展
- 耗時的硬體設定和配置
- 難以獲得最新的 GPU 技術
雲端 GPU 如何解決問題
- 成本效益且無需前期投資
購買高效能 GPU 在本地使用可能需要數萬美元的初始支出,再加上電力、冷卻和物理空間的持續基礎設施成本。使用雲端 GPU 服務,您可以完全避免這些巨額投資。按需付費的定價模式意味著您只需為實際使用的 GPU 時數付費。 - 可擴展性和按需存取
本地 GPU 設置通常容量固定,難以應對需求高峰或新專案要求。相比之下,雲端平台允許您即時擴展 GPU 資源。 - 無需硬體設定或維護
在本地管理 GPU 通常涉及複雜的硬體安裝、配置、驅動程式更新和例行維護。雲端 GPU 平台為您處理所有基礎設施管理,包括硬體可靠性、散熱、電源供應和系統相容性。
如何在 Novita AI 等雲端 GPU 上使用 Kimi K2?
步驟 1:註冊帳號
如果您是 Novita AI 的新用戶,請先在我們的網站上建立帳號。註冊完成後,前往「GPU」標籤頁探索可用資源並開始使用。

步驟 2:探索模板和 GPU 伺服器
首先選擇符合您專案需求的模板,例如 PyTorch、TensorFlow 或 CUDA。選擇適合的版本,例如 PyTorch 2.2.1 或 CUDA 11.8.0。然後選擇 A100 GPU 伺服器配置,該配置提供強大的效能,以足夠的 VRAM、RAM 和磁碟容量處理高要求工作負載。

步驟 3:自訂部署
選擇模板和 GPU 後,透過調整作業系統版本(例如 CUDA 11.8)等參數來自訂部署設定。您也可以調整其他配置,以針對專案的特定需求進行環境最佳化。
步驟 4:啟動實例
最終確定模板和部署設定後,按一下「Launch Instance」來設定您的 GPU 實例。這將啟動環境設置,讓您開始將 GPU 資源用於 AI 任務。
追求效率與易用性,請選擇 API!
| **雲端 GPU 優勢 ** | ** 仍然存在的挑戰 ** | API 如何解決 |
|---|---|---|
| 成本效益與無前期投資 | 手動設定和資源管理仍可能耗費使用者時間。 | API 自動化資源配置和任務提交,減少人力和錯誤。 |
| 可擴展性和按需存取 | 擴展資源通常需要手動介入或進階配置。 | API 允許程式化、即時擴展,並與現有工作流程整合。 |
| 無需硬體設定或維護 | 使用者可能仍需要配置環境或管理相依項目。 | API 提供預先配置的環境和簡易部署,省去大部分設定步驟。 |
部署 API 指南
Novita AI 整合了 Anthropic API,可在 Claude Code 中使用 kimi k2,超越許多業界供應商。
它還提供 **131K 上下文 **、**131K 最大輸出 **、**2.01 秒延遲 **、**11.06 TPS 吞吐量 **,成本為 **$0.57/輸入 ** 和 $2.30/輸出,為最大化 Kimi K2 的程式碼代理潛力提供強大支援。Novita AI
步驟 1:登入並存取模型庫
登入您的帳號,然後按一下 Model Library 按鈕。

步驟 2:選擇您的模型
瀏覽可用選項,選擇符合您需求的模型。
步驟 3:開始免費試用
開始免費試用,探索所選模型的能力。
步驟 4:取得您的 API 金鑰
為了進行 API 驗證,我們將為您提供一個新的 API 金鑰。進入「Settings」頁面,您可以依照圖示所示複製 API 金鑰。

步驟 5:安裝 API
使用您程式語言專用的套件管理器安裝 API。
安裝完成後,將必要的函式庫匯入到您的開發環境中。使用您的 API 金鑰初始化 API,開始與 Novita AI LLM 互動。以下是 Python 使用者使用 chat completions API 的範例。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_1g0vYAKH0Oir6vI6y4PZIGyFLVvuJiJDx0jZiEeYivQFmDr15mi83mWi-_bdrs0C-Q2hk281SCn1f4oUB49loQ==",
)
model = "moonshotai/kimi-k2-instruct"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
總結:Kimi K2 是一款顛覆性的模型,但除非您擁有瘋狂的硬體,否則在本地運行相當困難。像 Novita AI 這樣的雲端 GPU 服務讓您能更輕鬆(也更便宜)地入門,親身體驗這股熱潮。
常見問題
為什麼 Kimi K2 在 AI 代理中如此受歡迎?
Kimi K2 的先進智能代理能力、廣泛的多領域訓練以及持續的改進,使其成為需要智慧且可適應工具的開發者的首選。其開源性質和強大的社群支援進一步推動了它的受歡迎程度。
我可以在家庭伺服器上運行 Kimi K2 嗎?
雖然理論上可行,但在本地運行 Kimi K2 需要極其強大的 GPU 和大量 VRAM——這些資源通常超出大多數家庭設配置的能力範圍。大多數使用者會發現雲端 GPU 平台是更可行且具成本效益的替代方案。
像 Novita AI 這樣的雲端 GPU 服務為何是 Kimi K2 的好選擇?
雲端 GPU 服務消除了昂貴的硬體投資、持續維護和能源費用的需求。憑藉按需付費的靈活性和即時可擴展性,您可以用遠低於本地部署的成本和複雜度來嘗試 Kimi K2。
Novita AI 是一個 AI 雲端平台,為開發者提供使用簡單 API 部署 AI 模型的簡便方式,同時提供經濟實惠且可靠的 GPU 雲端,用於建構和擴展專案。



