

Многие разработчики и предприятия сталкиваются с высокими задержками и затратами на токены при повторном использовании больших языковых моделей с похожими промптами. Каждый запрос заставляет модель заново обрабатывать одинаковые инструкции или документы, что приводит к напрасной трате вычислительных ресурсов и времени.
В этой статье объясняется, как кэширование промптов решает эту проблему, сохраняя предварительно вычисленные префиксы промптов для повторного использования в разных запросах. Мы разграничиваем разницу между кэшем промптов и KV-кэшем, показываем, как системы вроде Novita AI реализуют эффективное кэширование, и даём практические рекомендации по структурированию промптов, мониторингу производительности кэша, а также предотвращению неправильного использования и рисков безопасности.
Что такое кэширование промптов?
Кэширование промптов подразумевает сохранение предварительно вычисленных частей промпта (например, системных инструкций, повторяющегося контекста или документов), чтобы при повторном использовании того же или похожего промпта модель не вычисляла его заново с нуля.
For prompt cache to hit successfully, the following token sequences must be identical:
System: [system_instructions] # Fixed prefix, reusable
Document: [retrieved_context] # Changes will break cache reuse
User: [query] # Changes will break cache reuse
| Шаг | Описание |
|---|---|
| 1. Отправка промпта | Запрос с длинным или повторяющимся промптом отправляется модели. |
| 2. Кодирование и кэширование | Система кодирует префикс промпта во внутренние эмбеддинги или скрытые состояния, после чего сохраняет их в кэш. |
| 3. Проверка попадания в кэш | Если последующий запрос содержит тот же префикс, система обнаруживает совпадение и загружает кэшированное представление. |
| 4. Повторное использование и продолжение | Модель пропускает повторную обработку этого префикса и продолжает генерацию из кэшированного состояния. |
| 5. Истечение срока действия | Записи в кэше истекают после заданного TTL (например, 5 минут бездействия в Amazon Bedrock). TTL сбрасывается при каждом повторном использовании). |
https://www.youtube.com/watch?v=RDjaUJz-uWo
Чем кэш промптов отличается от KV-кэша?
| Аспект | KV-кэш | Кэш промптов |
|---|---|---|
| Область применения | В рамках одной генерации или сессии | Между несколькими запросами или сессиями |
| Назначение | Избегает повторного вычисления внимания для предыдущих токенов | Избегает повторной обработки повторяющихся префиксов промптов |
| Хранимые данные | Ключи и значения внимания трансформера | Закодированные префиксы промптов или модули |
| Преимущество | Снижает задержку на один токен | Снижает стоимость входных токенов и время обработки полного промпта |
| Типичное использование | Авторегрессивное декодирование (например, генерация LLM) | Повторное использование общих промптов в приложениях или API |
Как кэширование промптов снижает задержки и вычислительные затраты?
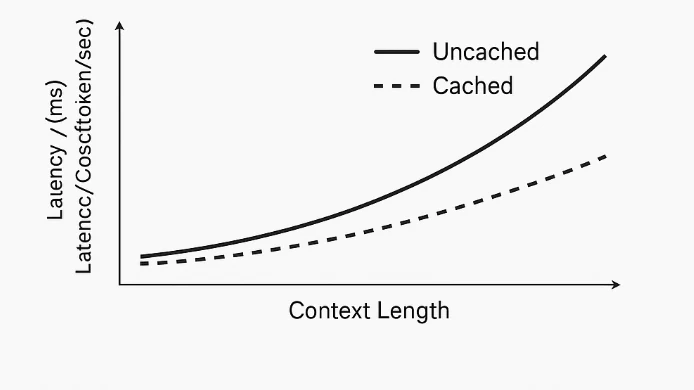
Кэширование промптов работает на уровне системы, а не внутри модели. Сама модель обрабатывает все токены одинаково и не различает «промпт» и «ссылочный контент». При обнаружении повторяющегося префикса токенов система кэширует его вычисленные представления — например, эмбеддинги и состояния трансформера. При последующих запросах с тем же префиксом модель пропускает повторный расчёт этой части и обрабатывает только новые токены. Это снижает избыточные вычисления, уменьшает задержки и уменьшает затраты, связанные с токенами.
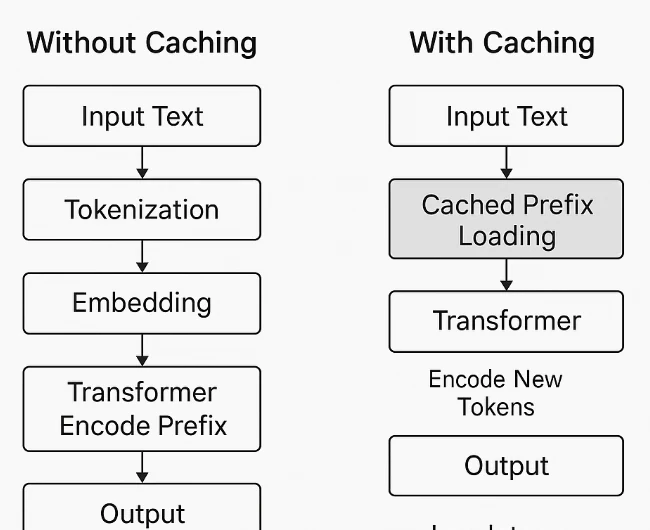
Кэширование промптов на Novita AI
Novita AI расширила линейку моделей, добавив поддержку кэша промптов для нескольких моделей с большим контекстным окном, что позволяет разработчикам значительно сократить расходы и улучшить задержки для длинных или повторяющихся задач. Кэширование промптов сохраняет ранее использованные промпты или эмбеддинги, поэтому последующие вызовы API, ссылающиеся на тот же контент, обрабатываются по значительно более низкой ставке чтения из кэша.
