

특정 애플리케이션에 최적의 모델을 찾아 프로덕션에 배포하는 것은 어렵습니다. OpenAI나 Claude의 폐쇄형 옵션과 달리, 오픈 모델은 거의 호스팅되지 않습니다. 컴퓨팅, 지연 시간, 처리량 요구 사항을 직접 구성해야 하는 경우가 많습니다. 이러한 복잡성으로 인해 많은 개발자와 기업이 GPT-4나 Claude 같은 익숙한 범용 모델을 기본값으로 사용하게 됩니다. 하지만 가벼운 전문 모델과 강력한 범용 모델을 포함한 오픈 대안이 더 나은 성능, 더 빠른 응답, 더 낮은 비용을 제공할 수 있음에도 불구하고 말이죠. 이때 Novita가 등장합니다. Novita는 오픈소스 모델을 호스팅하며, 필요에 따라 특정 요구 사항에 맞게 구성하여 번거로움 없이 이러한 모델을 사용할 수 있도록 합니다.
모두가 GPT-4를 사용하는 이유는 무엇일까요?
AI 모델 환경은 빠르게 성장하고 있으며, 수백 개의 모델이 각각 고유한 강점과 약점을 가지고 있습니다. 하지만 오픈소스 모델의 성능이 향상되고 있음에도 불구하고, GPT-4x 시리즈, Claude 3x 시리즈 및 기타 폐쇄형 모델은 많은 팀의 기본 선택으로 남아 있습니다. 이 글에서는 폐쇄형 모델을 사용하는 것이 합리적인 때와 그렇지 않은 때, 그리고 Novita가 오픈소스 LLM을 폐쇄형 모델만큼 쉽게 배포할 수 있게 하는 방법을 분석합니다.
이러한 인기 있는 폐쇄형 모델은 호스팅되어 사용하기 쉽기 때문에 인프라, 설정, 배포에 대해 걱정할 필요가 없습니다. API를 호출하기만 하면 추론을 얻을 수 있습니다. 또한 이러한 모델은 광범위한 기능을 갖추고 있어 글쓰기, 추론, 코딩과 같은 다양한 범용 작업에서 좋은 성능을 발휘합니다. 그리고 널리 채택되었기 때문에 위험이 적은 옵션으로 인식됩니다.
…하지만 그代价은 무엇일까요?
폐쇄형 범용 모델을 기본값으로 사용하는 것이 가장 안전한 선택처럼 느껴질 수 있지만, 종종 숨겨진 비용이 발생합니다. 폐쇄형 모델에만 의존하면 Qwen이나 DeepSeek와 같은 강력한 오픈소스 대안을 사용할 수 없게 됩니다. 이러한 대안은 더 큰 제어권, 투명성, 장기적인 비용 효율성으로 비슷하거나 더 나은 결과를 제공합니다. 실제로 많은 팀이 실제로 사용하지 않는 규모와 기능에 대해 초과 지불을 하고, 100B+ 파라미터 모델이 필요하지 않은 작업에서 컴퓨팅과 에너지를 낭비하며 환경에 부정적인 영향을 미칩니다. 또한, 더 작거나 더 specialize된 모델이 뛰어난 틈새 작업에서는 일반 성능이 저하될 수 있습니다.
이제 많은 오픈 모델이 주요 작업에서 최고 수준의 폐쇄형 모델과 일치하거나 능가합니다:
- Kimi K2, DeepSeek R1, Qwen 3 235B A22B는 코딩 및 수학적 추론 작업에서 GPT-4x 시리즈를 능가하며 비용은 훨씬 저렴합니다 (출처: Huggingface, GeeksforGeeks, Artificial Analysis)
- Qwen 2.5 7B Instruct는 GPQA, HumanEval, MATH 벤치마크에서 GPT-4를 능가하면서도 극히 적은 리소스를 사용합니다 (출처: LLM Stats)
- Qwen3-Coder-480B-A35B-Instruct는 Claude 4 Sonnet과 비슷한 수준입니다 (출처: Huggingface, Venture Beat)
- DeepSeek V3는 GPT-4o보다 더 많은 저대표 언어를 지원합니다 (출처: Machine Translation)
- Llama 3.1은 수학 및 긴 컨텍스트에서 GPT-4와 Claude 3.5 Sonnet을 능가합니다 (출처: OpenAI Developer Community)
이러한 결과는 점점 더 현실을 보여줍니다: 작업과 제약 조건을 알고 있다면 오픈 모델을 사용하여 더 낮은 비용으로 더 나은 결과를 얻을 수 있는 경우가 많습니다.
