

- DeepSeek V3.1 vs Kimi K2: Especificações Técnicas
- DeepSeek V3.1 vs Kimi K2: Benchmarks
- DeepSeek V3.1 vs Kimi K2: Velocidade
- Qual é Melhor para Tarefas de Programação — DeepSeek V3.1 ou Kimi K2?
- DeepSeek V3.1 vs Kimi K2: Requisitos de Sistema
- Como Acessar DeepSeek V3.1 e Kimi K2 Através de uma API Barata e Estável?
Ao construir aplicações confiáveis orientadas por IA, desenvolvedores frequentemente enfrentam um dilema entre capacidade de raciocínio profundo e usabilidade prática. Este artigo aborda esse desafio comparando DeepSeek V3.1 vs Kimi K2 e mostrando como eles se complementam. Na prática, um fluxo de trabalho híbrido pode ser altamente eficaz.
DeepSeek V3.1 vs Kimi K2: Especificações Técnicas
| Característica | DeepSeek V3.1 | Kimi K2 |
|---|---|---|
| Parâmetros Totais | 671B | 1 Trilhão |
| Ativados por Token | ~37B | ~32B |
| Especialistas | 257 (8 ativos/token) | 384 (8 ativos/token) |
| Janela de Contexto | 128K tokens | 128K tokens |
| Arquitetura | MoE (MLA), balanceamento de carga eficiente | MoE + otimizador MuonClip, reforço agentivo |
| Modos Especiais | Inferência híbrida (Pensar / Não Pensar) | Foco em tarefas agentivas (variante Instruct) |
Tanto o DeepSeek V3.1 quanto o Kimi K2 introduziram seus próprios templates de chat para tornar os modelos mais fáceis de controlar e integrar em aplicações reais:
O DeepSeek V3.1 usa tokens especiais (
pensar/responder) para que desenvolvedores possam alternar explicitamente entre respostas diretas rápidas e raciocínio mais profundo,o que é adequado para cenários que exigem controle refinado sobre custo e desempenho, enquanto o Kimi K2 adota um formato padrão de mensagens no estilo OpenAI, oferecendo integração simples e pronta para uso em produtos e agentes.