Эта функция идеально подходит для многоходовых диалогов, систем генерации с дополнением извлечённых данных (RAG) или конвейеров рабочих процессов, которые повторно используют большие системные промпты. Благодаря использованию чтения из кэша команды могут получать более быстрые ответы и снижать расходы, сохраняя при этом точность модели и целостность контекста.
Поддерживаемые модели и тарифы
| Модель | Контекстное окно | Цена на вход (за 1 млн токенов) | Чтение из кэша (за 1 млн токенов) | Цена на выход (за 1 млн токенов) |
|---|---|---|---|---|
| deepseek/deepseek-v3-0324 | 163 840 | $0.27 / Mt | $0.135 / Mt | $1.12 / Mt |
| deepseek/deepseek-r1-0528 | 163 840 | $0.70 / Mt | $0.35 / Mt | $2.50 / Mt |
| zai-org/glm-4.6 | 204 800 | $0.60 / Mt | $0.11 / Mt | $2.20 / Mt |
| zai-org/glm-4.5 | 131 072 | $0.60 / Mt | $0.11 / Mt | $2.20 / Mt |
| zai-org/glm-4.5v | 65 536 | $0.60 / Mt | $0.11 / Mt | $1.80 / Mt |
💡 Почему это важно
При длине контекста до 204 000 токенов эти модели могут обрабатывать очень длинные входные данные, такие как целые документы, расшифровки или кодовые базы. Добавление кэширования промптов гарантирует, что пользователи могут повторно использовать тяжёлые промпты, не оплачивая полную стоимость входных данных каждый раз — это снижает общие расходы и улучшает время ответа при повторяющихся запросах.
Разработчики могут теперь создавать масштабируемые, экономически эффективные и насыщенные контекстом AI-приложения напрямую на инфраструктуре Novita AI.
Как использовать кэширование промптов более эффективно?
Как следует структурировать промпты, чтобы увеличить процент попаданий в кэш? Разделите статический префикс (инструкции, документы, шаблоны) от переменного запроса. Содержимое префикса должно быть идентичным во всех запросах. Чётко определите границы контрольных точек кэша. Используйте модульные шаблоны вида «Система: [роль]… Документ: [контекст]… Пользователь: [запрос]».
Как долго кэш сохраняется до истечения срока действия? Реализация и сроки истечения зависят от провайдера, рабочей нагрузки и конфигурации. Некоторые системы истекают через несколько минут или часов; другие хранят кэш, пока не будет достигнут лимит памяти.
Если немного изменить промпт, попадание в кэш сохранится? Гарантий нет. Попадания в кэш зависят от точного совпадения префикса или структурного повторного использования. Даже небольшие различия в тексте или форматировании могут привести к промаху.
Можно ли кэшировать динамический контент? Эффективно кэшировать можно только статическую часть промпта. Динамические элементы, такие как пользовательские данные, метки времени или значения в реальном времени, должны оставаться за пределами кэшированного префикса.
Могут ли разные версии моделей повторно использовать один и тот же кэш? Обычно нет. Кэши привязаны к конкретным архитектурам моделей, токенизаторам и пространствам эмбеддингов. Обновление или переключение моделей обычно делает старые кэши недействительными.
Как обстоит ситуация с длинными текстами или сценариями RAG (генерация с дополнением извлечённых данных)? Кэширование промптов лучше всего работает, когда повторяется большой статический документ или префикс, как в системах вопросов-ответов по документам. В RAG, где извлекаемый контекст меняется для каждого запроса, можно повторно использовать только часть префикса, поэтому процент попаданий в кэш ниже.
Какие риски стоит учитывать при работе с кэшированием промптов?
Устаревшие или некорректные попадания в кэш
Кэшированные префиксы могут устареть, если контекст меняется, например, при обновлении документов. Ошибки границ или несоответствие динамического контента могут привести к семантическому дрейфу.
Риски конфиденциальности и безопасности
Общие KV- или кэши промптов в многопользовательских системах могут привести к утечке данных между пользователями. Атака «PROMPTPEEK» продемонстрировала восстановление промптов через общие побочные каналы кэша. Не включайте динамические или пользовательские данные в общие кэшированные префиксы.
Мониторинг эффективности
Отслеживайте процент попаданий и промахов, количество токенов, прочитанных из кэша, относительно общего числа токенов, снижение задержки и экономию расходов.
Предотвращение неправильного использования
Кэшируйте только статический контент. Аннулируйте кэши при изменении исходных данных. Изолируйте кэши для каждого пользователя или арендатора для обеспечения конфиденциальности.
Будущие направления развития
Улучшение идентификации кэша и поддержка семантического сопоставления префиксов. Создание единых безопасных систем кэширования для разных моделей и сессий. Использование сжатия и выгрузки данных на GPU, CPU и диск.
Кэширование промптов снижает избыточные вычисления, уменьшает задержки и сокращает расходы на токены за счёт повторного использования идентичных эмбеддингов префиксов в разных запросах. Его эффективность зависит от стабильной структуры промптов, аккуратного разделения статического и динамического контента, а также ответственного управления кэшем. Провайдеры вроде Novita AI демонстрируют, как низкозатратное и стабильное кэширование может повысить общую эффективность, сохраняя при этом безопасность и точность.
Novita AI — это облачная AI-платформа, которая предлагает разработчикам простой способ развертывания AI-моделей через наш простой API, а также доступную и надёжную GPU-облако для создания и масштабирования решений.



