

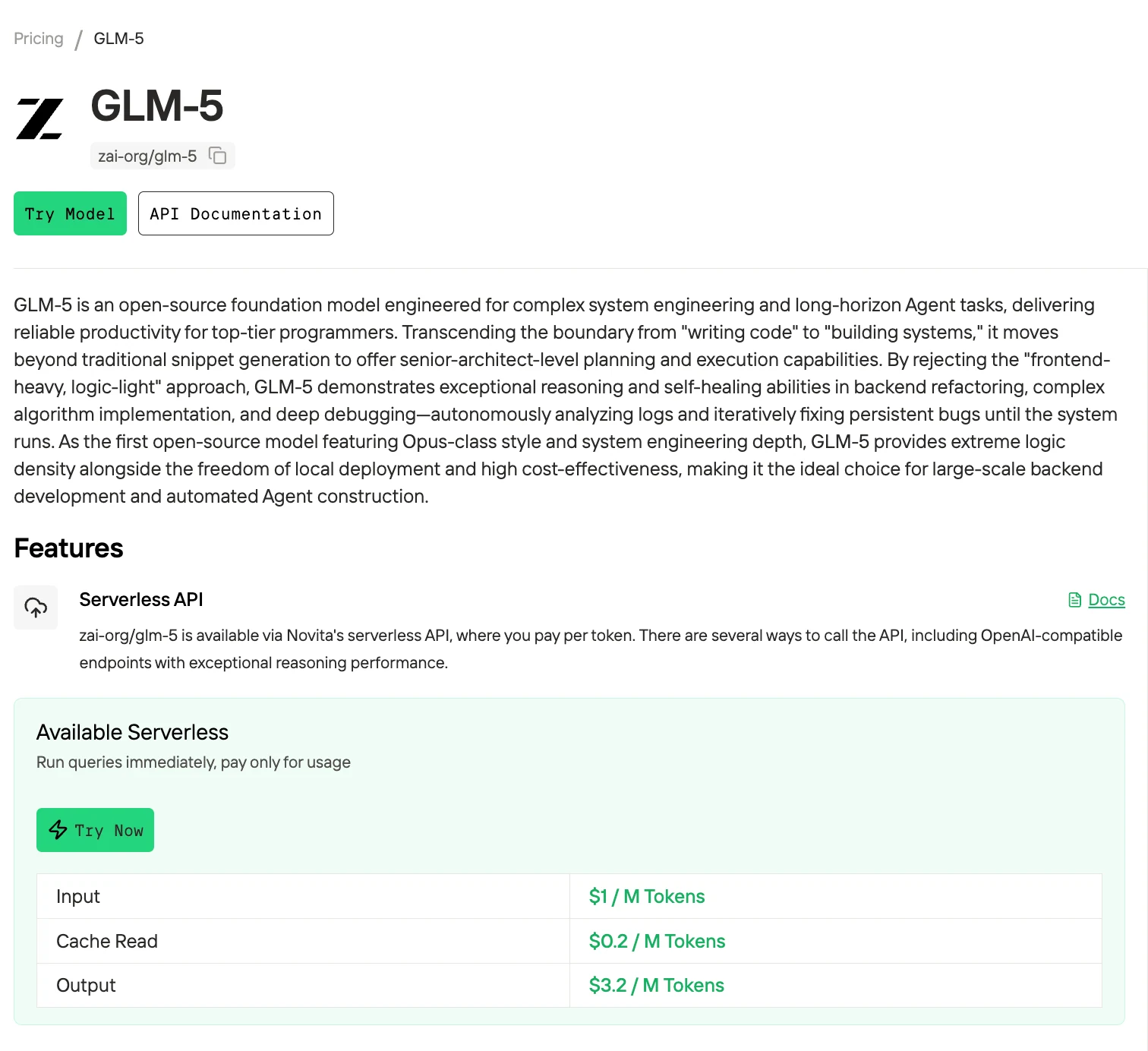
MiniMax M2.5は、GLM 5のSWE-bench Verifiedスコア77.8%に対し80.2%と同等の結果を達成し、Novita AI でのAPIコストは3分の1です。 2026年2月に24時間以内にリリースされたこれら2つの中国製MoEモデルは、AIエージェントに対して異なるアプローチを採用しています。GLM 5はパラメータ数754B(アクティブ40B)までスケールし、複雑なシステムエンジニアリングをターゲットに、200KのコンテキストウィンドウとDeepSeekスパースアテンションを備えています。MiniMax M2.5は合計228.7Bパラメータで仕様記述能力を持ち、20万以上の実世界RL環境でトレーニングされています。選択は、長時間のデバッグセッションにGLM 5のアーキテクチャの深さが必要か、高ボリュームのエージェントパイプラインにM2.5の低コストが適しているかによって決まります。
MiniMax M2.5とGLM 5のモデル概要
GLM 5の754BパラメータMoEアーキテクチャは、推論ごとに40Bのパラメータをアクティブにし、M2.5の合計228.7Bの3.2倍のサイズです。この差は、すべてのパフォーマンス次元に波及する明確な設計思想を明らかにしています。
| アーキテクチャコンポーネント | GLM 5 | MiniMax M2.5 |
|---|---|---|
| 総パラメータ数 | 754B(アクティブ40B) | 229B |
| エキスパートアーキテクチャ | 256ルーティングエキスパート、Top-8、1共有エキスパート | 256ローカルエキスパート、Top-8選択 |
| アテンションメカニズム | DeepSeekスパースアテンション(DSA) | 標準アテンション |
| 隠れ層 | 78層、隠れサイズ6144 | 62層、隠れサイズ3072 |
| コンテキストウィンドウ | 202,752トークン(200K) | 196,608トークン(197K) |
| トレーニングデータ | 28.5Tトークン | 非公開 |
| RLフレームワーク | Slime(非同期RL) | Forge(エージェントネイティブRL、20万以上の環境) |
DeepSeekスパースアテンションはGLM 5の主要なアーキテクチャ機能です。これにより、長いコンテキストでも高いパフォーマンスを維持し、デプロイメントコストを削減します。202Kと197Kのコンテキスト差は紙面上では小さく見えますが、GLM 5のDSAは二次メモリスケーリングなしでその全ウィンドウにわたって一貫性を維持します。MiniMax M2.5は、生のコンテキスト容量ではなく、タスク分解の効率性でそれを補っています。
kaitchup によるDSAの紹介
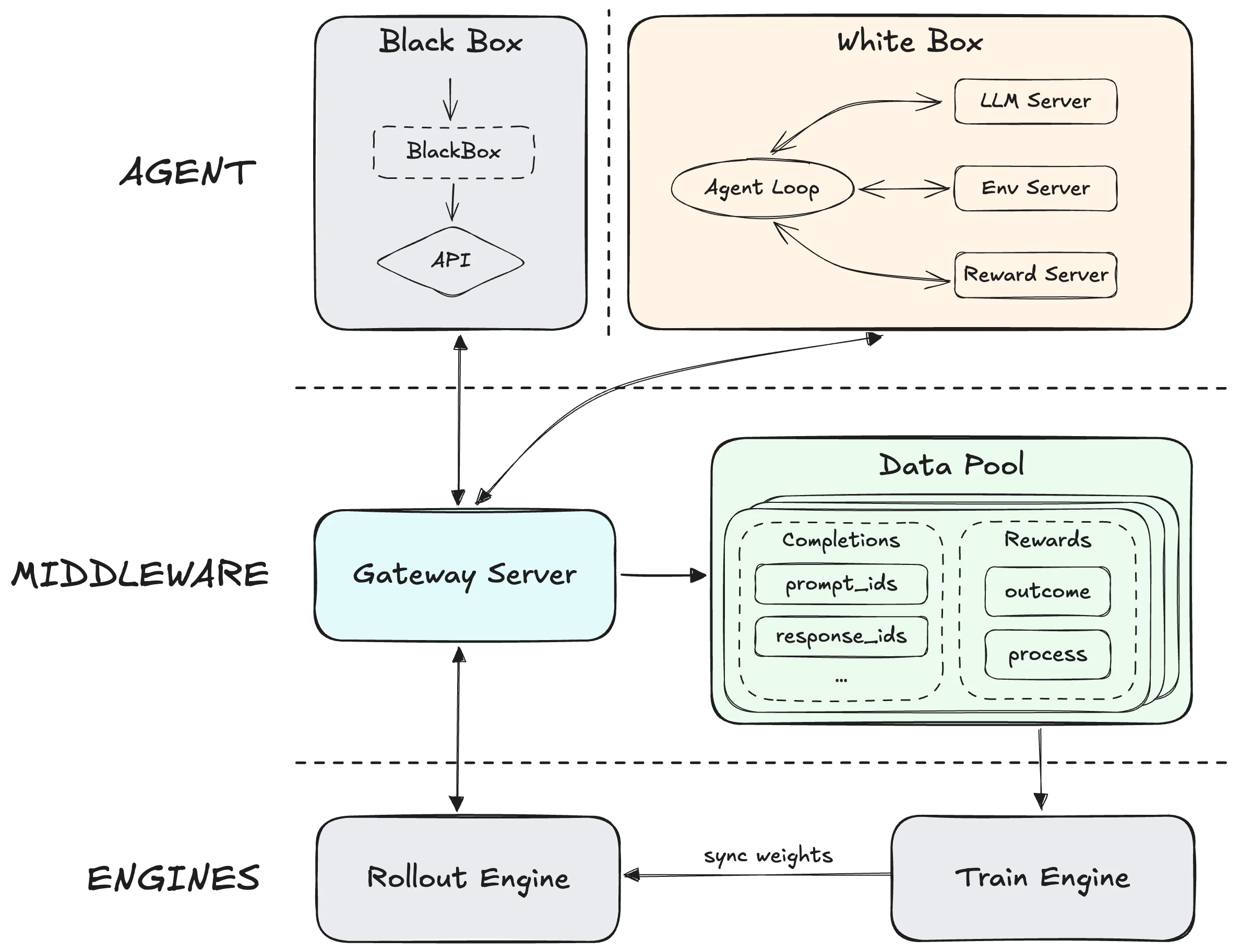
MiniMax によるForgeの紹介
