

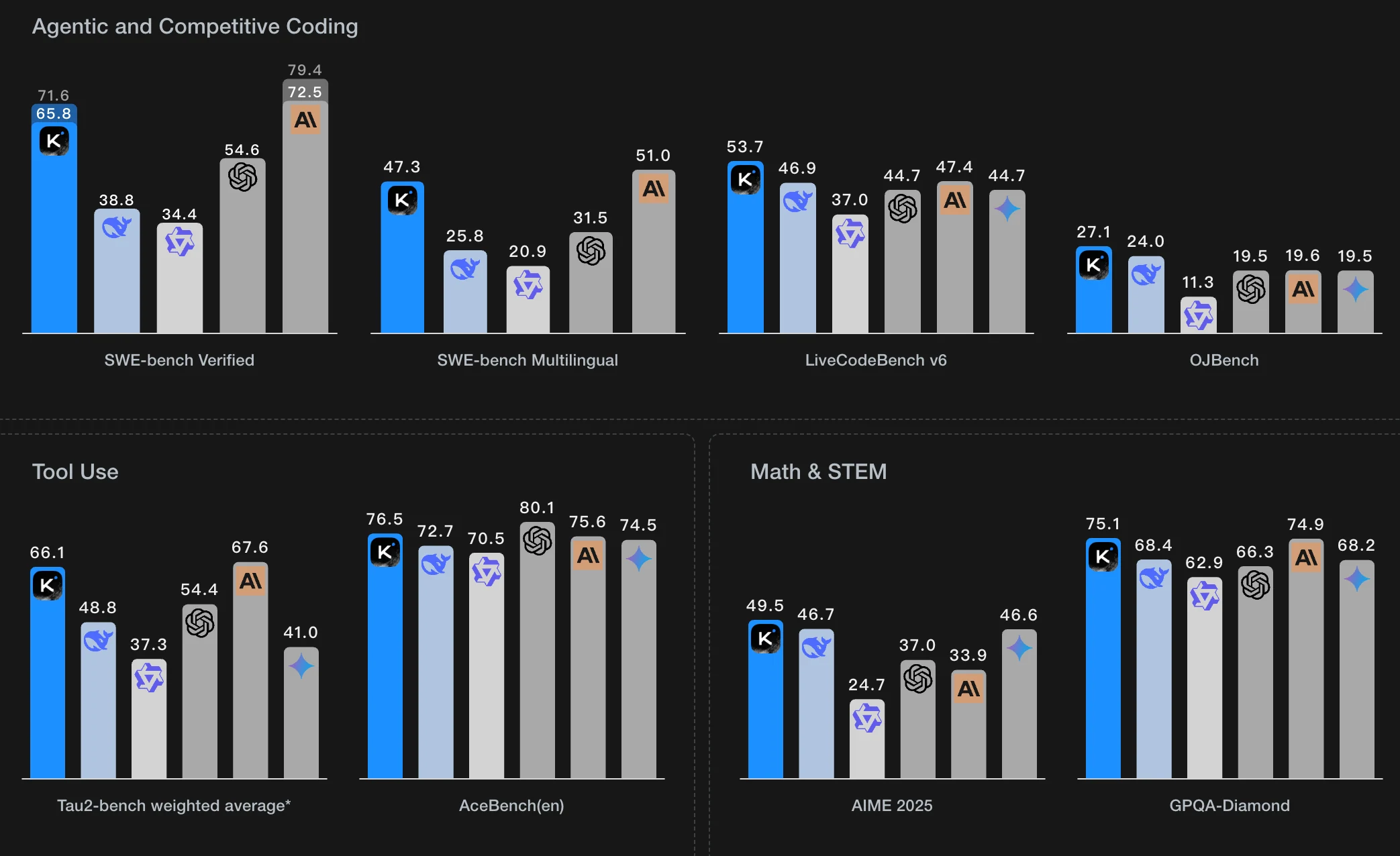
Kimi K2 está en todas partes ahora: la gente ama lo inteligente y versátil que es, especialmente por sus destacadas capacidades de agente. Todas estas nuevas funciones tienen a todos hablando, y seamos sinceros: muchos tenemos curiosidad por saber si podemos ejecutar Kimi K2 en casa y cuánta VRAM necesitaríamos realmente para lograrlo.
