

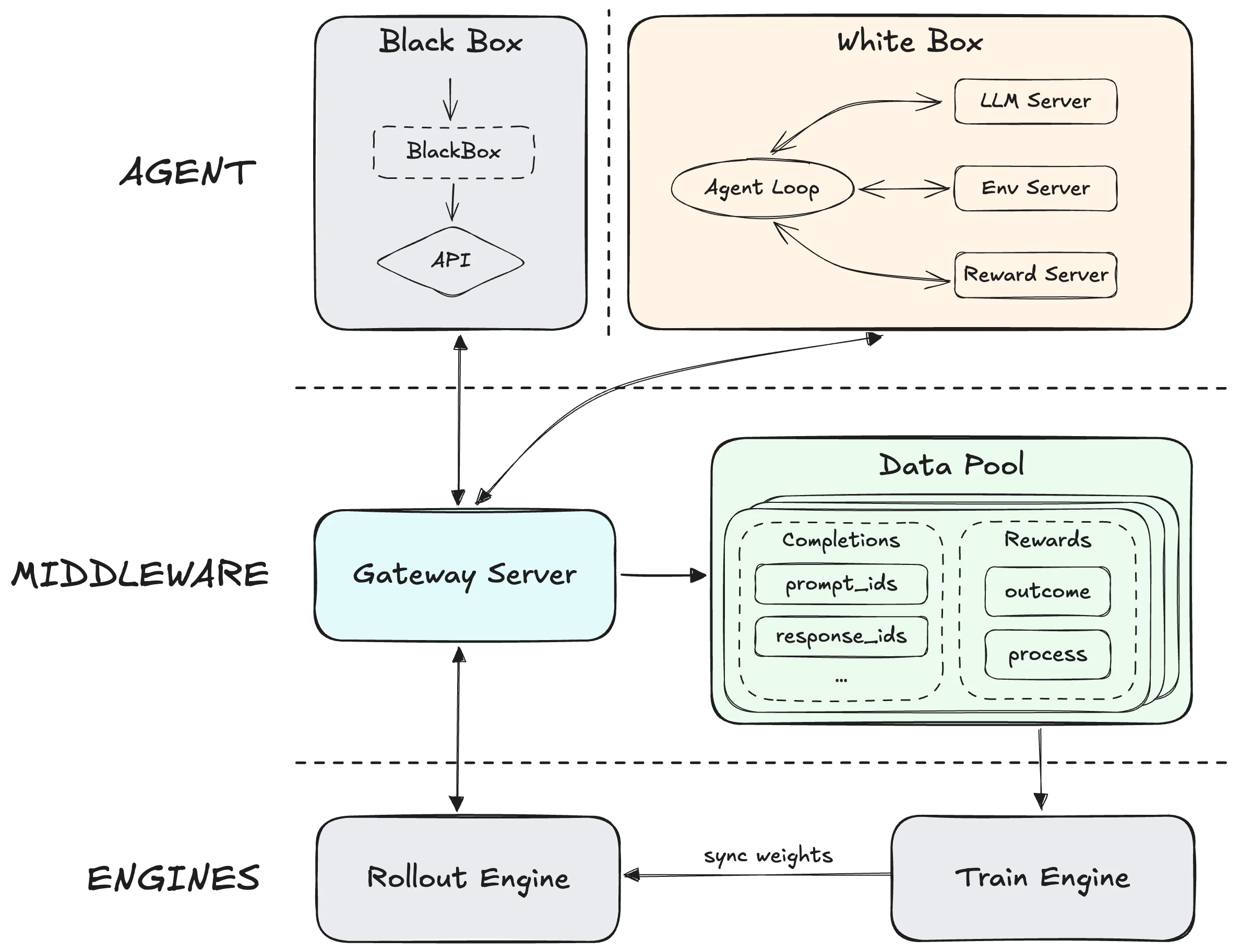
O MiniMax M2.5 iguala a pontuação de 77,8% do GLM 5 no SWE-bench Verified com um resultado de 80,2% — a um terço do custo de API na Novita AI. Lançados com 24 horas de diferença em fevereiro de 2026, esses dois modelos MoE chineses adotam abordagens diferentes para agentes de IA. O GLM 5 escala para 754B de parâmetros com 40B ativos, visando engenharia de sistemas complexos com uma janela de contexto de 200K e atenção esparsa DeepSeek. O MiniMax M2.5 mantém 228,7B de parâmetros totais com recursos de escrita de especificações, treinado em mais de 200 mil ambientes de RL do mundo real. A escolha se resume a se você precisa da profundidade arquitetônica do GLM 5 para sessões de depuração de várias horas ou do baixo custo do M2.5 para pipelines de agentes de alto volume.
