

MiniMax M2.5 iguala el 77.8% de GLM 5 en SWE-bench Verified con un 80.2% — con un costo de API un tercio inferior en Novita AI. Lanzados con 24 horas de diferencia en febrero de 2026, estos dos modelos chinos MoE adoptan enfoques distintos para los agentes de IA. GLM 5 escala hasta 754B parámetros con 40B activos, enfocándose en ingeniería de sistemas complejos con una ventana de contexto de 200K y atención dispersa DeepSeek. MiniMax M2.5 mantiene un total de 228.7B parámetros con capacidades de redacción de especificaciones, entrenado en 200.000 entornos RL del mundo real. La elección se reduce a si necesitas la profundidad arquitectónica de GLM 5 para sesiones de depuración de varias horas o el bajo costo de M2.5 para pipelines de agentes de alto volumen.
Resumen de modelos de MiniMax M2.5 y GLM 5
La arquitectura MoE de 754B parámetros de GLM 5 activa 40B parámetros por inferencia, siendo 3.2 veces más grande que los 228.7B totales de M2.5. Esta brecha revela filosofías de diseño distintas que se extienden por cada dimensión de rendimiento.
| Componente de arquitectura | GLM 5 | MiniMax M2.5 |
|---|---|---|
| Parámetros totales | 754B (40B activos) | 229B |
| Arquitectura de expertos | 256 expertos enrutados, Top-8, 1 experto compartido | 256 expertos locales, selección Top-8 |
| Mecanismo de atención | Atención dispersa DeepSeek (DSA) | Atención estándar |
| Capas ocultas | 78 capas, tamaño oculto 6144 | 62 capas, tamaño oculto 3072 |
| Ventana de contexto | 202,752 tokens (200K) | 196,608 tokens (197K) |
| Datos de entrenamiento | 28.5T tokens | No divulgado |
| Marco RL | Slime (RL asíncrono) | Forge (RL nativo para agentes, 200K+ entornos) |
La atención dispersa DeepSeek (DSA) es la característica arquitectónica clave de GLM 5. Mantiene un alto rendimiento en contextos largos al tiempo que reduce los costos de despliegue. La diferencia de 202K vs 197K de contexto parece pequeña en papel, pero el DSA de GLM 5 mantiene la coherencia en toda esa ventana sin escalar la memoria de forma cuadrática. MiniMax M2.5 compensa con eficiencia en la descomposición de tareas en lugar de capacidad de contexto bruta.
Introducción a DSA por kaitchup
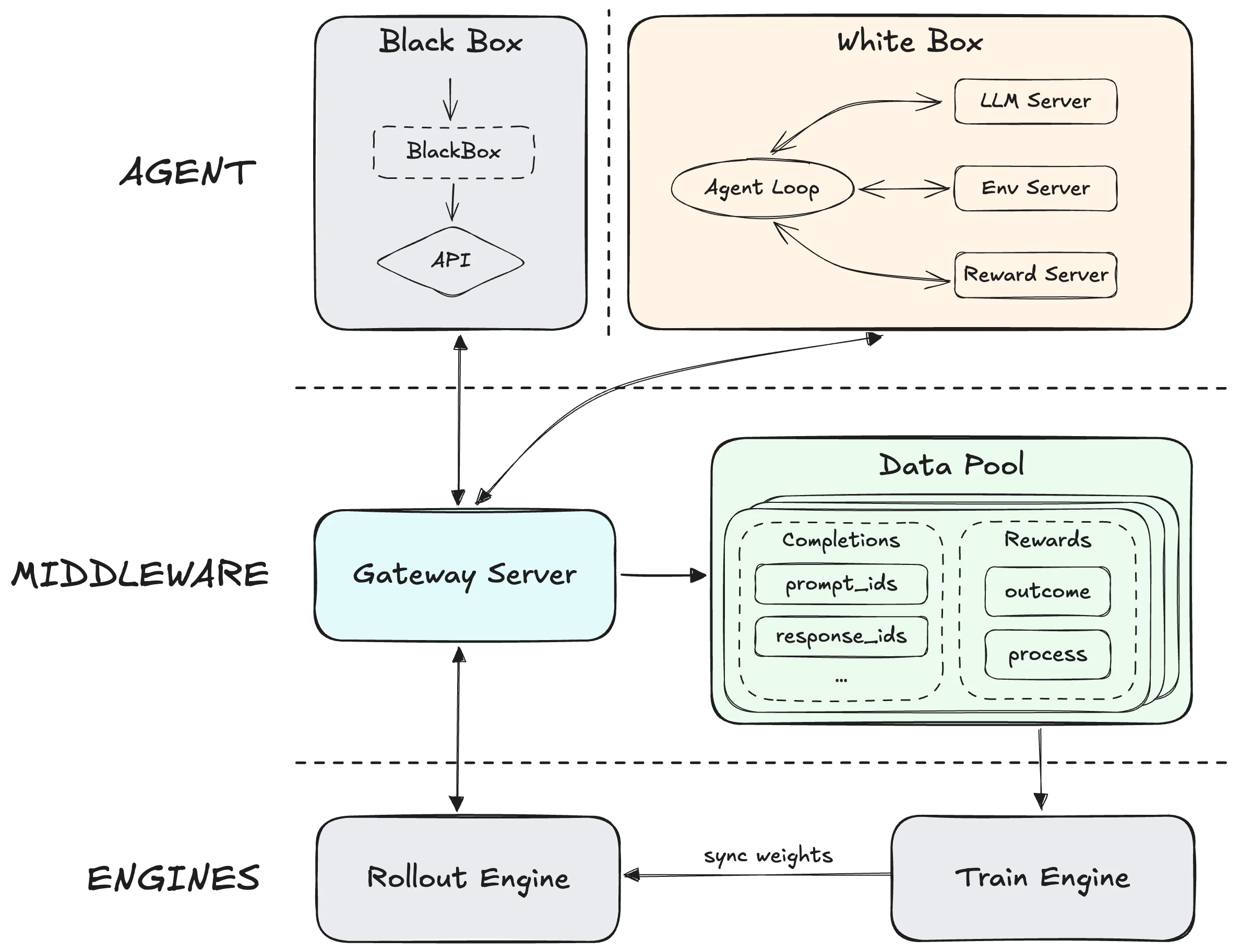
Introducción a Forge por MiniMax