Explorando los requisitos de VRAM de Kimi K2
Kimi K2 es el modelo más reciente desarrollado por Moonshot AI, reconocido por sus avanzadas capacidades de agente. Sus capacidades están impulsadas por el Optimizador MuonClip, que incorpora técnicas avanzadas de resolución de inestabilidades. El agente se entrena mediante escenarios simulados de uso de herramientas en múltiples turnos que abarcan cientos de dominios y miles de herramientas, con datos filtrados por evaluadores basados en LLM siguiendo rúbricas específicas de cada tarea. Para el aprendizaje por refuerzo, Kimi K2 utiliza señales de recompensa estándar para tareas verificables como matemáticas y codificación, mientras que se apoya en autoevaluaciones basadas en rúbricas para tareas no verificables como la redacción de informes. El aprendizaje continuo sobre la política asegura una mejora constante y un juicio mejorado.
De Moonshot AI
Requisitos detallados de hardware
Como el modelo de código abierto más grande, Kimi K2 cuenta con 1 billón de parámetros totales, de los cuales 32 mil millones se activan en cualquier momento. Esta escala inmensa requiere recursos GPU sustanciales para ejecutarse localmente. Puedes encontrar más detalles en las siguientes tablas, con fuente de Apx.
Modelos de precisión completa
| Variante del modelo | VRAM requerida (GB) | Configuración mínima de GPU |
|---|---|---|
| Kimi K2-Base | 2,401.52 | H100/A100 80GB (x32) |
| Kimi K2-Instruct | 2,401.52 | H100/A100 80GB (x32) |
| Kimi-VL-A3B | 51.87 | A100/H100 80GB (x1) |
| Kimi-Dev-72B | 177.27 | A100/H100 80GB (x3) |
Modelos cuantizados Q4 (VRAM reducida, mayor accesibilidad)
| Variante del modelo | VRAM requerida (GB) | Configuración mínima de GPU |
|---|---|---|
| Kimi K2-Base (Q4) | 632.61 | A100/H100 80GB (x8) |
| Kimi K2-Instruct (Q4) | 632.61 | A100/H100 80GB (x8) |
| Kimi-VL-A3B (Q4) | 15.56 | RTX 4080 (16GB) o RTX 3090/4090 (24GB) |
| Kimi-Dev-72B (Q4) | 50 | RTX 6000 Ada (48GB) (x2) o A100 80GB (x1) |
Comparación de requisitos de VRAM con otros modelos
| Nombre del modelo | Precisión / Contexto | VRAM requerida | Configuración mínima de GPU |
|---|---|---|---|
| DeepSeek R1 671B | FP16 | 1,421.82 GB | 24 × H100 (80GB) 8 × H200 SXM (141GB) |
| DeepSeek V3 0324 | FP16 | 1,425.02 GB | 24 × H100 (80GB) |
| Llama 4 Maverick | FP16 / contexto 128K | 938.1 GB | 12 × H100 (80GB) |
Sin embargo, a pesar de estas mejoras, los costos generales de implementación siguen siendo altos debido a la necesidad de hardware avanzado, gastos continuos de electricidad y personal especializado para el mantenimiento y la optimización.
Cómo seleccionar una GPU que cumpla con los requisitos de VRAM de Kimi K2
| Atributo | Impacta en |
|---|---|
| Arquitectura | Características, eficiencia, compatibilidad |
| Núcleos CUDA/Tensor/RT | Velocidad de entrenamiento/inferencia del modelo, gráficos |
| VRAM/Ancho de banda de memoria | Tamaño del modelo compatible, velocidad para grandes datos |
| FP8/FP16/FP32/FP64 | Precisión, potencia y velocidad para IA/ciencia |
| Potencia (TDP) | Electricidad, refrigeración, planificación de racks |
| NVLink/MIG/ECC | Escalabilidad, fiabilidad, uso multimodelo |
| Mejor para | Para qué cargas de trabajo destaca la GPU |
| Costo/Implementación | Planificación presupuestaria, facilidad de acceso |
Para un modelo de 1 billón de parámetros, céntrate en la máxima VRAM, un sólido soporte NVLink y un uso eficiente de la energía por rendimiento. Esto minimiza tanto el costo como el tiempo de inferencia/entrenamiento.