Visão Geral dos Modelos MiniMax M2.5 e GLM 5
A arquitetura MoE de 754B de parâmetros do GLM 5 ativa 40B de parâmetros por inferência, tornando-a 3,2x maior que os 228,7B totais do M2.5. Essa diferença revela filosofias de design distintas que se refletem em todas as dimensões de desempenho.
| Componente de Arquitetura | GLM 5 | MiniMax M2.5 |
|---|---|---|
| Total de Parâmetros | 754B (40B ativos) | 229B |
| Arquitetura de Especialistas | 256 especialistas roteados, Top-8, 1 especialista compartilhado | 256 especialistas locais, seleção Top-8 |
| Mecanismo de Atenção | DeepSeek Sparse Attention (DSA) | Atenção padrão |
| Camadas Ocultas | 78 camadas, tamanho oculto de 6144 | 62 camadas, tamanho oculto de 3072 |
| Janela de Contexto | 202.752 tokens (200K) | 196.608 tokens (197K) |
| Dados de Treinamento | 28,5T de tokens | Não divulgado |
| Framework de RL | Slime (RL assíncrono) | Forge (RL nativo de agentes, mais de 200K ambientes) |
O DeepSeek Sparse Attention é o principal recurso arquitetônico do GLM 5. Ele mantém o desempenho de longo contexto elevado enquanto reduz os custos de implantação. A diferença de 202K vs 197K na janela de contexto parece pequena no papel, mas o DSA do GLM 5 mantém a coerência em toda essa janela sem escalonamento de memória quadrático. O MiniMax M2.5 compensa com eficiência de decomposição de tarefas em vez de capacidade bruta de contexto.
Introdução ao DSA Por kaitchup
Introdução ao Forge Por MiniMax
A lacuna no treinamento de RL conta uma história mais profunda. O framework Slime do GLM 5 permite RL assíncrono em escala sem precedentes, empurrando os limites de pré-treinamento e pós-treinamento simultaneamente. O framework Forge da MiniMax desacopla o motor de treinamento dos agentes inteiramente, otimizando para generalização em scaffolds em vez de domínio de tarefas únicas. Você está escolhendo entre um modelo treinado para lidar com qualquer coisa que seja lançada nele (GLM 5) versus um treinado nos exatos ambientes que seus agentes enfrentarão (os mais de 200K cenários de treinamento reais do M2.5).
Teste o GLM 5 e o MiniMax M2.5 Agora!
Batalha de Codificação Lado a Lado do MiniMax M2.5 e do GLM 5
A pontuação de 80,2% do M2.5 no SWE-bench Verified supera os 77,8% do GLM 5, colocando ambos a uma curta distância dos 80,9% do Claude Opus 4.6.
| Benchmark de Codificação | GLM 5 | MiniMax M2.5 | O Que Ele Mede |
|---|---|---|---|
| SWE-bench Verified | 77,8% | 80,2% | Resolução de PRs reais do GitHub |
| SWE-bench Multilingual | 73,3% | 74,1% | Correção de bugs em múltiplas linguagens |
| Terminal-Bench 2.0 | 56,2% | 51,7% | Manipulação de ambientes CLI |
A lacuna aparece em como eles atingem pontuações semelhantes. Testes controlados da Kilo AI revelam o padrão: o GLM 5 se destaca em engenharia agêncial — ciclos de depuração iterativos onde o modelo reflete sobre erros de compilador e refatora até que os testes passem. Ele atingiu 35/35 perfeitos no teste de API a partir de especificações, escrevendo 94 casos de teste, criando middleware reutilizável e usando padrões de banco de dados padrão. Zero bugs em três execuções autônomas.