La brecha en el entrenamiento RL cuenta una historia más profunda. El marco Slime de GLM 5 permite RL asíncrono a una escala sin precedentes, empujando los límites del preentrenamiento y el post-entrenamiento simultáneamente. El marco Forge de MiniMax desacopla completamente el motor de entrenamiento de los agentes, optimizando para la generalización a través de scaffolds en lugar del dominio de una sola tarea. Estás eligiendo entre un modelo entrenado para manejar todo lo que se le presente (GLM 5) versus uno entrenado en los entornos exactos que tus agentes enfrentarán (los 200K+ escenarios de entrenamiento del mundo real de M2.5).
¡Prueba GLM 5 y MiniMax M2.5 ahora!
Batalla directa de codificación: MiniMax M2.5 vs GLM 5
El 80.2% de M2.5 en SWE-bench Verified supera el 77.8% de GLM 5, colocando a ambos a la altura del 80.9% de Claude Opus 4.6.
| Benchmark de codificación | GLM 5 | MiniMax M2.5 | Qué mide |
|---|---|---|---|
| SWE-bench Verified | 77.8% | 80.2% | Resolución real de PRs en GitHub |
| SWE-bench Multilingual | 73.3% | 74.1% | Corrección de errores multilingüe |
| Terminal-Bench 2.0 | 56.2% | 51.7% | Manipulación de entornos CLI |
La diferencia surge en cómo logran puntuaciones similares. Las pruebas controladas de Kilo AI revelan el patrón: GLM 5 destaca en ingeniería agéntica — ciclos iterativos de depuración donde el modelo reflexiona sobre errores del compilador y refactoriza hasta que las pruebas pasan. Obtuvo un perfecto 35/35 en la prueba de API a partir de especificaciones escribiendo 94 casos de prueba, creando middleware reutilizable y usando patrones de base de datos estándar. Cero errores en tres ejecuciones autónomas.
M2.5 gana en redacción de especificaciones — el enfoque del arquitecto. Antes de tocar el código, descompone las funciones en estructura, diseño de UI y límites del sistema. En la tarea de caza de errores, M2.5 documentó cada corrección con comentarios en línea y preservó todos los contratos originales de la API, obteniendo 28/30 frente a 24.5/30 de GLM 5. La contrapartida: M2.5 completó todas las pruebas en 21 minutos frente a los 44 minutos de GLM 5, pero produjo un error crítico de autorización en el endpoint de adjuntos que las pruebas exhaustivas de GLM 5 habrían detectado.