DeepSeek V3.1 (Não Pensar vs Pensar)
Prefixo Não Pensar
You are DeepSeek V3.1.
usuário:O que é RLHF?
assistente: responder
Prefixo Pensar
You are DeepSeek V3.1.
usuário:O que é RLHF?
assistente: pensar
Kimi K2 (API de Chat Padrão)
messages = [
{"role": "system", "content": "You are Kimi, an AI assistant."},
{"role": "user", "content": "O que é RLHF?"}
]
| Dimensão | DeepSeek V3.1 | Kimi K2 |
|---|---|---|
| Estilo do Prompt | Formato personalizado com tokens especiais pensar / responder |
Formato padrão da API OpenAI Chat |
| Controle de Modo | Separação explícita de Pensar vs Não Pensar | Sem modos explícitos; modelo decide implicitamente |
| Múltiplas Voltas | Requer costura manual de contexto com tokens | Basta anexar mensagens no array |
| Flexibilidade | Alta: desenvolvedores podem forçar ou desabilitar raciocínio | Média: depende do prompt do sistema e parâmetros |
| Facilidade de Uso | Mais complexo, template estrito necessário | Simples, plug-and-play |
DeepSeek V3.1 vs Kimi K2: Benchmarks
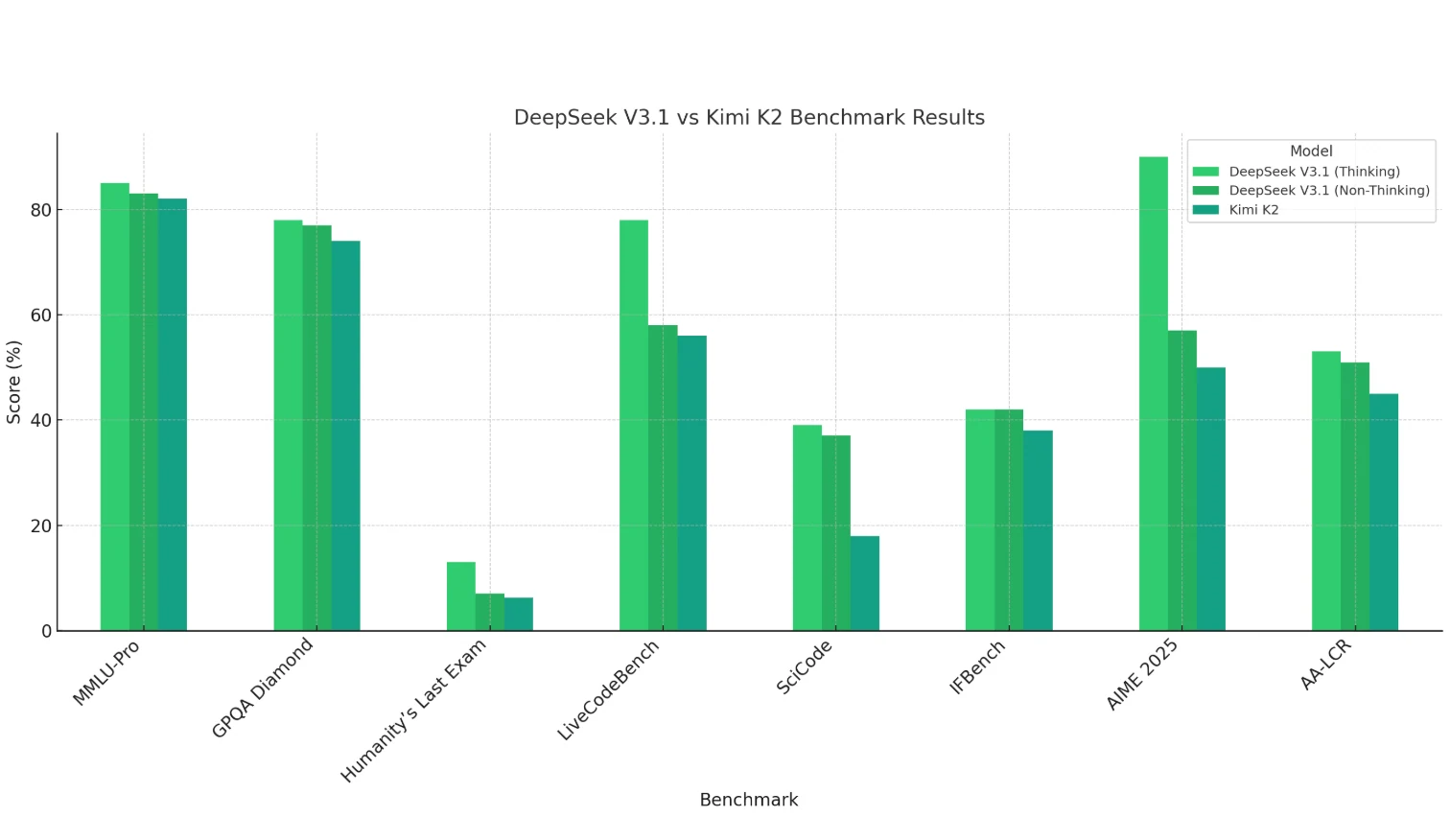
DeepSeek V3.1 (modo Pensar) mostra vantagens claras em matemática (AIME 2025), programação (LiveCodeBench, SciCode) e raciocínio de contexto longo (AA-LCR), demonstrando fortes capacidades de raciocínio e computação.
Kimi K2 tem desempenho um pouco mais fraco no geral — especialmente em programação e matemática — mas permanece competitivo em tarefas baseadas em conhecimento (MMLU, GPQA).
O modo Não Pensar do DeepSeek V3.1 geralmente pontua um pouco abaixo do modo Pensar, mas ainda iguala ou supera o Kimi K2 na maioria dos casos.