GPUs recomendadas para ejecutar Kimi K2
| Atributo | H100 (SXM) | B200 |
|---|---|---|
| VRAM | 80GB / 98GB HBM3 | 180 GB HBM3e |
| Ancho de banda de memoria | 3.9 TB/s | 8 TB/s por GPU |
| NVLink | Sí (NVLink 4.0/NVSwitch) | Sí (NVLink / NVSwitch 5.ª generación) |
| Rendimiento FP8 | 3.958 PFLOPS (denso) | 9 PFLOPS |
| Soporte PCIe | SXM usa NVLink, no PCIe | Solo NVLink (NVL72) |
| Potencia (TDP) | 700W (SXM) | 1,000W |
| ECC | Sí | Sí |
| MIG | Sí | Sí |
Precio de las GPUs recomendadas para ejecutar Kimi K2

Ver más precios de GPU en la nube
Sin embargo, ejecutar Kimi K2 en tu propio hardware conlleva una carga financiera considerable. Entonces, ¿existe una forma más rentable de aprovechar las capacidades de Kimi K2?
Para pequeños desarrolladores, alquilar GPUs en la nube puede ser más rentable
En esencia, las soluciones de GPU en la nube como Novita AI ofrecen una forma rentable, flexible y sin complicaciones de acceder a una potencia informática de primer nivel: te permiten innovar más rápido, reducir los gastos operativos y mantenerte a la vanguardia en el vertiginoso mundo de la IA.
El precio más bajo: Novita AI
| Proveedor | Tipo de GPU | Precio (USD/hora) |
|---|---|---|
| Novita AI | H100 SXM 80GB | $2.56 |
| Lambda | H100 SXM 80GB | $3.29 |
| RunPod | H100 SXM 80GB | $3.20 |
Desafíos técnicos para servidores domésticos
- Altos costos iniciales de hardware y mantenimiento continuo
- Dificultad para escalar recursos según cargas de trabajo fluctuantes
- Configuración e instalación de hardware que consumen mucho tiempo
- Acceso limitado a la tecnología GPU más reciente
¿Cómo puede la GPU en la nube resolver el problema?
- Rentabilidad y sin inversión inicial
Comprar GPUs de alto rendimiento para uso local puede requerir decenas de miles de dólares en gastos iniciales, más costos continuos de infraestructura para electricidad, refrigeración y espacio físico. Con los servicios de GPU en la nube, evitas por completo estas grandes inversiones. El modelo de pago por uso significa que solo pagas por las horas de GPU que realmente utilizas. - Escalabilidad y acceso bajo demanda
Las configuraciones locales de GPU suelen tener una capacidad fija y no pueden adaptarse fácilmente a picos de demanda o nuevos requisitos de proyectos. Por el contrario, las plataformas en la nube te permiten escalar tus recursos GPU al instante. - Sin configuración ni mantenimiento de hardware
Gestionar GPUs localmente a menudo implica lidiar con instalaciones complejas de hardware, configuración, actualizaciones de controladores y mantenimiento rutinario. Las plataformas de GPU en la nube gestionan toda la infraestructura por ti, incluyendo fiabilidad del hardware, refrigeración, suministro eléctrico y compatibilidad del sistema.
¿Cómo acceder a Kimi K2 en una GPU en la nube como Novita AI?
Paso 1: Registra una cuenta
Si eres nuevo en Novita AI, comienza creando una cuenta en nuestro sitio web. Una vez registrado, dirígete a la pestaña “GPUs” para explorar los recursos disponibles y comenzar tu viaje.

Prueba las GPUs de alto rendimiento de Novita AI
Paso 2: Explora plantillas y servidores GPU
Comienza seleccionando una plantilla que se ajuste a las necesidades de tu proyecto, como PyTorch, TensorFlow o CUDA. Elige la versión que cumpla con tus requisitos, por ejemplo, PyTorch 2.2.1 o CUDA 11.8.0. Luego, selecciona la configuración del servidor GPU A100, que ofrece un rendimiento potente para manejar cargas de trabajo exigentes con amplia VRAM, RAM y capacidad de disco.

Paso 3: Personaliza tu implementación
Después de seleccionar una plantilla y GPU, personaliza la configuración de tu implementación ajustando parámetros como la versión del sistema operativo (por ejemplo, CUDA 11.8). También puedes modificar otras configuraciones para adaptar el entorno a los requisitos específicos de tu proyecto.