RLトレーニングのギャップはより深いストーリーを物語っています。GLM 5のSlimeフレームワークは前代未聞の規模で非同期RLを可能にし、プレトレーニングとポストトレーニングの両方の限界を同時に押し広げます。MiniMaxのForgeフレームワークはトレーニングエンジンをエージェントから完全に分離し、単一タスクの習熟ではなくスキャフォールド間での汎化を最適化します。選択は、あらゆる入力に対応できるようにトレーニングされたモデル(GLM 5)か、エージェントが実際に直面する環境(M2.5の20万以上の実世界トレーニングシナリオ)でトレーニングされたモデルかの違いです。
MiniMax M2.5とGLM 5のコーディング対決
M2.5のSWE-bench Verifiedスコア80.2%はGLM 5の77.8%をわずかに上回り、両者ともClaude Opus 4.6の80.9%に迫っています。
| コーディングベンチマーク | GLM 5 | MiniMax M2.5 | 測定内容 |
|---|---|---|---|
| SWE-bench Verified | 77.8% | 80.2% | 実際のGitHub PR解決 |
| SWE-bench Multilingual | 73.3% | 74.1% | 言語横断的なバグ修正 |
| Terminal-Bench 2.0 | 56.2% | 51.7% | CLI環境操作 |
この差は、同様のスコアを達成する方法に現れています。Kilo AIの管理されたテストでパターンが明らかになりました。GLM 5はエージェントエンジニアリング、すなわちコンパイラエラーを自己反省し、テストが通るまでリファクタリングする反復的なデバッグサイクルに優れています。API仕様からのテストでは、94件のテストケースを作成し、再利用可能なミドルウェアを作成し、標準的なデータベースパターンを使用して満点の35/35を獲得しました。3回の自律実行でバグはゼロでした。
M2.5は仕様記述、つまりアーキテクトのアプローチで勝っています。コードに触れる前に、機能を構造、UIデザイン、システム境界に分解します。バグハントタスクでは、M2.5はすべての修正にインラインコメントを付け、元のAPI契約をすべて維持し、28/30のスコアを獲得しました(GLM 5は24.5/30)。ただし、M2.5はすべてのテストを21分で完了したのに対し、GLM 5は44分かかりましたが、添付ファイルエンドポイントに重大な認証バグを発生させており、GLM 5の包括的なテストなら気付いたでしょう。

Kilo Code によるテスト
重要なポイント: GLM 5の自己反省ループは、ゼロから構築し堅牢なコードが必要な場合に輝きます。M2.5の事前計画は、最小限の変更と明確なドキュメントが完全なアーキテクチャよりも重要なレガシーコードベースで優位に立ちます。実際の開発者は、M2.5はより多くの監視が必要ですがより早く終了し、GLM 5は意図に沿った結果を出しますが、時折レート制限が発生すると報告しています。GLM 5はより多く構築し、より多くテストします。MiniMax M2.5は変更が少なく、より早く終了します。