*Conclusão: DeepSeek V3.1 é mais adequado para tarefas que exigem raciocínio intensivo e complexidade, enquanto Kimi K2 se inclina mais para cenários de conhecimento geral. *
DeepSeek V3.1 vs Kimi K2: Velocidade
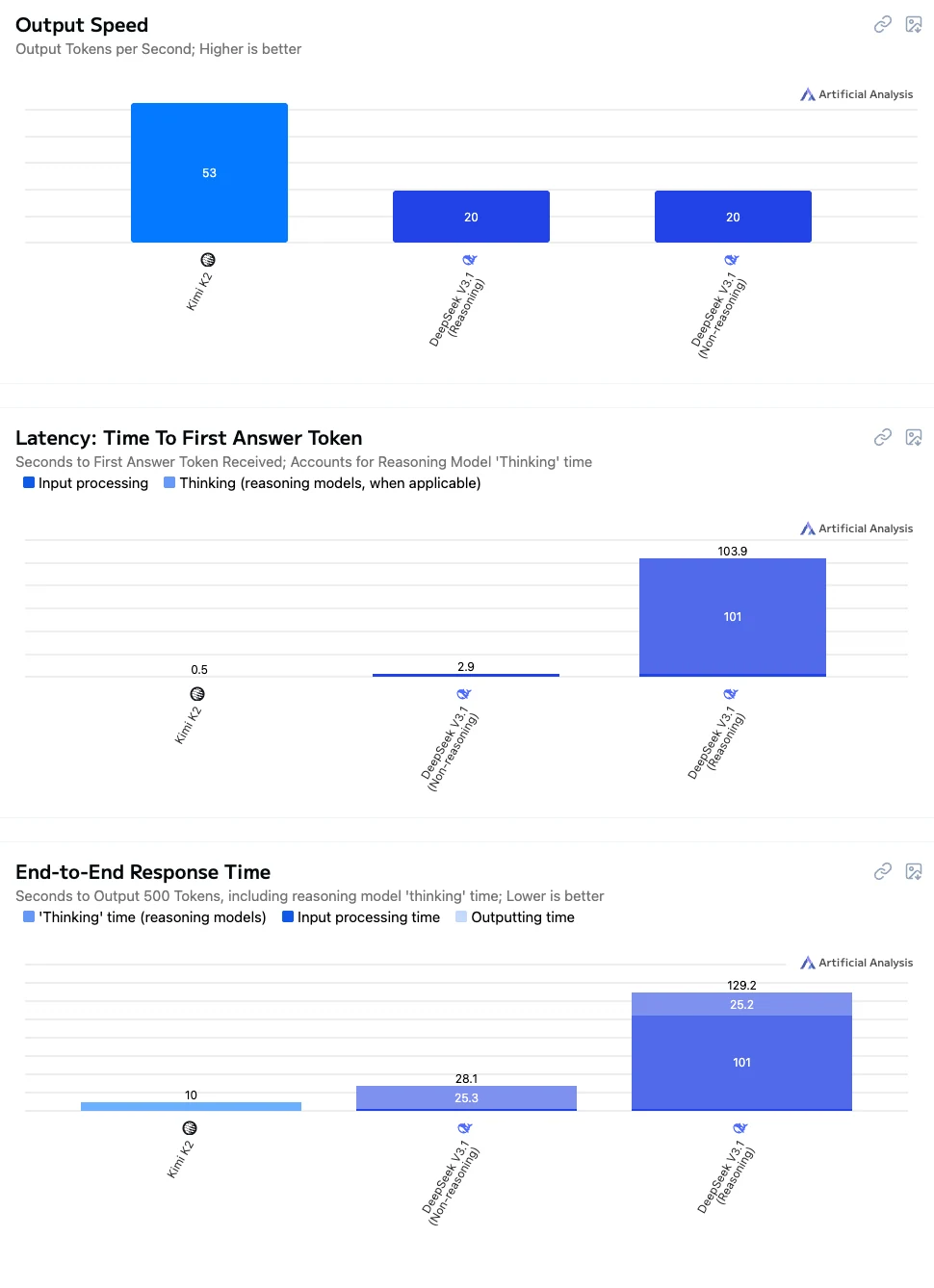
- Kimi K2: Velocidade rápida, baixa latência e interação geral suave, sendo bem adequado para conversas em tempo real, integração de aplicações e cenários educacionais.
- DeepSeek V3.1 Não Pensar: Velocidade de resposta média, adequado para tarefas que exigem precisão razoável sem longos tempos de espera.
- DeepSeek V3.1 Pensar: O mais lento em desempenho, mas oferece o raciocínio mais forte e a melhor capacidade de resolução de problemas complexos, sendo ideal para raciocínio de alta precisão, computações complexas e aplicações voltadas à pesquisa.
