

Trouver le modèle optimal pour votre application spécifique et le mettre en production est difficile. Contrairement aux options propriétaires d’OpenAI ou Claude, les modèles ouverts sont rarement hébergés. Vous devez souvent configurer vous-même les besoins en calcul, latence et débit. Cette complexité pousse de nombreux développeurs et entreprises à utiliser par défaut des modèles généralistes familiers comme GPT-4 ou Claude, même lorsque des alternatives ouvertes, incluant à la fois des spécialistes légers et des généralistes puissants, pourraient offrir de meilleures performances, des réponses plus rapides et des coûts réduits. C’est là que Novita entre en jeu. Novita héberge des modèles open-source et, si nécessaire, les configure selon vos besoins spécifiques, afin que vous puissiez utiliser ces modèles sans tracas.
Pourquoi tout le monde utilise-t-il GPT-4 ?
Le paysage des modèles d’IA se développe rapidement, comprenant des centaines de modèles, chacun avec ses forces et faiblesses uniques. Cependant, malgré les performances croissantes des modèles open-source, la série GPT-4x, la série Claude 3x et d’autres modèles propriétaires restent le choix par défaut pour de nombreuses équipes. Dans cet article, nous allons analyser quand il est judicieux d’utiliser des modèles propriétaires, quand ce ne l’est pas, et comment Novita rend le déploiement de LLM open-source aussi simple que l’utilisation d’un modèle propriétaire.
Ces modèles propriétaires populaires sont hébergés et faciles à utiliser, donc pas besoin de se soucier de l’infrastructure, de la configuration ou du déploiement. Il suffit d’appeler une API pour obtenir l’inférence. Ces modèles sont également largement performants, excellant dans une variété de tâches généralistes comme l’écriture, le raisonnement et le codage. Et comme ils sont largement adoptés, ils sont perçus comme une option à faible risque.
… Mais à quel prix ?
Opter par défaut pour des modèles propriétaires généralistes peut sembler le choix le plus sûr, mais cela entraîne souvent des coûts cachés. Se fier uniquement aux modèles propriétaires peut vous priver d’alternatives open-source puissantes comme Qwen et DeepSeek, qui offrent des résultats comparables ou supérieurs avec un plus grand contrôle, une transparence accrue et une meilleure rentabilité à long terme. En fait, de nombreuses équipes finissent par payer trop cher pour des fonctionnalités qu’elles n’utilisent pas, gaspillant des ressources de calcul et d’énergie sur des tâches qui ne nécessitent pas de modèles massifs de plus de 100B paramètres, avec des conséquences environnementales à la clé. De plus, les performances généralistes peuvent souffrir sur des tâches spécialisées où des modèles plus petits et/ou plus spécialisés excellent.
De nombreux modèles ouverts surpassent ou égalent désormais les meilleurs modèles propriétaires dans des tâches clés :
- Kimi K2, DeepSeek R1 et Qwen 3 235B A22B surpassent la série GPT-4x dans les tâches de codage et de raisonnement mathématique à une fraction du coût (Source : Huggingface, GeeksforGeeks, Artificial Analysis)
- Qwen 2.5 7B Instruct surpasse GPT-4 sur les benchmarks GPQA, HumanEval et MATH tout en utilisant seulement une fraction des ressources (Source : LLM Stats)
- Qwen3-Coder-480B-A35B-Instruct est comparable à Claude 4 Sonnet (Source : Huggingface, Venture Beat)
- DeepSeek V3 prend en charge plus de langues sous-représentées que GPT-4o (Source : Machine Translation )
- Llama 3.1 surpasse GPT-4 et Claude 3.5 Sonnet en mathématiques et en contexte long (Source : OpenAI Developer Community )
Ces résultats mettent en évidence une réalité croissante : si vous connaissez votre tâche et vos contraintes, vous pouvez souvent obtenir de meilleurs résultats à moindre coût avec des modèles ouverts.
Utiliser GPT-4 par défaut plutôt qu’en fonction de vos besoins a des conséquences :
- Les produits qui reposent sur un raisonnement spécialisé se contentent de résultats passables de modèles généralistes, alors que des modèles plus spécialisés (et souvent plus petits) peuvent offrir de meilleures performances.
- Utiliser un grand modèle alors qu’un plus petit fait l’affaire augmente la consommation d’énergie et a un impact environnemental négatif significatif.
- Les startups et les petites équipes brûlent souvent leur budget sur des API coûteuses alors que des modèles open-source peuvent facilement fournir les mêmes résultats (voire meilleurs).
- Les entreprises à grande échelle accumulent des coûts énormes d’inférence à haut volume, sans se rendre compte que les alternatives ouvertes peuvent réduire ces factures de moitié ou plus.