https://www.youtube.com/watch?v=t94H-DkFIys
MiniMax M2.5とGLM 5のエージェント性能
GLM 5はツール呼び出しベンチマークで圧倒しています。MCP-Atlas(Public Set)で67.8%、Tool-Decathlonで38%、τ²-Benchで89.7%を達成しています。これらは単なる汎用関数呼び出しテストではなく、エージェントが5〜10回のツール呼び出しを連鎖させて実際のリサーチタスクを解決できるかどうかを測定します。
M2.5の強みは意思決定の効率性に現れています。BrowseComp、Wide Search、RISE全体で、M2.5はM2.1よりも20%少ない検索ラウンドでより良い結果を達成しました。網羅的な探索ではなく、より正確なクエリで問題を解決することを学習したのです。この効率性は本番環境で増幅されます。エージェントが1日あたり1,000件のリサーチタスクを実行する場合、M2.5のトークン効率は、低いAPI価格を考慮する前からコストを20%削減します。
| エージェントベンチマーク | GLM 5 | MiniMax M2.5 | テストシナリオ |
|---|---|---|---|
| BrowseComp(コンテキスト管理あり) | 75.9% | 75.1%~76.3% | 履歴破棄戦略を用いた実際のブラウジング |
| RISE(内部) | 非公開 | 50.2% | プロフェッショナルなリサーチタスク |
| BFCL | 非公開 | 76.8% | |
| τ²-Bench | 89.7% | 非公開 | ツール選択と順序付け |
| MCP-Atlas(Public Set) | 67.8% | 非公開 | MCPサーバー統合タスク |
MiniMax M2.5とGLM 5のコスト分析
M2.5の入力100万トークンあたり$0.30、出力$1.20という価格は、GLM 5の推定$1.00(入力)/ $3.20(出力)を、入力で70%、出力で62.5%下回ります。M2.5を継続的に実行すると、1時間あたり$1(年間$8,760)です。GLM 5の価格では、継続運用は1時間あたり約$2.80(年間$24,528)となり、同等の稼働時間で2.8倍のコストです。
| コストシナリオ | GLM 5 | MiniMax M2.5 | MiniMax M2.5 Highspeed |
|---|---|---|---|
| API価格(100万トークン) | $1.00 in / $3.20 out | $0.30 in / $1.20 out | $0.60 in / $2.4 out |
| キャッシュ読み取り | $0.2 /Mt | $0.03 /Mt | $0.03 /Mt |
| OpenClawの1日あたりの使用量(500K in / 100K out) | $0.82/日 | $0.27/日 | $0.54/日 |