Prueba de Kilo Code
Conclusión clave: Los bucles de autorreflexión de GLM 5 brillan cuando construyes desde cero y necesitas código a prueba de balas. La planificación anticipada de M2.5 domina cuando trabajas con bases de código heredadas donde los cambios mínimos y la documentación clara importan más que la arquitectura perfecta. Desarrolladores reales reportan que M2.5 requiere más supervisión pero termina más rápido, mientras que GLM 5 se alinea mejor con la intención al costo de límites de velocidad ocasionales. GLM 5 construye más y prueba más. MiniMax M2.5 cambia menos y termina más rápido.
https://www.youtube.com/watch?v=t94H-DkFIys
¡Prueba GLM 5 y MiniMax M2.5 ahora!
Rendimiento agéntico de MiniMax M2.5 y GLM 5
GLM 5 domina los benchmarks de uso de herramientas. Obtiene 67.8% en MCP-Atlas (Conjunto público), 38% en Tool-Decathlon y 89.7% en τ²-Bench. Estas no son pruebas genéricas de llamada a funciones; miden si un agente puede encadenar 5-10 invocaciones de herramientas para resolver tareas reales de investigación.
La ventaja de M2.5 se muestra en la eficiencia de decisión. En BrowseComp, Wide Search y RISE, M2.5 logra mejores resultados usando un 20% menos de rondas de búsqueda que M2.1. Aprendió a resolver problemas con consultas más precisas en lugar de exploración exhaustiva. Esa eficiencia se acumula en producción: cuando tu agente ejecuta 1000 tareas de investigación al día, la eficiencia de tokens de M2.5 reduce los costos en un 20% antes siquiera de considerar su precio de API más bajo.
| Benchmark agéntico | GLM 5 | MiniMax M2.5 | Escenario de prueba |
|---|---|---|---|
| BrowseComp (con gestión de contexto) | 75.9% | 75.1%~76.3% | Navegación real con estrategia de descarte de historial |
| RISE (Interno) | No divulgado | 50.2% | Tareas de investigación profesional |
| BFCL | No divulgado | 76.8% | |
| τ²-Bench | 89.7% | No divulgado | Selección y secuenciación de herramientas |
| MCP-Atlas (Conjunto público) | 67.8% | No divulgado | Tareas de integración con servidores MCP |
Análisis de costos de MiniMax M2.5 y GLM 5
El precio de M2.5 ($0.30 entrada / $1.20 salida por millón de tokens) es un 70% más barato en entrada y un 62.5% en salida frente a la estimación de GLM 5 ($1.00 entrada / $3.20 salida). Ejecutar M2.5 continuamente cuesta $1/hora ($8,760/año). El precio de GLM 5 sitúa la operación continua alrededor de $2.80/hora ($24,528/año) — 2.8 veces más por una disponibilidad comparable.
| Escenario de costo | GLM 5 | MiniMax M2.5 | MiniMax M2.5 Alta velocidad |
|---|---|---|---|
| Precio API (1M tokens) | $1.00 entrada / $3.20 salida | $0.30 entrada / $1.20 salida | $0.60 entrada / $2.4 salida |
| Lectura de caché | $0.2 /Mt | $0.03 /Mt | $0.03 /Mt |
| Uso diario OpenClaw (500K entrada / 100K salida) | $0.82/día | $0.27/día | $0.54/día |
La lectura de caché se refiere al costo de leer tokens previamente almacenados en la caché de indicaciones. Cuando el mismo contenido de indicación se reutiliza entre solicitudes, el modelo recupera estos tokens directamente de la caché en lugar de procesarlos nuevamente desde cero. Esto reduce tanto la latencia de inferencia como el costo.
¡Prueba GLM 5 y MiniMax M2.5 ahora!
Recomendaciones de casos de uso de MiniMax M2.5 y GLM 5
Elige MiniMax M2.5 cuando la velocidad y el bajo costo importen más que la flexibilidad arquitectónica. Agentes orientados al cliente que requieren respuestas en subsegundos a gran escala — chatbots que manejan 10K+ conversaciones/día, finalización de código entre equipos de desarrolladores, generación automatizada de documentación — todos se benefician del alto rendimiento de M2.5 y su costo de API 3 veces menor.