Pourquoi opter pour les modèles open-source
Les modèles comme les séries GPT-4x et Claude 3 sont de puissants généralistes, capables de réaliser un large éventail de tâches, du codage à l’écriture créative. Mais leur capacité horizontale signifie souvent qu’ils ne sont pas les plus efficaces ou les plus abordables pour des charges de travail ciblées ou des environnements contraints. De nombreux modèles open-source, y compris des spécialistes compacts et des alternatives généralistes de grande taille, peuvent égaler ou les surpasser, offrant une meilleure vitesse, un meilleur contrôle et une meilleure rentabilité.
Mais trouver le modèle optimal pour votre application spécifique et le mettre en production est difficile. Contrairement aux options propriétaires d’OpenAI ou Claude, les modèles ouverts sont rarement hébergés. Vous devez souvent configurer vous-même les besoins en calcul, latence et débit. Cette complexité pousse de nombreux développeurs et entreprises à utiliser par défaut des modèles généralistes familiers comme GPT-4 ou Claude, même lorsque des alternatives ouvertes, incluant à la fois des spécialistes légers et des généralistes puissants, pourraient offrir de meilleures performances, des réponses plus rapides et des coûts réduits. C’est là que Novita entre en jeu. Novita héberge des modèles open-source et, si nécessaire, les configure selon vos besoins spécifiques, afin que vous puissiez utiliser ces modèles sans tracas.
Le Kimi K2 de Moonshot AI est un exemple remarquable de LLM open-source qui surpasse GPT-4.1. En codage et en raisonnement mathématique, Kimi-K2 atteint une précision de 53,7 %, contre 44,7 % pour GPT-4.1 (Source : Huggingface).
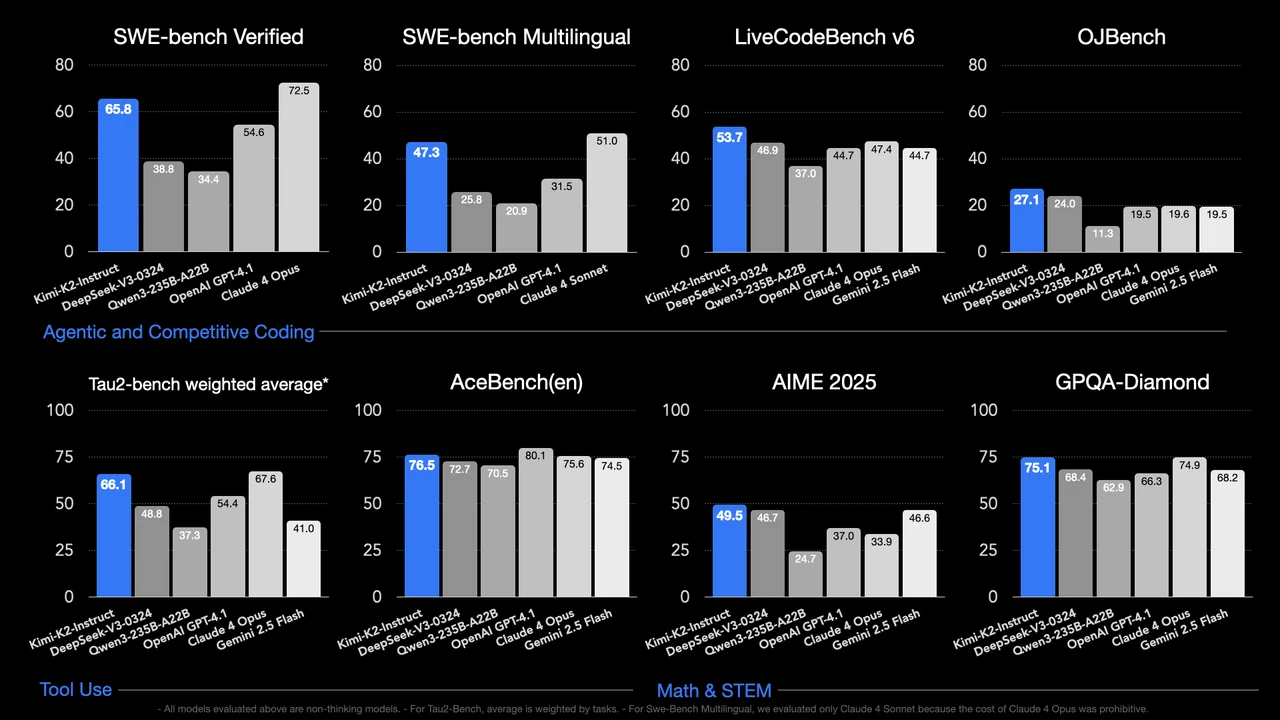
Titre : Performances de Kimi K2 par rapport à GPT-4.1 et à d’autres leaders du secteur
Source : Huggingface
Quand les modèles généralistes sont pertinents
Les modèles propriétaires comme GPT-4, Claude et Gemini ont toujours leur place, surtout lorsque vous prototypiez rapidement et que vous souhaitez un benchmark de performance généraliste solide. Ils sont également adaptés lorsque vos charges de travail couvrent un large éventail de tâches sans spécialisation claire, ou lorsque vous effectuez des inférences à faible volume et que le coût n’est pas encore une préoccupation majeure. Dans ces cas, la commodité, la large capacité et les performances prêtes à l’emploi des modèles généralistes peuvent l’emporter sur les compromis.