キャッシュ読み取りとは、以前にプロンプトキャッシュに保存されたトークンを読み取るコストを指します。同じプロンプトコンテンツがリクエスト間で再利用される場合、モデルはこれらのトークンをキャッシュから直接取得し、ゼロから再処理する必要がありません。これにより推論のレイテンシとコストが削減されます。
MiniMax M2.5とGLM 5のユースケース推奨
MiniMax M2.5を選ぶべきケース: 速度とコストの優位性がアーキテクチャの柔軟性よりも重要な場合。1日1万回以上の会話を処理するチャットボット、開発者チーム向けのコード補完、自動ドキュメント生成など、大規模な顧客向けエージェントは、M2.5の高スループットと3倍低いAPIコストの恩恵を受けます。
GLM 5を選ぶべきケース: アーキテクチャの深さとカスタマイズのニーズがコスト制約を上回る場合。コードベース全体のコンテキストが必要な研究環境、長時間のデバッグセッション、カスタムツールスタックとの統合には、GLM 5の200KコンテキストウィンドウとMCP-Atlas/Tool-Decathlonでの優位性が適しています。DeepSeekスパースアテンションを備えた754Bパラメータの規模は、M2.5ではセッション中にコンテキストを失う可能性のある複雑なシステムエンジニアリングタスク全体で一貫性を維持します。
| ユースケースカテゴリ | GLM 5 | MiniMax M2.5 | 決定要因 |
|---|---|---|---|
| 顧客向けエージェント | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 安いAPI価格 |
| 複雑なシステムエンジニアリング | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | 200Kコンテキスト + DSAによる長時間セッション |
| 高ボリューム自動化(1日1万タスク以上) | ⭐⭐ | ⭐⭐⭐⭐⭐ | 3倍安いAPI = 1ドルあたり3倍のタスク |
| 探索的開発 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | kiloテストでM2.5のタスク完了時間21分 vs GLM 5の44分 |
| カスタムツールスタック統合 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | 67.8% MCP-Atlas、89.7% τ²-Bench |
| 多言語コードベースメンテナンス | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | 73.3% vs 51.3% SWE-bench Multilingual |
| オフィス生産性(Word/Excel/PPT) | ⭐⭐ | ⭐⭐⭐⭐⭐ | GDPval-MMで主流モデルに対して59%の勝率 |