Paso 4: Inicia una instancia
Una vez que hayas finalizado la plantilla y la configuración de implementación, haz clic en “Launch Instance” para configurar tu instancia de GPU. Esto iniciará la configuración del entorno, permitiéndote comenzar a usar los recursos de GPU para tus tareas de IA.
¡Por eficiencia y facilidad de uso, elige la API!
| Beneficio de GPU en la nube | Desafío restante | Cómo lo resuelve la API |
|---|---|---|
| Rentabilidad y sin inversión inicial | La configuración manual y la gestión de recursos aún pueden consumir tiempo para los usuarios. | Las API automatizan el aprovisionamiento de recursos y el envío de trabajos, reduciendo el esfuerzo humano y los errores. |
| Escalabilidad y acceso bajo demanda | Escalar recursos a menudo requiere intervención manual o configuración avanzada. | Las API permiten un escalado programático e instantáneo y la integración con tus flujos de trabajo existentes. |
| Sin configuración ni mantenimiento de hardware | Los usuarios aún pueden necesitar configurar entornos o gestionar dependencias. | Las API ofrecen entornos preconfigurados y una implementación sencilla, eliminando la mayoría de los pasos de configuración. |
Guía de implementación de la API
Novita AI integra la API de Anthropic para usar kimi k2 en Claude Code
superando a muchos proveedores de la industria.
También proporciona APIs con contexto de 131K, salida máxima de 131K, latencia de 2.01s, rendimiento de 11.06 TPS y costos de $0.57/entrada y $2.30/salida, ofreciendo un sólido soporte para maximizar el potencial del agente de código de Kimi K2.Novita AI
Paso 1: Inicia sesión y accede a la Biblioteca de Modelos
Inicia sesión en tu cuenta y haz clic en el botón Model Library.

¡Prueba Kimi K2 Instruct ahora!
Paso 2: Elige tu modelo
Navega por las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.
Paso 3: Comienza tu prueba gratuita
Inicia tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtén tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Entrando en la página “Settings”, puedes copiar la clave API como se indica en la imagen.

Paso 5: Instala la API
Instala la API utilizando el gestor de paquetes específico de tu lenguaje de programación.
Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para empezar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de chat completions para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_1g0vYAKH0Oir6vI6y4PZIGyFLVvuJiJDx0jZiEeYivQFmDr15mi83mWi-_bdrs0C-Q2hk281SCn1f4oUB49loQ==",
)
model = "moonshotai/kimi-k2-instruct"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
En resumen: Kimi K2 es un cambio de juego, pero ejecutarlo localmente es difícil a menos que tengas un hardware increíble. Los servicios de GPU en la nube como Novita AI facilitan (y abaratan) mucho empezar y ver de qué va todo este hype.
Preguntas frecuentes
¿Por qué Kimi K2 es tan popular entre los agentes de IA?
Las avanzadas capacidades de agente de Kimi K2, su vasto entrenamiento en múltiples dominios y las mejoras continuas lo han convertido en una opción destacada para los desarrolladores que necesitan herramientas inteligentes y adaptables. Su naturaleza de código abierto y el fuerte apoyo de la comunidad solo han aumentado su popularidad.
¿Puedo ejecutar Kimi K2 en mi servidor doméstico?
Aunque técnicamente es posible, ejecutar Kimi K2 localmente requiere GPUs extremadamente potentes con grandes cantidades de VRAM, recursos que generalmente están fuera del alcance de la mayoría de las configuraciones domésticas. La mayoría de los usuarios encuentran que las plataformas de GPU en la nube son una alternativa mucho más accesible y rentable.
¿Qué hace que los servicios de GPU en la nube como Novita AI sean una buena opción para Kimi K2?
Los servicios de GPU en la nube eliminan la necesidad de costosas inversiones en hardware, mantenimiento continuo y gastos de energía. Con la flexibilidad de pago por uso y la escalabilidad instantánea, puedes experimentar con Kimi K2 a una fracción del costo y la complejidad de la implementación local.
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA utilizando nuestra API simple, al mismo tiempo que proporciona una GPU en la nube asequible y fiable para construir y escalar.