O M2.5 vence na escrita de especificações — a abordagem do arquiteto. Antes de tocar no código, ele decompõe recursos em estrutura, design de UI e limites de sistema. Na tarefa de caça a bugs, o M2.5 documentou cada correção com comentários embutidos e preservou todos os contratos de API originais, atingindo 28/30 contra 24,5/30 do GLM 5. O porém: o M2.5 concluiu todos os testes em 21 minutos contra 44 minutos do GLM 5, mas produziu um bug crítico de autorização no endpoint de anexos que o teste abrangente do GLM 5 teria detectado.

Teste Da Kilo Code
Ponto-Chave: Os loops de autorreflexão do GLM 5 brilham quando você está construindo do zero e precisa de código à prova de falhas. O planejamento prévio do M2.5 domina quando se trabalha com bases de código legadas, onde alterações mínimas e documentação clara importam mais que arquitetura perfeita. Desenvolvedores reais relatam que o M2.5 requer mais supervisão, mas termina mais rápido, enquanto o GLM 5 se alinha melhor com a intenção, ao custo de limites de taxa ocasionais. O GLM 5 constrói mais e testa mais. O MiniMax M2.5 altera menos e termina mais rápido.
https://www.youtube.com/watch?v=t94H-DkFIys
Teste o GLM 5 e o MiniMax M2.5 Agora!
Desempenho Agêncial do MiniMax M2.5 e do GLM 5
O GLM 5 domina os benchmarks de chamada de ferramentas. Ele atinge 67,8% no MCP-Atlas (Conjunto Público), 38% no Tool-Decathlon e 89,7% no τ²-Bench. Esses não são testes genéricos de chamada de funções; eles medem se um agente pode encadear 5 a 10 invocações de ferramentas para resolver tarefas de pesquisa reais.
A vantagem do M2.5 aparece na eficiência de decisão. Nos testes BrowseComp, Wide Search e RISE, o M2.5 alcança melhores resultados usando 20% menos rodadas de busca que o M2.1. Ele aprendeu a resolver problemas com consultas mais precisas em vez de exploração exaustiva. Essa eficiência se compõe em produção: quando seu agente executa 1.000 tarefas de pesquisa por dia, a eficiência de tokens do M2.5 reduz os custos em 20% antes mesmo de você considerar seu preço de API mais baixo.
| Benchmark de Agentes | GLM 5 | MiniMax M2.5 | Cenário de Teste |
|---|---|---|---|
| BrowseComp (com Gerenciamento de Contexto) | 75,9% | 75,1%~76,3% | Navegação real com estratégia de descarte de histórico |
| RISE (Interno) | Não divulgado | 50,2% | Tarefas de pesquisa profissional |
| BFCL | Não divulgado | 76,8% | |
| τ²-Bench | 89,7% | Não divulgado | Seleção e sequenciamento de ferramentas |
| MCP-Atlas (Conjunto Público) | 67,8% | Não divulgado | Tarefas de integração com servidores MCP |
Análise de Custos do MiniMax M2.5 e do GLM 5
Os $0,30 de entrada / $1,20 de saída por 1M de tokens do M2.5 são 70% mais baratos que os $1,00 de entrada / $3,20 de saída estimados do GLM 5 na entrada, e 62,5% mais baratos na saída. Executar o M2.5 continuamente custa $1/hora ($8.760/ano). A precificação do GLM 5 coloca a operação contínua em cerca de $2,80/hora ($24.528/ano) — 2,8x mais para o mesmo tempo de atividade.
| Cenário de Custo | GLM 5 | MiniMax M2.5 | MiniMax M2.5 Alta Velocidade |
|---|---|---|---|
| Precificação de API (1M de tokens) | $1,00 entrada / $3,20 saída | $0,30 entrada / $1,20 saída | $0,60 entrada / $2,4 saída |
| Leitura de Cache | $0,2 /Mt | $0,03 /Mt | $0,03 /Mt |
| Uso Diário do OpenClaw (500K entrada / 100K saída) | $0,82/dia | $0,27/dia | $0,54/dia |
A Leitura de Cache refere-se ao custo de leitura de tokens que foram armazenados anteriormente no cache de prompts. Quando o mesmo conteúdo de prompt é reutilizado em várias solicitações, o modelo recupera esses tokens diretamente do cache em vez de processá-los novamente do zero. Isso reduz tanto a latência de inferência quanto o custo.
Teste o GLM 5 e o MiniMax M2.5 Agora!