요구 사항에 맞추지 않고 GPT-4를 기본값으로 사용하면 다음과 같은 결과가 발생합니다:
- 특화된 추론에 의존하는 제품은 일반 모델의 통과할 만한 출력에 만족하지만, 더 특화된 (그리고 종종 더 작은) 모델이 더 나은 성능을 제공할 수 있습니다
- 작은 모델로 충분한 작업에 큰 모델을 사용하면 에너지 사용이 증가하고 환경에 심각한 부정적 영향을 미칩니다
- 스타트업과 소규모 팀은 오픈소스 모델이 동일하거나 더 나은 결과를 쉽게 제공할 수 있음에도 불구하고 비싼 API에 예산을 소진하는 경우가 많습니다
- 대규모 엔터프라이즈는 대량 추론에서 막대한 비용을 발생시키며, 오픈 대안이 그 비용을 절반 이상 줄일 수 있다는 사실을 모릅니다
오픈소스 모델을 사용해야 하는 이유
GPT-4x 및 Claude 3 시리즈와 같은 모델은 강력한 범용 모델로, 코딩에서 창작 글쓰기에 이르기까지 다양한 작업에서 광범위한 기능을 제공합니다. 그러나 수평적 기능은 종종 특정 작업 부하나 제한된 환경에서 가장 효율적이거나 저렴한 선택이 아니라는 것을 의미합니다. 컴팩트한 전문 모델과 대규모 범용 대안을 포함한 많은 오픈소스 모델이 이들을 능가하거나 일치시킬 수 있으며, 더 나은 속도, 제어, 비용 효율성을 제공합니다.
하지만 특정 애플리케이션에 최적의 모델을 찾아 프로덕션에 배포하는 것은 어렵습니다. OpenAI나 Claude의 폐쇄형 옵션과 달리, 오픈 모델은 거의 호스팅되지 않습니다. 컴퓨팅, 지연 시간, 처리량 요구 사항을 직접 구성해야 하는 경우가 많습니다. 이러한 복잡성으로 인해 많은 개발자와 기업이 GPT-4나 Claude 같은 익숙한 범용 모델을 기본값으로 사용하게 됩니다. 하지만 가벼운 전문 모델과 강력한 범용 모델을 포함한 오픈 대안이 더 나은 성능, 더 빠른 응답, 더 낮은 비용을 제공할 수 있음에도 불구하고 말이죠. 이때 Novita가 등장합니다. Novita는 오픈소스 모델을 호스팅하며, 필요에 따라 특정 요구 사항에 맞게 구성하여 번거로움 없이 이러한 모델을 사용할 수 있도록 합니다.
Moonshot AI의 Kimi K2는 GPT-4.1을 능가하는 오픈소스 LLM의 뛰어난 예입니다. 코딩 및 수학적 추론에서 Kimi-K2는 53.7%의 정확도를 달성하는 반면, GPT-4.1은 44.7%입니다 (출처: Huggingface).