Qual é Melhor para Tarefas de Programação — DeepSeek V3.1 ou Kimi K2?
Tarefa: Implementar um avaliador de expressões aritméticas seguro.
Especificação
- Função:
avaliar(expr: str) -> int - Suporta: inteiros,
+ - * /, parênteses, espaços, unário+/-(ex.:-3*(+2)). - Divisão é truncamento de inteiro em direção a zero (equivalente ao comportamento de
int(a/b)do Python, não piso). - Deve detectar entrada inválida e lançar
ValueError. - Sem
eval,ast.literal_evalou parsers de terceiros.
Casos de borda a tratar
- Múltiplos sinais unários:
--5,+-3 - Espaços:
" 1 + ( 2*3 ) " - Precedência e associatividade:
2-3-4 == -5,14/3 == 4,-14/3 == -4 - Inválidos:
"(1+2","2**3","3//2","2(3)",")1("
Use DeepSeek V3.1 no playground gratuito
Use Kimi K2 no playground gratuito
Inicie um Teste Gratuito Agora!
| Dimensão de Avaliação | DeepSeek V3.1 | Kimi K2 |
|---|---|---|
| Corretude | Implementa um tokenizador manual e parser descendente recursivo. Lida com múltiplos operadores unários (--5, +-3), precedência e associatividade, e truncamento de divisão em direção a zero (correção manual). Problemas potenciais: tratamento de divisão é excessivamente complexo; mensagens de erro mínimas. Sem testes embutidos. |
Usa um lexer baseado em regex, com classes explícitas de tokens (PLUS, MINUS, etc.). Truncamento correto via int(a/b). Fornece um conjunto completo de testes em __main__ cobrindo casos válidos e inválidos. Tratamento de erros mais elegante (ValueError com mensagem). |
| Qualidade do Código | Varredura manual de caracteres de baixo nível. Parece um parser de “solução de prova”: completo, mas verboso e difícil de manter. Nenhum teste incluído. | Modularização mais limpa (Lexer, Parser, avaliar). Mais fácil de ler devido à simplificação com regex. Fornece testes, permitindo verificação mais rápida. |
| Estilo e Usabilidade | Forte em raciocínio puro, constrói tudo do zero. Adequado quando é necessário controle granular de parsing. | Otimizado para experiência do desenvolvedor: conciso, testado e pronto para produção. Mais prático para integração imediata. |
| Veredito | Forte em raciocínio sobre casos de borda e design de algoritmos. Demonstra força em construir parsers do zero, mas mais fraco em polimento e ergonomia. | Implementação mais limpa, concisa e amigável para produção. Parsing ligeiramente menos rigoroso, mas altamente utilizável. |
| Conclusão | Escolha DeepSeek V3.1 para correção robusta e profundidade algorítmica. | Escolha Kimi K2 para código legível, testado e pronto para o desenvolvedor. |
1. Construindo a Estrutura Geral → DeepSeek V3.1
- Pontos Fortes: raciocínio forte, lógica rigorosa — ótimo para estabelecer o esqueleto de sistemas complexos.
- Melhor para:
- Projetar interpretadores/compiladores, parsers ou DSLs
- Implementar algoritmos centrais e estruturas de dados
- Esboçar o fluxo de execução completo (classes, métodos, hierarquia de chamadas)
- Resultado: um rascunho completo, mas um tanto verboso, com a lógica principal totalmente implementada.
2. Refinando Detalhes e Polindo Código → Kimi K2
- Pontos Fortes: conciso, modular e amigável ao desenvolvedor — ótimo para limpeza e prontidão para produção.
- Melhor para:
- Reescrever lógica verbosa em construções mais elegantes (por exemplo, regex em vez de varredura manual)
- Adicionar testes, tratamento de erros, registro de logs
- Melhorar nomenclatura, modularização e legibilidade geral
- Resultado: uma implementação limpa, de fácil manutenção e pronta para produção.