Novita AIで両方のモデルにアクセスする方法
ステップ1:ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリボタンをクリックします。

ステップ2:モデルを選択
利用可能なオプションから、ニーズに合ったモデルを選択します。

ステップ3:無料トライアルを開始
無料トライアルを開始して、選択したモデルの機能を試してみましょう。
ステップ4:APIキーを取得
APIで認証するために、新しいAPIキーを提供します。「設定」ページに移動し、画像のようにAPIキーをコピーします。

ステップ5:APIをインストール
お使いのプログラミング言語に固有のパッケージマネージャーを使用してAPIをインストールします。
インストール後、必要なライブラリを開発環境にインポートします。APIキーを使用してAPIを初期化し、Novita AI LLMとのやり取りを開始します。以下は、Pythonユーザー向けのチャット完了APIの使用例です。
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-5 or minimax/minimax-m2.5",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
1つの質問テスト: カスタマイズが必要ですか、それともパフォーマンスだけですか?ワークフローにファインチューニング、セルフホスティング、またはプロプライエタリなツールスタックとの統合が必要な場合 → GLM 5のアーキテクチャの柔軟性とMITライセンスがプレミアムを正当化します。数百万回の呼び出しにスケールするエージェントを予算制約なしに出荷する場合 → M2.5の低コストなインテリジェンスがあなたの堀になります。中国のオープンモデル環境は、競合他社すべてに2026年の「手頃なAI」の意味を再調整することを強いました。
よくある質問
コーディングタスクではMiniMax M2.5とGLM 5のどちらが優れていますか?
MiniMax M2.5はSWE-bench Verifiedで80.2%とわずかに優れており、コーディングタスクにおいてGLM 5を上回ります。
エージェントワークフローではMiniMax M2.5とGLM 5のどちらが優れていますか?
GLM 5は複雑なエージェントワークフローにおいて、HLE with toolsやTerminal-BenchでMiniMax M2.5よりも優れた結果を示しています。
MiniMax M2.5とGLM 5はコンシューマーGPUで実行できますか?
MiniMax M2.5とGLM 5はどちらも大容量のVRAMを必要とし、通常はコンシューマーGPUではなくAPIを介してアクセスされます。
Novita AI は、開発者やスタートアップが高性能、信頼性、コスト効率の高いモデルとエージェントアプリケーションを構築、デプロイ、スケールできるAI&エージェントクラウドプラットフォームです。
おすすめの記事