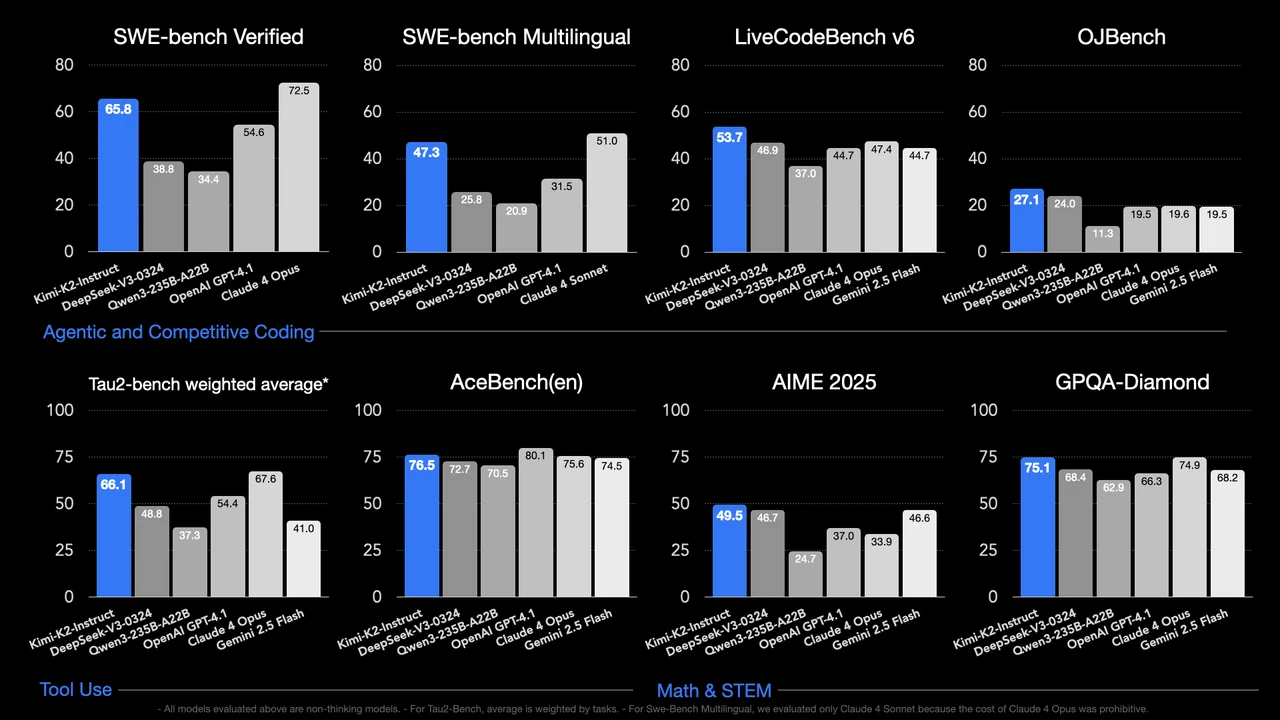
제목: Kimi K2 성능 vs GPT-4.1 및 기타 업계 리더
출처: Huggingface
범용 모델이 적합한 경우
GPT-4, Claude, Gemini와 같은 폐쇄형 모델은 여전히 적절한 위치를 차지하고 있습니다. 특히 빠르게 프로토타이핑을 하고 강력한 일반 성능 벤치마크를 원하는 상황에서 그렇습니다. 또한 작업 부하가 명확한 전문화 없이 다양한 작업에 걸쳐 있거나, 소량 추론을 실행하며 비용이 아직 주요 관심사가 아닌 경우에도 좋은 선택입니다. 이러한 경우 범용 모델의 편의성, 광범위한 기능, 즉시 사용 가능한 성능이 트레이드오프를 능가할 수 있습니다.
사용량이 증가함에 따라 애플리케이션에 적합한 모델을 찾는 것이 중요해집니다. 이 모델은 인기나 편의성이 아니라 특정 작업, 제약 조건, 규모에 최적화되어야 합니다. 이는 다음 질문으로 이어집니다: 애플리케이션에 적합한 모델을 어떻게 선택할까요?
애플리케이션에 적합한 모델을 선택하는 방법
최고의 모델을 선택하는 것은 단순히 좁은 작업에 대한 벤치마크 성능에 관한 것이 아닙니다. 이는 최적화 문제이며, 전문화, 지연 시간, 처리량, 비용 간의 트레이드오프를 균형 있게 조정해야 합니다.