DeepSeek V3.1 vs Kimi K2: Requisitos de Sistema
| Modelo e Configuração | Requisito de VRAM | Necessidades de GPU |
|---|---|---|
| DeepSeek V3.1 (671B) | 1.5 TB VRAM | 8x H200 podem suportar |
| Kimi K2 (Quantizado) | 250 GB combinados | 1 GPU de 24 GB |
| Kimi K2 (FP8) | 1 TB | Pods de 8xH200 ou 6xB200 |
Como Acessar DeepSeek V3.1 e Kimi K2 Através de uma API Barata e Estável?
A Novita AI lançou oficialmente as APIs do DeepSeek V3.1 e Kimi K2, dando aos desenvolvedores mais flexibilidade para tarefas de programação e raciocínio de IA de alto desempenho. Ambos os modelos são integrados com suporte para Claude Code, tornando-os diretamente úteis para fluxos de trabalho avançados de programação.
Métricas do DeepSeek V3.1
- Preço de Entrada: $0,55 por milhão de tokens
- Preço de Saída: $1,66 por milhão de tokens
- Latência: 3,00s
- Taxa de Transferência: 48,28 TPS
Métricas do Kimi K2
- Preço de Entrada: $0,57 por milhão de tokens
- Preço de Saída: $2,30 por milhão de tokens
- Latência: 1,30s
- Taxa de Transferência: 122,1 TPS
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Model Library.

Experimente DeepSeek V3.1 e Kimi K2 Agora!
Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.
Passo 3: Inicie Seu Teste Gratuito
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.
Passo 4: Obtenha Sua Chave de API
Para autenticar com a API, forneceremos uma nova chave de API. Acessando a página “Settings”, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico da sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias para seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API chat completions para usuários Python.
from openai import OpenAI
base_url = "https://api.novita.ai/openai"
api_key = "<Sua Chave de API>"
model = "deepseek/deepseek-v3.1"
client = OpenAI(
base_url=base_url,
api_key=api_key,
)
stream = True # ou False
max_tokens = 1000
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": "Olá!",
}
],
stream=stream,
extra_body={
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
No geral, DeepSeek V3.1 se destaca em tarefas intensivas em raciocínio, pesadas em matemática e relacionadas a código, sendo uma escolha forte quando precisão e profundidade lógica são primordiais. Seu modo Pensar leva a resolução de problemas complexos ao limite, enquanto o modo Não Pensar oferece um equilíbrio entre velocidade e qualidade. Kimi K2 brilha em tarefas de conhecimento geral, aplicações em tempo real e integração sem dificuldades, graças à sua velocidade de resposta mais rápida, maior taxa de transferência e API plug-and-play. Para desenvolvedores, um fluxo de trabalho híbrido pode ser eficaz: use DeepSeek V3.1 para projetar e raciocinar sobre frameworks complexos, depois conte com Kimi K2 para refinar, testar e colocar a implementação em produção.
Perguntas Frequentes
Qual modelo é melhor para tarefas de programação?
DeepSeek V3.1 (modo Pensar) é mais forte em raciocínio algorítmico e tratamento de casos de borda, sendo ideal para construir frameworks e parsers complexos. Kimi K2 produz código mais limpo e modular com testes embutidos, sendo amigável para refinamento e integração.
Como os dois modelos diferem em velocidade de desempenho?
Kimi K2 é significativamente mais rápido, com menor latência e maior taxa de transferência, sendo adequado para conversas em tempo real e cenários educacionais. DeepSeek V3.1 é mais lento, especialmente no modo Pensar, mas oferece raciocínio e precisão mais fortes para casos de uso de pesquisa ou computação pesada.
Qual devo escolher para uso geral?
Se sua prioridade é raciocínio robusto e precisão em programação, escolha DeepSeek V3.1. Se você precisa de velocidade, integração suave e alta taxa de transferência, escolha Kimi K2. Muitas equipes se beneficiam da combinação de ambos: DeepSeek para design de frameworks, Kimi para refinamento e implantação.
Novita AI é a plataforma de nuvem tudo-em-um que impulsiona suas ambições de IA. APIs integradas, serverless, GPU Instance — as ferramentas econômicas que você precisa. Liberte sua criatividade e torne sua visão de IA realidade.
Leitura Recomendada
Qwen 3 em Pipelines RAG: Modelo Tudo-em-Um de LLM, Embedding e Reranking
Como acessar o GLM 4.5V para Compreensão de Imagens e QA Visual