Recomendações de Casos de Uso do MiniMax M2.5 e do GLM 5
Escolha o MiniMax M2.5 quando a dominância de velocidade e custo importa mais que a flexibilidade arquitetônica. Agentes voltados para o cliente que exigem respostas em menos de um segundo em escala — chatbots que lidam com mais de 10 mil conversas por dia, conclusão de código em equipes de desenvolvedores, geração automatizada de documentação — todos se beneficiam da alta taxa de transferência do M2.5 e do custo de API 3x menor.
Escolha o GLM 5 quando a profundidade arquitetônica e as necessidades de personalização superam as restrições de custo. Ambientes de pesquisa que exigem contexto de base de código completo, sessões de depuração de várias horas ou integração com pilhas de ferramentas personalizadas favorecem a janela de contexto de 200K do GLM 5 e sua dominância nos benchmarks MCP-Atlas/Tool-Decathlon. A escala de 754B de parâmetros com atenção esparsa DeepSeek mantém a coerência em tarefas de engenharia de sistemas complexos que fariam o M2.5 perder o contexto no meio da sessão.
| Categoria de Caso de Uso | GLM 5 | MiniMax M2.5 | Fator Decisório |
|---|---|---|---|
| Agentes Voltados para o Cliente | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Preço de API barato |
| Engenharia de Sistemas Complexos | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | 200K de contexto + DSA para sessões de várias horas |
| Automação de Alto Volume (mais de 10K tarefas/dia) | ⭐⭐ | ⭐⭐⭐⭐⭐ | API 3x mais barata = 3x mais tarefas por dólar |
| Desenvolvimento Exploratório | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Tempo de tarefa de 21 min do M2.5 contra 44 min do GLM 5 no teste da Kilo |
| Integração com Pilha de Ferramentas Personalizada | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | 67,8% no MCP-Atlas, 89,7% no τ²-Bench |
| Manutenção de Base de Código Multilíngue | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | 73,3% contra 51,3% no SWE-bench Multilingual |
| Produtividade de Escritório (Word/Excel/PPT) | ⭐⭐ | ⭐⭐⭐⭐⭐ | Taxa de vitória de 59% contra modelos mainstream (GDPval-MM) |
Teste o GLM 5 e o MiniMax M2.5 Agora!
Como Acessar Ambos os Modelos via Novita AI?
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Biblioteca de Modelos.

Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.

Passo 3: Inicie Seu Teste Gratuito
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.
Teste o GLM 5 e o MiniMax M2.5 Agora!
Passo 4: Obtenha Sua Chave de API
Para autenticar com a API, forneceremos uma nova chave de API. Na página “Configurações”, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico da sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias para seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de conclusões de chat para usuários de Python.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-5 or minimax/minimax-m2.5",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
A Pergunta Única: Você precisa de personalização ou apenas de desempenho? Se seu fluxo de trabalho exige fine-tuning, auto-hospedagem ou integração com pilhas de ferramentas proprietárias → a flexibilidade arquitetônica e a licença MIT do GLM 5 justificam o premium. Se você está lançando agentes que precisam escalar para milhões de invocações sem restrições de orçamento → a inteligência de baixo custo do M2.5 se torna sua vantagem competitiva. O cenário de modelos abertos chineses acabou de forçar todos os concorrentes a recalibrar o que “IA acessível” significa em 2026.
Perguntas Frequentes
Qual modelo é melhor para tarefas de codificação, MiniMax M2.5 ou GLM 5?
O MiniMax M2.5 tem melhor desempenho em tarefas de codificação, com 80,2% no SWE-bench Verified, superando levemente o GLM 5.
Qual modelo é melhor para fluxos de trabalho agênciais, MiniMax M2.5 ou GLM 5?
O GLM 5 tem melhor desempenho em fluxos de trabalho agênciais complexos, com resultados mais fortes no HLE com ferramentas e Terminal-Bench que o MiniMax M2.5.
O MiniMax M2.5 e o GLM 5 podem ser executados em GPUs de consumo?
Tanto o MiniMax M2.5 quanto o GLM 5 exigem grande quantidade de VRAM e são normalmente acessados via APIs em vez de GPUs de consumo.
Novita AI é uma plataforma de nuvem de IA e agentes que ajuda desenvolvedores e startups a construir, implantar e escalar modelos e aplicações agênciais com alta performance, confiabilidade e eficiência de custos.
Leitura Recomendada