고려해야 할 주요 차원은 다음과 같습니다:
- 사용 사례 특수성: 범용 어시스턴트가 필요한가요, 아니면 요약이나 논리적 추론과 같은 작업에 전문가가 필요한가요? 특수화된 사용 사례는 작업에 맞게 미세 조정된 더 작은 모델의 이점을 얻는 경우가 많으며, 범용 모델은 더 넓은 범위를 제공하지만 비용과 지연 시간이 더 높습니다.
- 성능 vs. 지연 시간: 애플리케이션이 얼마나 빨리 응답해야 하나요? 챗봇은 DeepSeek-V3와 같은 더 가볍거나 지연 시간이 낮은 모델을 선호하며, 이는 거의 즉각적인 응답과 강력한 작업별 성능을 제공합니다. 더 느린 모델은 이론적으로 더 강력하더라도 사용자 경험을 저하시킬 수 있습니다.
- 비용 vs. 규모: 예상 사용량은 어떻게 되나요? 요청당 1센트 미만의 비용이 드는 모델은 초기에는 무시할 만해 보일 수 있습니다. 그러나 규모가 커지면 이러한 비용이 누적됩니다. 자체 인프라(또는 Novita와 같은 호스팅 플랫폼)에서 실행되는 오픈소스 모델은 규모가 커질수록 비용을 크게 줄일 수 있습니다.
- 유연성 및 제어: 모델을 도메인, 톤, 작업 구조에 맞게 조정해야 하나요? 오픈 모델은 다른 사람의 것을 중심으로 작업하는 대신 필요에 맞게 모델을 미세 조정하고 최적화할 수 있는 옵션을 제공합니다. 이 경우 Novita는 사용자 정의 또는 미세 조정된 모델을 위한 모델 호스팅 지원을 제공합니다.
- 인프라 트레이드오프: 어떤 인프라를 보유하고 있거나 관리하지 않으려 하나요? GPU를 켜거나 인프라를 관리하지 않으려면 GPT-4와 같은 폐쇄형 모델이 유일한 옵션이라고 가정하기 쉽습니다. 하지만 Novita와 같은 플랫폼은 오픈 모델에 대해 동일한 원활한 완전 호스팅 경험을 최대 50% 저렴한 비용으로 제공합니다.
추상적으로 "최고의 모델"을 선택하는 것이 아닙니다. 실제로는 작업 적합성, 지연 시간, 비용과 같은 경쟁하는 제약 조건을 최적화하는 것입니다. 올바른 모델은 목표에 따라 달라지며, 좋은 플랫폼은 최적의 적합성을 찾을 때까지 모델을 쉽게 테스트, 교체, 반복할 수 있게 해줍니다. Artificial Analysis와 같은 리소스는 이러한 트레이드오프를 명확히 하고 정보에 기반한 결정을 내리는 데 도움을 줍니다.
획일적인 접근을 넘어서
GPT-4와 같은 모델의 지배력이 반드시 더 좋다는 것을 의미하지는 않습니다. 단지 편리할 뿐입니다. 하지만 그 트레이드오프는 더 이상 필요하지 않습니다. Novita AI와 같은 플랫폼은 오픈 가중치와 프로덕션 준비 상태 사이의 격차를 좁히고 있으며, 개발자에게 인프라의 번거로움 없이 수백 개의 오픈 모델에 대한 액세스를 제공합니다. 그러니 GPT-4를 기본값으로 사용하지 마세요. 모델이 애플리케이션에 맞아야 하지, 그 반대가 되어서는 안 됩니다.
Novita AI의 전문가들은 맞춤형 모델 추천 및 인프라 튜닝을 포함한 실무 지원을 제공합니다. 전문화, 지연 시간, 처리량, 비용 효율성과 같은 중요 차원을 기반으로 특정 사용 사례에 맞는 올바른 오픈소스 모델을 구성하는 데 도움을 드립니다. 최고 수준의 API에서 기대하는 속도, 신뢰성, 편의성과 오픈소스 모델의 유연성 및 비용 이점을 제공합니다. 자세한 내용은 문의해 주세요.