À mesure que l’utilisation augmente, il est utile de trouver le bon modèle pour votre application. Ce modèle doit être optimisé pour vos tâches spécifiques, vos contraintes et votre échelle, plutôt que d’être choisi en fonction de ce qui est populaire ou pratique. Cela nous amène à la question suivante : Comment choisir le bon modèle pour votre application ?
Comment choisir le bon modèle pour votre application
Choisir le meilleur modèle ne se résume pas à la performance sur un benchmark restreint. C’est un problème d’optimisation, qui nécessite d’équilibrer les compromis entre spécialisation, latence, débit et coût.
Voici les dimensions clés à considérer :
- Spécificité du cas d’usage : Avez-vous besoin d’un assistant généraliste ou d’un expert pour des tâches comme le résumé ou le raisonnement logique ? Les cas d’usage spécialisés bénéficient souvent de modèles plus petits, affinés pour la tâche, tandis que les modèles généralistes offrent une couverture plus large mais à un coût et une latence plus élevés.
- Performances vs Latence : À quelle vitesse votre application doit-elle répondre ? Un chatbot privilégiera des modèles plus légers ou à faible latence comme DeepSeek-V3, qui offrent des réponses quasi instantanées avec des performances solides spécifiques à la tâche. Des modèles plus lents peuvent compromettre l’expérience utilisateur, même s’ils sont plus puissants sur le papier.
- Coût vs Échelle : Quels sont vos volumes d’utilisation prévus ? Un modèle qui coûte des fractions de centime par requête peut sembler négligeable au début. Lorsqu’on travaille à grande échelle, ces coûts s’accumulent. Les modèles open-source fonctionnant sur votre propre infrastructure (ou avec une plateforme hébergée comme Novita) peuvent réduire considérablement les coûts à grande échelle.
- Flexibilité et contrôle : Avez-vous besoin d’adapter le modèle à votre domaine, ton ou structure de tâche ? Les modèles ouverts vous offrent la possibilité d’affiner et d’optimiser le modèle en fonction de vos besoins, plutôt que de contourner ceux des autres. Dans ce cas, Novita propose un hébergement de modèles pour vos modèles personnalisés ou affinés.
- Compromis d’infrastructure : Quelle infrastructure possédez-vous ou souhaitez-vous éviter de gérer ? Si vous voulez éviter de lancer des GPU ou de gérer une infrastructure, il est facile de supposer que les modèles propriétaires comme GPT-4 sont votre seule option. Cependant, des plateformes comme Novita offrent la même expérience hébergée transparente pour les modèles ouverts, à jusqu’à 50 % du coût.
Il ne s’agit pas de choisir abstraitement le « meilleur modèle ». En pratique, vous optimisez entre des contraintes concurrentes, comme l’adéquation à la tâche, la latence et le coût. Le bon modèle dépend de vos objectifs, et une bonne plateforme facilite les tests, les changements et les itérations jusqu’à trouver la solution optimale. Des ressources comme Artificial Analysis aident à clarifier ces compromis et peuvent vous aider à prendre des décisions éclairées.
Au-delà du modèle unique
La domination de modèles comme GPT-4 ne signifie pas nécessairement qu’ils sont meilleurs, seulement qu’ils sont pratiques. Mais ce compromis n’est plus nécessaire. Des plateformes comme Novita AI comblent le fossé entre les poids ouverts et la préparation à la production, offrant aux développeurs l’accès à des centaines de modèles ouverts sans les tracas de l’infrastructure. Alors, n’utilisez pas GPT-4 par défaut. Votre modèle doit s’adapter à votre application, et non l’inverse.
Chez Novita AI, nos experts fournissent un accompagnement pratique, incluant des recommandations de modèles personnalisées et un réglage de l’infrastructure. Nous vous aiderons à configurer le modèle open-source adapté à votre cas d’usage spécifique en fonction de dimensions critiques comme la spécialisation, la latence, le débit et la rentabilité. Nous offrons la rapidité, la fiabilité et la facilité que vous attendez des API de premier plan avec la flexibilité et les avantages de coût des modèles open-source. Contactez-nous pour plus d’informations.