Elige GLM 5 cuando la profundidad arquitectónica y las necesidades de personalización superen las restricciones de costo. Entornos de investigación que requieren contexto completo de la base de código, sesiones de depuración de varias horas o integración con pilas de herramientas personalizadas favorecen la ventana de contexto de 200K de GLM 5 y su dominio en MCP-Atlas/Tool-Decathlon. La escala de 754B parámetros con atención dispersa DeepSeek mantiene la coherencia en tareas complejas de ingeniería de sistemas que harían que M2.5 perdiera contexto a mitad de sesión.
| Categoría de caso de uso | GLM 5 | MiniMax M2.5 | Factor decisivo |
|---|---|---|---|
| Agentes orientados al cliente | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Precio API económico |
| Ingeniería de sistemas complejos | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | Contexto 200K + DSA para sesiones de varias horas |
| Automatización de alto volumen (10K+ tareas/día) | ⭐⭐ | ⭐⭐⭐⭐⭐ | API 3x más barata = 3x más tareas por dólar |
| Desarrollo exploratorio | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Tiempo de tarea de 21 min de M2.5 frente a 44 min de GLM 5 en prueba kilo |
| Integración con pilas de herramientas personalizadas | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | 67.8% MCP-Atlas, 89.7% τ²-Bench |
| Mantenimiento de bases de código multilingües | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | 73.3% vs 51.3% SWE-bench Multilingual |
| Productividad de oficina (Word/Excel/PPT) | ⭐⭐ | ⭐⭐⭐⭐⭐ | 59% de tasa de victoria frente a modelos convencionales (GDPval-MM) |
¡Prueba GLM 5 y MiniMax M2.5 ahora!
Cómo acceder a ambos modelos mediante Novita AI
Paso 1: Inicia sesión y accede a la Biblioteca de Modelos
Inicia sesión en tu cuenta y haz clic en el botón Model Library.

Paso 2: Elige tu modelo
Navega por las opciones disponibles y selecciona el modelo que se ajuste a tus necesidades.

Paso 3: Comienza tu prueba gratuita
Inicia tu prueba gratuita para explorar las capacidades del modelo seleccionado.
¡Prueba GLM 5 y MiniMax M2.5 ahora!
Paso 4: Obtén tu clave API
Para autenticarte en la API, te proporcionaremos una nueva clave API. Entra en la página de “Settings” y copia la clave API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el gestor de paquetes específico para tu lenguaje de programación.
Después de la instalación, importa las librerías necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para comenzar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de chat completions para usuarios de Python.
from openai import OpenAI
client = OpenAI(
api_key="<Tu Clave API>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-5 or minimax/minimax-m2.5",
messages=[
{"role": "system", "content": "Eres un asistente útil."},
{"role": "user", "content": "Hola, ¿cómo estás?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
La prueba de una pregunta: ¿Necesitas personalización o solo rendimiento? Si tu flujo de trabajo requiere ajuste fino, autoalojamiento o integración con pilas de herramientas propietarias → la flexibilidad arquitectónica de GLM 5 y su licencia MIT justifican la prima. Si estás lanzando agentes que necesitan escalar a millones de invocaciones sin restricciones de presupuesto → la inteligencia de bajo costo de M2.5 se convierte en tu ventaja. El panorama de modelos abiertos chinos acaba de obligar a cada competidor a recalibrar lo que significa “IA asequible” en 2026.
Preguntas frecuentes
¿Qué modelo es mejor para tareas de codificación, MiniMax M2.5 o GLM 5?
MiniMax M2.5 tiene un mejor rendimiento en tareas de codificación con un 80.2% en SWE-bench Verified, superando ligeramente a GLM 5.
¿Qué modelo es mejor para flujos de trabajo agénticos, MiniMax M2.5 o GLM 5?
GLM 5 tiene un mejor rendimiento para flujos de trabajo agénticos complejos, con resultados más sólidos en HLE con herramientas y Terminal-Bench que MiniMax M2.5.
¿Pueden MiniMax M2.5 y GLM 5 ejecutarse en GPUs de consumo?
Tanto MiniMax M2.5 como GLM 5 requieren una gran cantidad de VRAM y normalmente se accede a ellos a través de APIs en lugar de GPUs de consumo.
Novita AI es una plataforma en la nube de IA y agentes que ayuda a desarrolladores y startups a construir, desplegar y escalar modelos y aplicaciones agénticas con alto rendimiento, fiabilidad y eficiencia de costes.
Lectura recomendada



